 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResolving State Ambiguity in Robot Manipulation via Adaptive Working Memory Recoding
Dec 31, 2025State ambiguity is common in robotic manipulation. Identical observations may correspond to multiple valid behavior trajectories. The visuomotor policy must correctly extract the appropriate types and levels of information from the history to identify the current task phase. However, naively extending the history window is computationally expensive and may cause severe overfitting. Inspired by the continuous nature of human reasoning and the recoding of working memory, we introduce PAM, a novel visuomotor Policy equipped with Adaptive working Memory. With minimal additional training cost in a two-stage manner, PAM supports a 300-frame history window while maintaining high inference speed. Specifically, a hierarchical frame feature extractor yields two distinct representations for motion primitives and temporal disambiguation. For compact representation, a context router with range-specific queries is employed to produce compact context features across multiple history lengths. And an auxiliary objective of reconstructing historical information is introduced to ensure that the context router acts as an effective bottleneck. We meticulously design 7 tasks and verify that PAM can handle multiple scenarios of state ambiguity simultaneously. With a history window of approximately 10 seconds, PAM still supports stable training and maintains inference speeds above 20Hz. Project website: https://tinda24.github.io/pam/
Planning by Simulation: Motion Planning with Learning-based Parallel Scenario Prediction for Autonomous Driving
Nov 15, 2024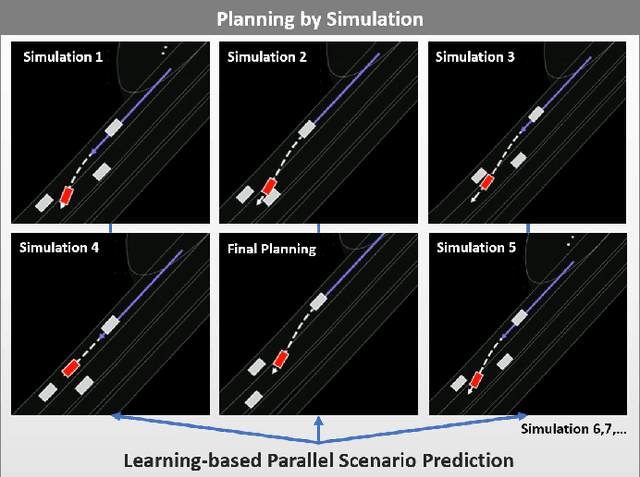
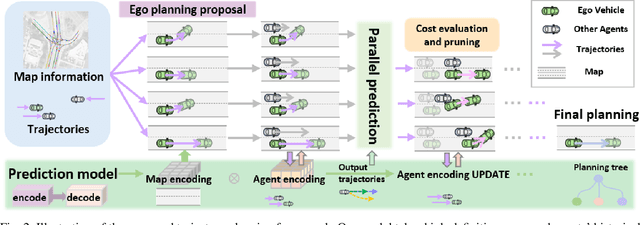
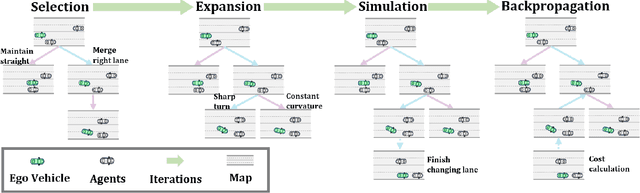
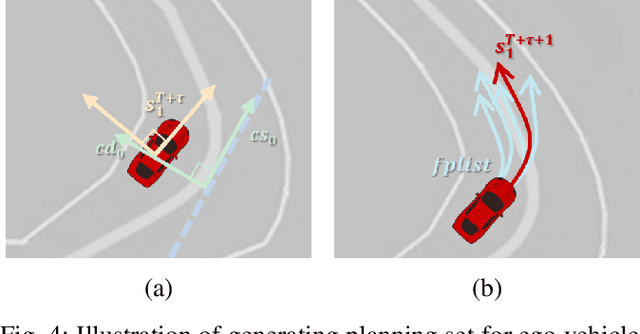
Planning safe trajectories for autonomous vehicles is essential for operational safety but remains extremely challenging due to the complex interactions among traffic participants. Recent autonomous driving frameworks have focused on improving prediction accuracy to explicitly model these interactions. However, some methods overlook the significant influence of the ego vehicle's planning on the possible trajectories of other agents, which can alter prediction accuracy and lead to unsafe planning decisions. In this paper, we propose a novel motion Planning approach by Simulation with learning-based parallel scenario prediction (PS). PS deduces predictions iteratively based on Monte Carlo Tree Search (MCTS), jointly inferring scenarios that cooperate with the ego vehicle's planning set. Our method simulates possible scenes and calculates their costs after the ego vehicle executes potential actions. To balance and prune unreasonable actions and scenarios, we adopt MCTS as the foundation to explore possible future interactions encoded within the prediction network. Moreover, the query-centric trajectory prediction streamlines our scene generation, enabling a sophisticated framework that captures the mutual influence between other agents' predictions and the ego vehicle's planning. We evaluate our framework on the Argoverse 2 dataset, and the results demonstrate that our approach effectively achieves parallel ego vehicle planning.
