 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADiff4TPP: Asynchronous Diffusion Models for Temporal Point Processes
Apr 29, 2025


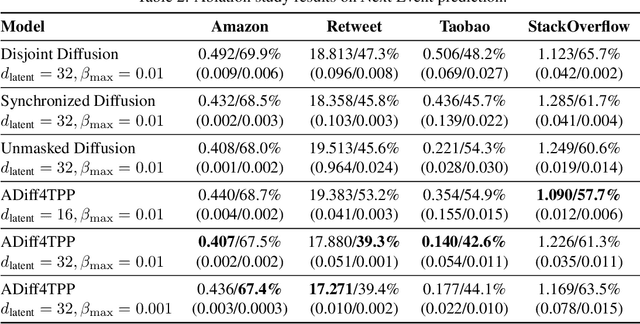
This work introduces a novel approach to modeling temporal point processes using diffusion models with an asynchronous noise schedule. At each step of the diffusion process, the noise schedule injects noise of varying scales into different parts of the data. With a careful design of the noise schedules, earlier events are generated faster than later ones, thus providing stronger conditioning for forecasting the more distant future. We derive an objective to effectively train these models for a general family of noise schedules based on conditional flow matching. Our method models the joint distribution of the latent representations of events in a sequence and achieves state-of-the-art results in predicting both the next inter-event time and event type on benchmark datasets. Additionally, it flexibly accommodates varying lengths of observation and prediction windows in different forecasting settings by adjusting the starting and ending points of the generation process. Finally, our method shows superior performance in long-horizon prediction tasks, outperforming existing baseline methods.
Pretext Training Algorithms for Event Sequence Data
Feb 16, 2024



Pretext training followed by task-specific fine-tuning has been a successful approach in vision and language domains. This paper proposes a self-supervised pretext training framework tailored to event sequence data. We introduce a novel alignment verification task that is specialized to event sequences, building on good practices in masked reconstruction and contrastive learning. Our pretext tasks unlock foundational representations that are generalizable across different down-stream tasks, including next-event prediction for temporal point process models, event sequence classification, and missing event interpolation. Experiments on popular public benchmarks demonstrate the potential of the proposed method across different tasks and data domains.
PolyDiffuse: Polygonal Shape Reconstruction via Guided Set Diffusion Models
Jun 02, 2023This paper presents PolyDiffuse, a novel structured reconstruction algorithm that transforms visual sensor data into polygonal shapes with Diffusion Models (DM), an emerging machinery amid exploding generative AI, while formulating reconstruction as a generation process conditioned on sensor data. The task of structured reconstruction poses two fundamental challenges to DM: 1) A structured geometry is a ``set'' (e.g., a set of polygons for a floorplan geometry), where a sample of $N$ elements has $N!$ different but equivalent representations, making the denoising highly ambiguous; and 2) A ``reconstruction'' task has a single solution, where an initial noise needs to be chosen carefully, while any initial noise works for a generation task. Our technical contribution is the introduction of a Guided Set Diffusion Model where 1) the forward diffusion process learns guidance networks to control noise injection so that one representation of a sample remains distinct from its other permutation variants, thus resolving denoising ambiguity; and 2) the reverse denoising process reconstructs polygonal shapes, initialized and directed by the guidance networks, as a conditional generation process subject to the sensor data. We have evaluated our approach for reconstructing two types of polygonal shapes: floorplan as a set of polygons and HD map for autonomous cars as a set of polylines. Through extensive experiments on standard benchmarks, we demonstrate that PolyDiffuse significantly advances the current state of the art and enables broader practical applications.
