 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLMPOcc: 3D Semantic Occupancy Prediction Utilizing Long-Term Memory Prior from Historical Traversals
Apr 18, 2025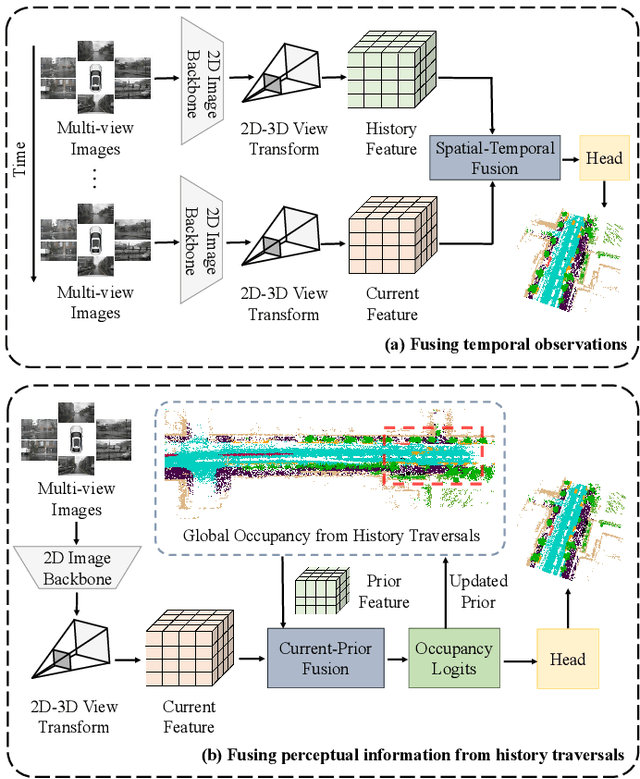
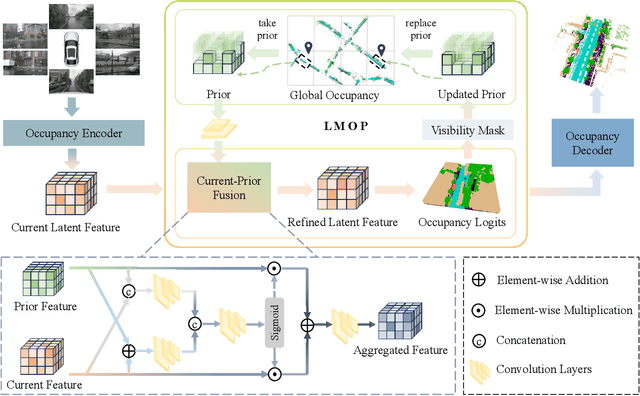
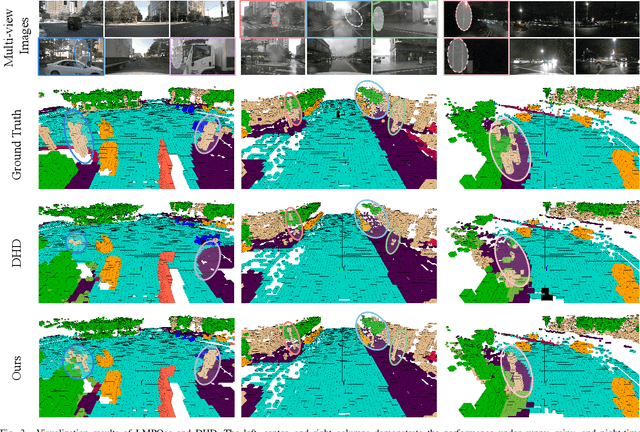
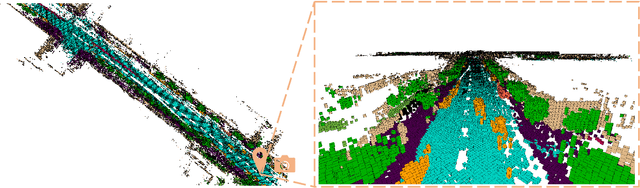
Vision-based 3D semantic occupancy prediction is critical for autonomous driving, enabling unified modeling of static infrastructure and dynamic agents. In practice, autonomous vehicles may repeatedly traverse identical geographic locations under varying environmental conditions, such as weather fluctuations and illumination changes. Existing methods in 3D occupancy prediction predominantly integrate adjacent temporal contexts. However, these works neglect to leverage perceptual information, which is acquired from historical traversals of identical geographic locations. In this paper, we propose Longterm Memory Prior Occupancy (LMPOcc), the first 3D occupancy prediction methodology that exploits long-term memory priors derived from historical traversal perceptual outputs. We introduce a plug-and-play architecture that integrates long-term memory priors to enhance local perception while simultaneously constructing global occupancy representations. To adaptively aggregate prior features and current features, we develop an efficient lightweight Current-Prior Fusion module. Moreover, we propose a model-agnostic prior format to ensure compatibility across diverse occupancy prediction baselines. LMPOcc achieves state-of-the-art performance validated on the Occ3D-nuScenes benchmark, especially on static semantic categories. Additionally, experimental results demonstrate LMPOcc's ability to construct global occupancy through multi-vehicle crowdsourcing.