O2V-Mapping: Online Open-Vocabulary Mapping with Neural Implicit Representation
Apr 10, 2024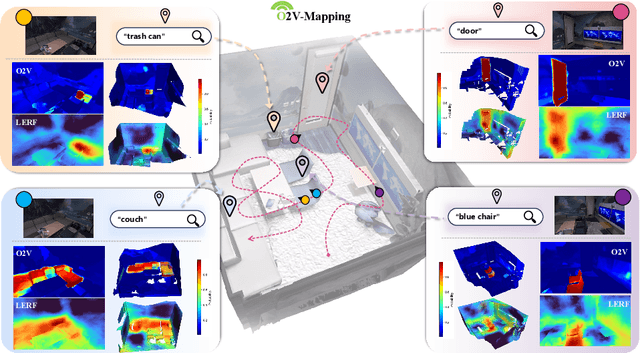
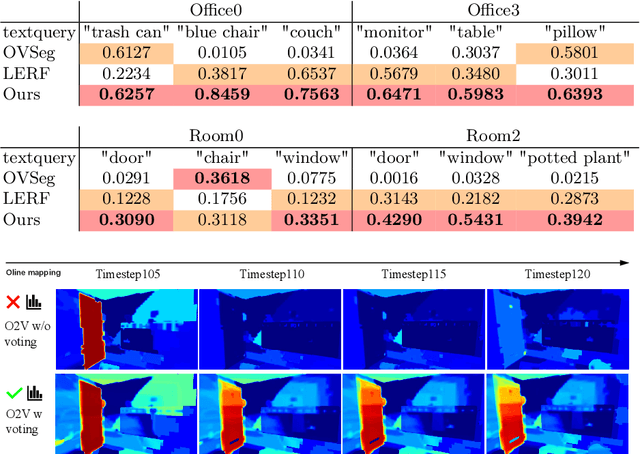
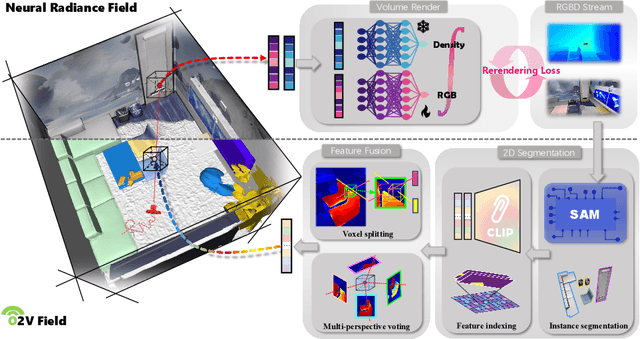
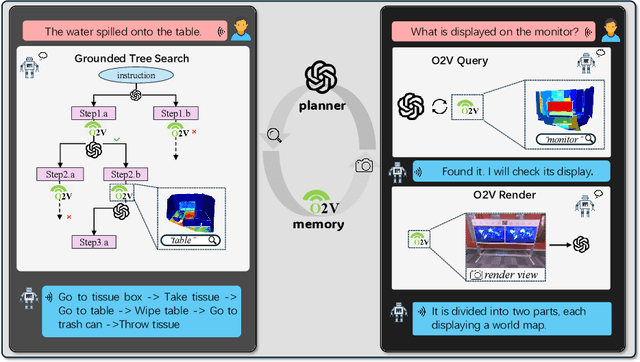
Online construction of open-ended language scenes is crucial for robotic applications, where open-vocabulary interactive scene understanding is required. Recently, neural implicit representation has provided a promising direction for online interactive mapping. However, implementing open-vocabulary scene understanding capability into online neural implicit mapping still faces three challenges: lack of local scene updating ability, blurry spatial hierarchical semantic segmentation and difficulty in maintaining multi-view consistency. To this end, we proposed O2V-mapping, which utilizes voxel-based language and geometric features to create an open-vocabulary field, thus allowing for local updates during online training process. Additionally, we leverage a foundational model for image segmentation to extract language features on object-level entities, achieving clear segmentation boundaries and hierarchical semantic features. For the purpose of preserving consistency in 3D object properties across different viewpoints, we propose a spatial adaptive voxel adjustment mechanism and a multi-view weight selection method. Extensive experiments on open-vocabulary object localization and semantic segmentation demonstrate that O2V-mapping achieves online construction of language scenes while enhancing accuracy, outperforming the previous SOTA method.