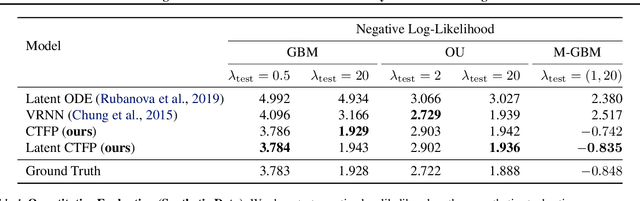
Continuous Latent Process Flows
Jun 29, 2021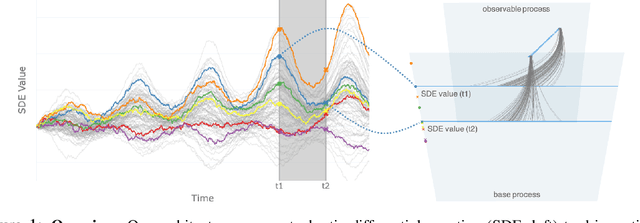
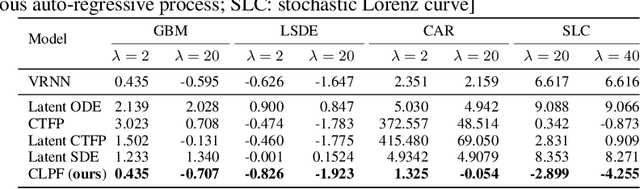
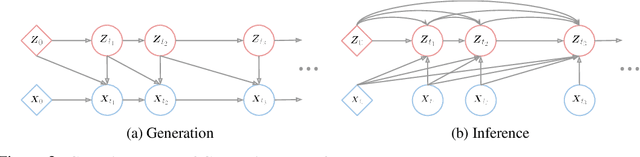
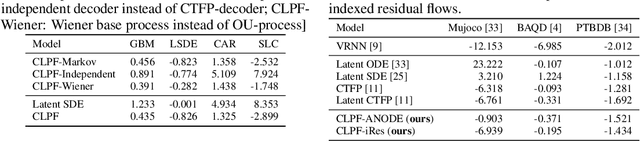
Partial observations of continuous time-series dynamics at arbitrary time stamps exist in many disciplines. Fitting this type of data using statistical models with continuous dynamics is not only promising at an intuitive level but also has practical benefits, including the ability to generate continuous trajectories and to perform inference on previously unseen time stamps. Despite exciting progress in this area, the existing models still face challenges in terms of their representational power and the quality of their variational approximations. We tackle these challenges with continuous latent process flows (CLPF), a principled architecture decoding continuous latent processes into continuous observable processes using a time-dependent normalizing flow driven by a stochastic differential equation. To optimize our model using maximum likelihood, we propose a novel piecewise construction of a variational posterior process and derive the corresponding variational lower bound using trajectory re-weighting. Our ablation studies demonstrate the effectiveness of our contributions in various inference tasks on irregular time grids. Comparisons to state-of-the-art baselines show our model's favourable performance on both synthetic and real-world time-series data.
Adaptive Appearance Rendering
Apr 24, 2021
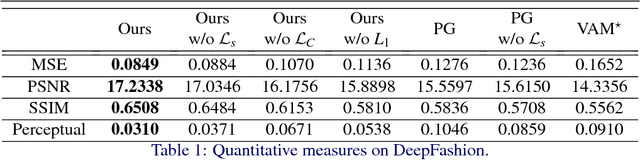
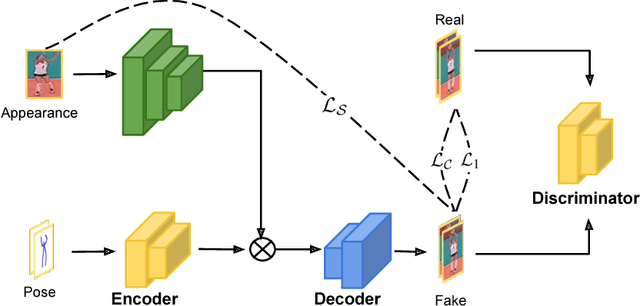
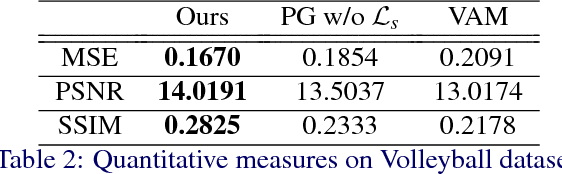
We propose an approach to generate images of people given a desired appearance and pose. Disentangled representations of pose and appearance are necessary to handle the compound variability in the resulting generated images. Hence, we develop an approach based on intermediate representations of poses and appearance: our pose-guided appearance rendering network firstly encodes the targets' poses using an encoder-decoder neural network. Then the targets' appearances are encoded by learning adaptive appearance filters using a fully convolutional network. Finally, these filters are placed in the encoder-decoder neural networks to complete the rendering. We demonstrate that our model can generate images and videos that are superior to state-of-the-art methods, and can handle pose guided appearance rendering in both image and video generation.