OccLLaMA: An Occupancy-Language-Action Generative World Model for Autonomous Driving
Sep 05, 2024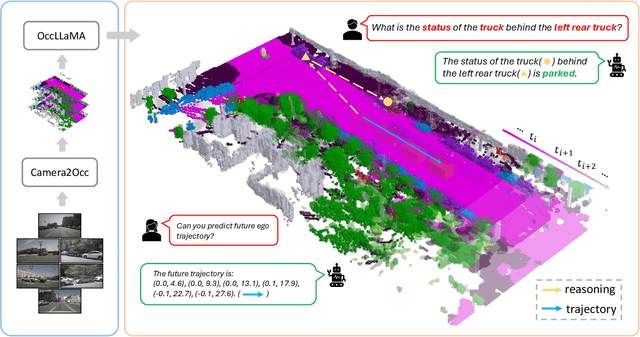

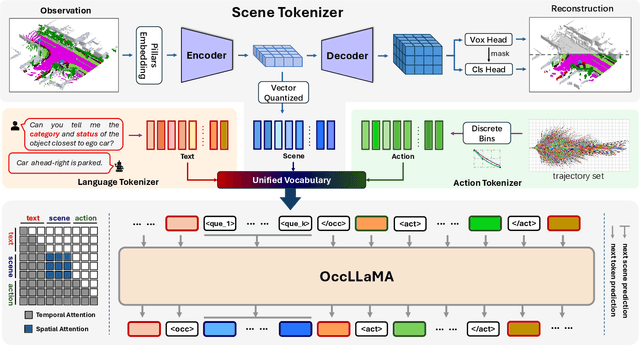
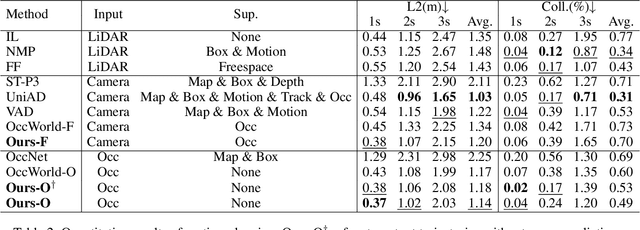
The rise of multi-modal large language models(MLLMs) has spurred their applications in autonomous driving. Recent MLLM-based methods perform action by learning a direct mapping from perception to action, neglecting the dynamics of the world and the relations between action and world dynamics. In contrast, human beings possess world model that enables them to simulate the future states based on 3D internal visual representation and plan actions accordingly. To this end, we propose OccLLaMA, an occupancy-language-action generative world model, which uses semantic occupancy as a general visual representation and unifies vision-language-action(VLA) modalities through an autoregressive model. Specifically, we introduce a novel VQVAE-like scene tokenizer to efficiently discretize and reconstruct semantic occupancy scenes, considering its sparsity and classes imbalance. Then, we build a unified multi-modal vocabulary for vision, language and action. Furthermore, we enhance LLM, specifically LLaMA, to perform the next token/scene prediction on the unified vocabulary to complete multiple tasks in autonomous driving. Extensive experiments demonstrate that OccLLaMA achieves competitive performance across multiple tasks, including 4D occupancy forecasting, motion planning, and visual question answering, showcasing its potential as a foundation model in autonomous driving.