HGS-Mapping: Online Dense Mapping Using Hybrid Gaussian Representation in Urban Scenes
Mar 29, 2024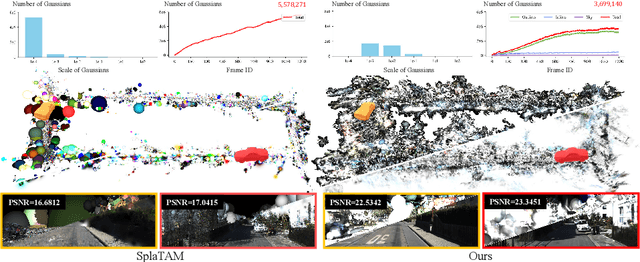
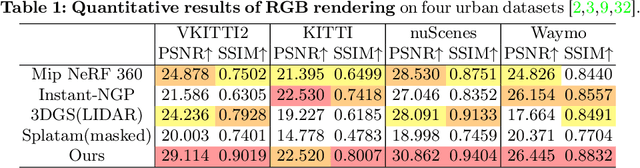
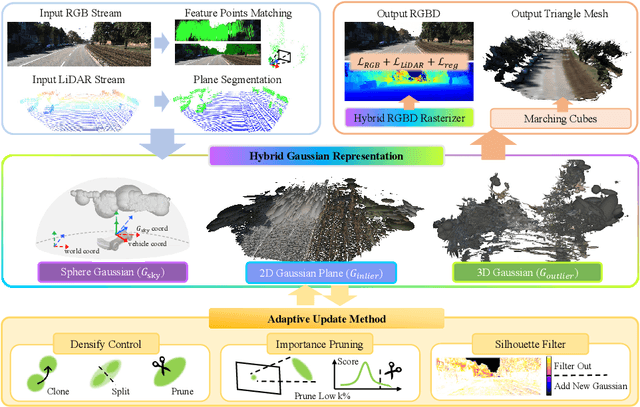
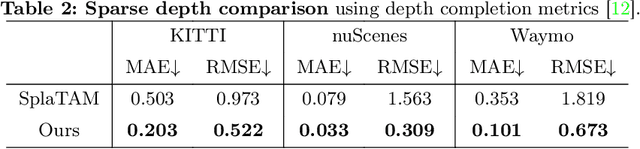
Online dense mapping of urban scenes forms a fundamental cornerstone for scene understanding and navigation of autonomous vehicles. Recent advancements in mapping methods are mainly based on NeRF, whose rendering speed is too slow to meet online requirements. 3D Gaussian Splatting (3DGS), with its rendering speed hundreds of times faster than NeRF, holds greater potential in online dense mapping. However, integrating 3DGS into a street-view dense mapping framework still faces two challenges, including incomplete reconstruction due to the absence of geometric information beyond the LiDAR coverage area and extensive computation for reconstruction in large urban scenes. To this end, we propose HGS-Mapping, an online dense mapping framework in unbounded large-scale scenes. To attain complete construction, our framework introduces Hybrid Gaussian Representation, which models different parts of the entire scene using Gaussians with distinct properties. Furthermore, we employ a hybrid Gaussian initialization mechanism and an adaptive update method to achieve high-fidelity and rapid reconstruction. To the best of our knowledge, we are the first to integrate Gaussian representation into online dense mapping of urban scenes. Our approach achieves SOTA reconstruction accuracy while only employing 66% number of Gaussians, leading to 20% faster reconstruction speed.