Modeling Continuous Stochastic Processes with Dynamic Normalizing Flows
Feb 24, 2020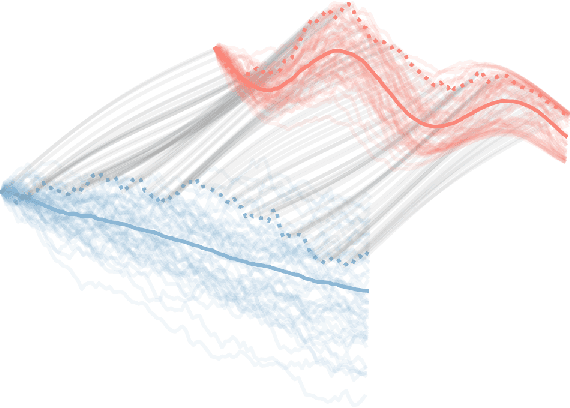
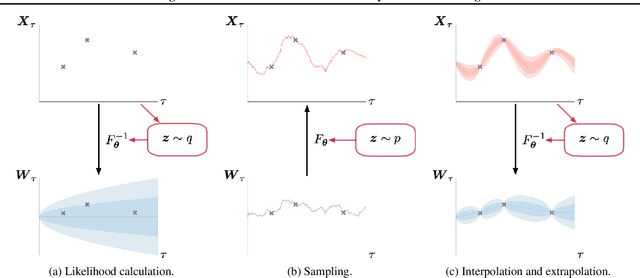

Normalizing flows transform a simple base distribution into a complex target distribution and have proved to be powerful models for data generation and density estimation. In this work, we propose a novel type of normalizing flow driven by a differential deformation of the continuous-time Wiener process. As a result, we obtain a rich time series model whose observable process inherits many of the appealing properties of its base process, such as efficient computation of likelihoods and marginals. Furthermore, our continuous treatment provides a natural framework for irregular time series with an independent arrival process, including straightforward interpolation. We illustrate the desirable properties of the proposed model on popular stochastic processes and demonstrate its superior flexibility to variational RNN and latent ODE baselines in a series of experiments on synthetic and real-world data.
Variational Hyper RNN for Sequence Modeling
Feb 24, 2020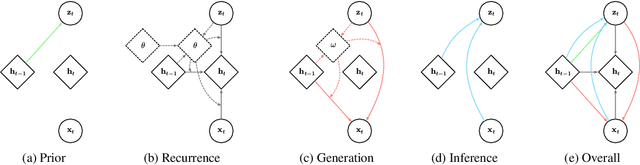

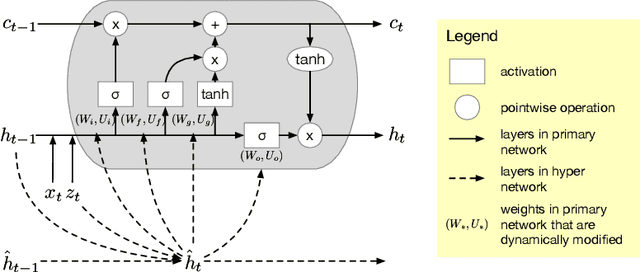
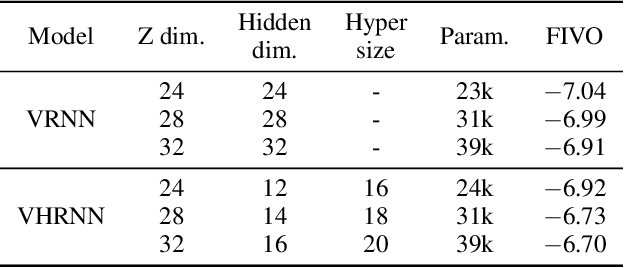
In this work, we propose a novel probabilistic sequence model that excels at capturing high variability in time series data, both across sequences and within an individual sequence. Our method uses temporal latent variables to capture information about the underlying data pattern and dynamically decodes the latent information into modifications of weights of the base decoder and recurrent model. The efficacy of the proposed method is demonstrated on a range of synthetic and real-world sequential data that exhibit large scale variations, regime shifts, and complex dynamics.
