 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResolving State Ambiguity in Robot Manipulation via Adaptive Working Memory Recoding
Dec 31, 2025State ambiguity is common in robotic manipulation. Identical observations may correspond to multiple valid behavior trajectories. The visuomotor policy must correctly extract the appropriate types and levels of information from the history to identify the current task phase. However, naively extending the history window is computationally expensive and may cause severe overfitting. Inspired by the continuous nature of human reasoning and the recoding of working memory, we introduce PAM, a novel visuomotor Policy equipped with Adaptive working Memory. With minimal additional training cost in a two-stage manner, PAM supports a 300-frame history window while maintaining high inference speed. Specifically, a hierarchical frame feature extractor yields two distinct representations for motion primitives and temporal disambiguation. For compact representation, a context router with range-specific queries is employed to produce compact context features across multiple history lengths. And an auxiliary objective of reconstructing historical information is introduced to ensure that the context router acts as an effective bottleneck. We meticulously design 7 tasks and verify that PAM can handle multiple scenarios of state ambiguity simultaneously. With a history window of approximately 10 seconds, PAM still supports stable training and maintains inference speeds above 20Hz. Project website: https://tinda24.github.io/pam/
OccLLaMA: An Occupancy-Language-Action Generative World Model for Autonomous Driving
Sep 05, 2024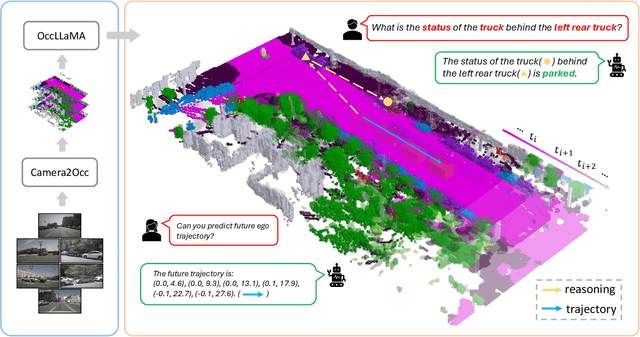

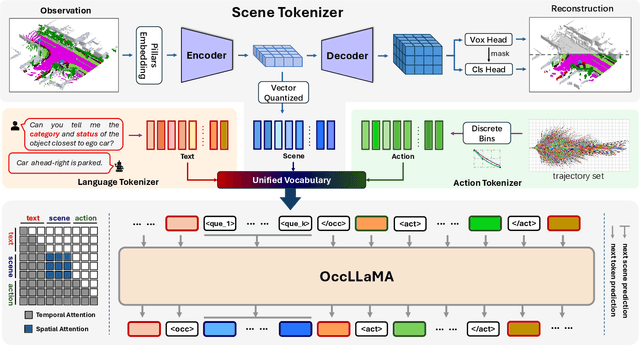
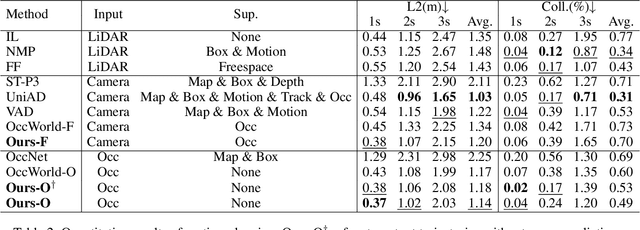
The rise of multi-modal large language models(MLLMs) has spurred their applications in autonomous driving. Recent MLLM-based methods perform action by learning a direct mapping from perception to action, neglecting the dynamics of the world and the relations between action and world dynamics. In contrast, human beings possess world model that enables them to simulate the future states based on 3D internal visual representation and plan actions accordingly. To this end, we propose OccLLaMA, an occupancy-language-action generative world model, which uses semantic occupancy as a general visual representation and unifies vision-language-action(VLA) modalities through an autoregressive model. Specifically, we introduce a novel VQVAE-like scene tokenizer to efficiently discretize and reconstruct semantic occupancy scenes, considering its sparsity and classes imbalance. Then, we build a unified multi-modal vocabulary for vision, language and action. Furthermore, we enhance LLM, specifically LLaMA, to perform the next token/scene prediction on the unified vocabulary to complete multiple tasks in autonomous driving. Extensive experiments demonstrate that OccLLaMA achieves competitive performance across multiple tasks, including 4D occupancy forecasting, motion planning, and visual question answering, showcasing its potential as a foundation model in autonomous driving.