HGS-Mapping: Online Dense Mapping Using Hybrid Gaussian Representation in Urban Scenes
Mar 29, 2024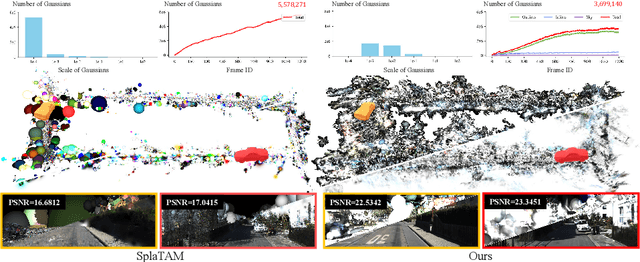
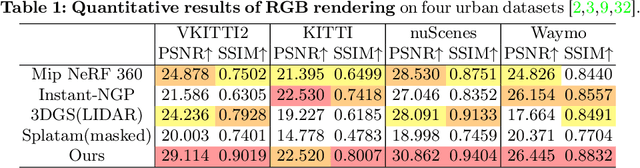
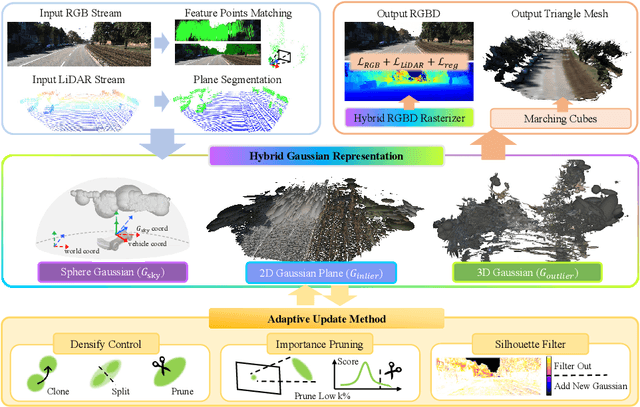
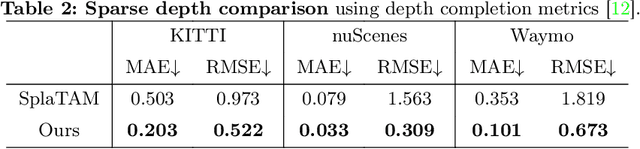
Online dense mapping of urban scenes forms a fundamental cornerstone for scene understanding and navigation of autonomous vehicles. Recent advancements in mapping methods are mainly based on NeRF, whose rendering speed is too slow to meet online requirements. 3D Gaussian Splatting (3DGS), with its rendering speed hundreds of times faster than NeRF, holds greater potential in online dense mapping. However, integrating 3DGS into a street-view dense mapping framework still faces two challenges, including incomplete reconstruction due to the absence of geometric information beyond the LiDAR coverage area and extensive computation for reconstruction in large urban scenes. To this end, we propose HGS-Mapping, an online dense mapping framework in unbounded large-scale scenes. To attain complete construction, our framework introduces Hybrid Gaussian Representation, which models different parts of the entire scene using Gaussians with distinct properties. Furthermore, we employ a hybrid Gaussian initialization mechanism and an adaptive update method to achieve high-fidelity and rapid reconstruction. To the best of our knowledge, we are the first to integrate Gaussian representation into online dense mapping of urban scenes. Our approach achieves SOTA reconstruction accuracy while only employing 66% number of Gaussians, leading to 20% faster reconstruction speed.