Point Process Flows
Oct 31, 2019
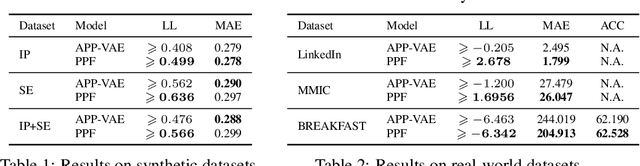
Event sequences can be modeled by temporal point processes (TPPs) to capture their asynchronous and probabilistic nature. We propose an intensity-free framework that directly models the point process distribution by utilizing normalizing flows. This approach is capable of capturing highly complex temporal distributions and does not rely on restrictive parametric forms. Comparisons with state-of-the-art baseline models on both synthetic and challenging real-life datasets show that the proposed framework is effective at modeling the stochasticity of discrete event sequences.
Characterizing Adversarial Examples Based on Spatial Consistency Information for Semantic Segmentation
Oct 11, 2018
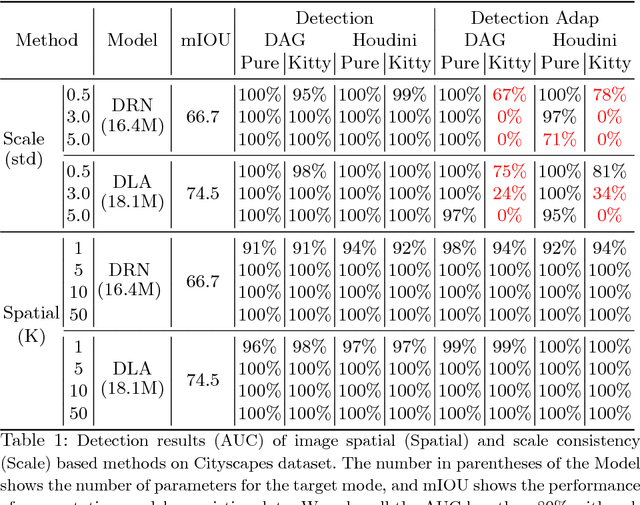

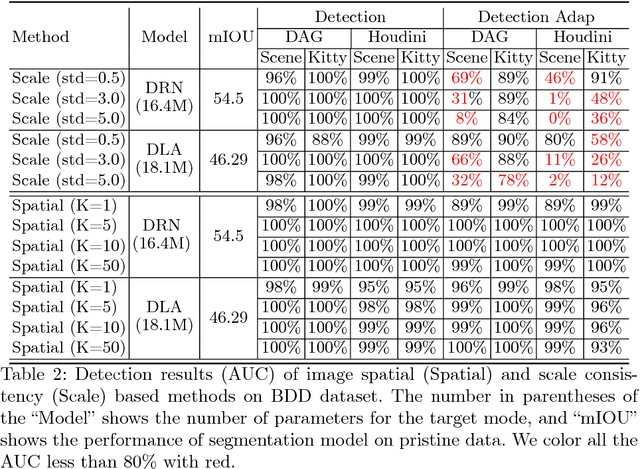
Deep Neural Networks (DNNs) have been widely applied in various recognition tasks. However, recently DNNs have been shown to be vulnerable against adversarial examples, which can mislead DNNs to make arbitrary incorrect predictions. While adversarial examples are well studied in classification tasks, other learning problems may have different properties. For instance, semantic segmentation requires additional components such as dilated convolutions and multiscale processing. In this paper, we aim to characterize adversarial examples based on spatial context information in semantic segmentation. We observe that spatial consistency information can be potentially leveraged to detect adversarial examples robustly even when a strong adaptive attacker has access to the model and detection strategies. We also show that adversarial examples based on attacks considered within the paper barely transfer among models, even though transferability is common in classification. Our observations shed new light on developing adversarial attacks and defenses to better understand the vulnerabilities of DNNs.
