 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOccLLaMA: An Occupancy-Language-Action Generative World Model for Autonomous Driving
Paper and Code
Sep 05, 2024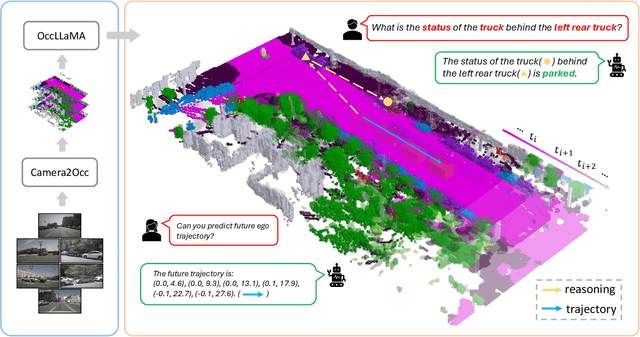

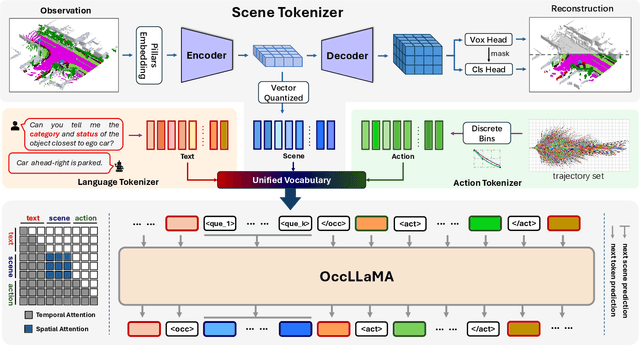
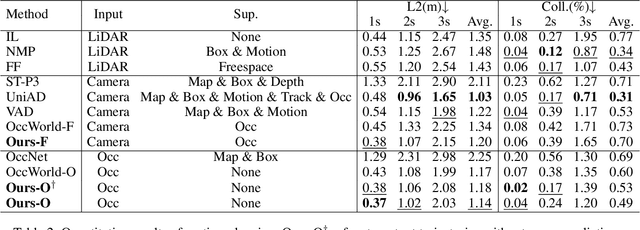
The rise of multi-modal large language models(MLLMs) has spurred their applications in autonomous driving. Recent MLLM-based methods perform action by learning a direct mapping from perception to action, neglecting the dynamics of the world and the relations between action and world dynamics. In contrast, human beings possess world model that enables them to simulate the future states based on 3D internal visual representation and plan actions accordingly. To this end, we propose OccLLaMA, an occupancy-language-action generative world model, which uses semantic occupancy as a general visual representation and unifies vision-language-action(VLA) modalities through an autoregressive model. Specifically, we introduce a novel VQVAE-like scene tokenizer to efficiently discretize and reconstruct semantic occupancy scenes, considering its sparsity and classes imbalance. Then, we build a unified multi-modal vocabulary for vision, language and action. Furthermore, we enhance LLM, specifically LLaMA, to perform the next token/scene prediction on the unified vocabulary to complete multiple tasks in autonomous driving. Extensive experiments demonstrate that OccLLaMA achieves competitive performance across multiple tasks, including 4D occupancy forecasting, motion planning, and visual question answering, showcasing its potential as a foundation model in autonomous driving.