Sparsely Aggregated Convolutional Networks
Apr 16, 2018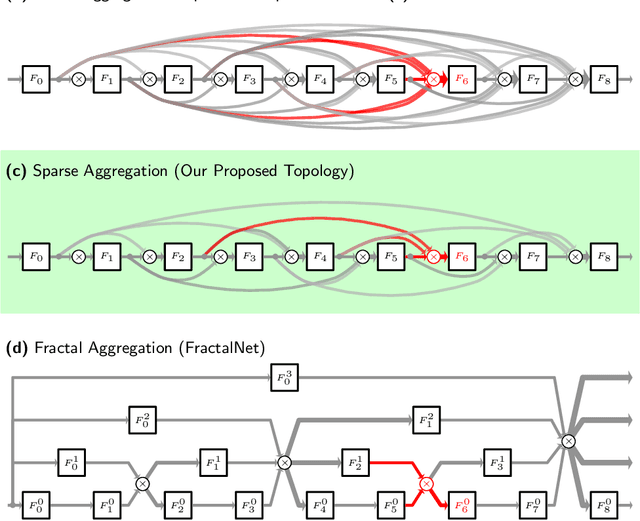
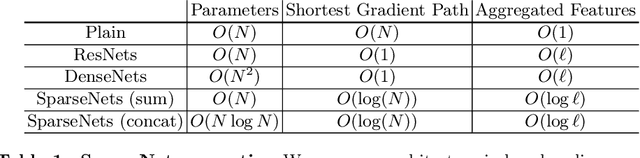
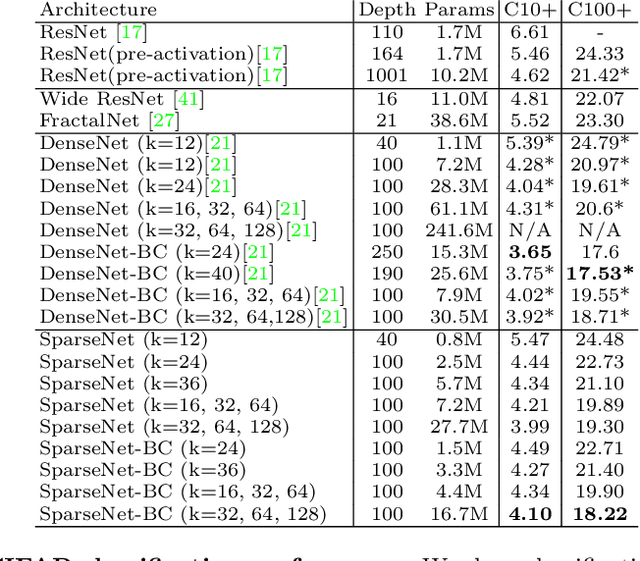
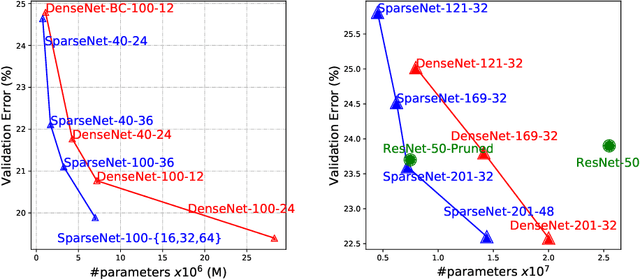
We explore a key architectural aspect of deep convolutional neural networks: the pattern of internal skip connections used to aggregate outputs of earlier layers for consumption by deeper layers. Such aggregation is critical to facilitate training of very deep networks in an end-to-end manner. This is a primary reason for the widespread adoption of residual networks, which aggregate outputs via cumulative summation. While subsequent works investigate alternative aggregation operations (e.g. concatenation), we focus on an orthogonal question: which outputs to aggregate at a particular point in the network. We propose a new internal connection structure which aggregates only a sparse set of previous outputs at any given depth. Our experiments demonstrate this simple design change offers superior performance with fewer parameters and lower computational requirements. Moreover, we show that sparse aggregation allows networks to scale more robustly to 1000+ layers, thereby opening future avenues for training long-running visual processes.