 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScoring the Unscorables: Cyber Risk Assessment Beyond Internet Scans
Jun 07, 2025In this paper we present a study on using novel data types to perform cyber risk quantification by estimating the likelihood of a data breach. We demonstrate that it is feasible to build a highly accurate cyber risk assessment model using public and readily available technology signatures obtained from crawling an organization's website. This approach overcomes the limitations of previous similar approaches that relied on large-scale IP address based scanning data, which suffers from incomplete/missing IP address mappings as well as the lack of such data for large numbers of small and medium-sized organizations (SMEs). In comparison to scan data, technology digital signature data is more readily available for millions of SMEs. Our study shows that there is a strong relationship between these technology signatures and an organization's cybersecurity posture. In cross-validating our model using different cyber incident datasets, we also highlight the key differences between ransomware attack victims and the larger population of cyber incident and data breach victims.
Providing Differential Privacy for Federated Learning Over Wireless: A Cross-layer Framework
Dec 05, 2024



Federated Learning (FL) is a distributed machine learning framework that inherently allows edge devices to maintain their local training data, thus providing some level of privacy. However, FL's model updates still pose a risk of privacy leakage, which must be mitigated. Over-the-air FL (OTA-FL) is an adapted FL design for wireless edge networks that leverages the natural superposition property of the wireless medium. We propose a wireless physical layer (PHY) design for OTA-FL which improves differential privacy (DP) through a decentralized, dynamic power control that utilizes both inherent Gaussian noise in the wireless channel and a cooperative jammer (CJ) for additional artificial noise generation when higher privacy levels are required. Although primarily implemented within the Upcycled-FL framework, where a resource-efficient method with first-order approximations is used at every even iteration to decrease the required information from clients, our power control strategy is applicable to any FL framework, including FedAvg and FedProx as shown in the paper. This adaptation showcases the flexibility and effectiveness of our design across different learning algorithms while maintaining a strong emphasis on privacy. Our design removes the need for client-side artificial noise injection for DP, utilizing a cooperative jammer to enhance privacy without affecting transmission efficiency for higher privacy demands. Privacy analysis is provided using the Moments Accountant method. We perform a convergence analysis for non-convex objectives to tackle heterogeneous data distributions, highlighting the inherent trade-offs between privacy and accuracy. Numerical results show that our approach with various FL algorithms outperforms the state-of-the-art under the same DP conditions on the non-i.i.d. FEMNIST dataset, and highlight the cooperative jammer's effectiveness in ensuring strict privacy.
Federated Learning with Reduced Information Leakage and Computation
Oct 10, 2023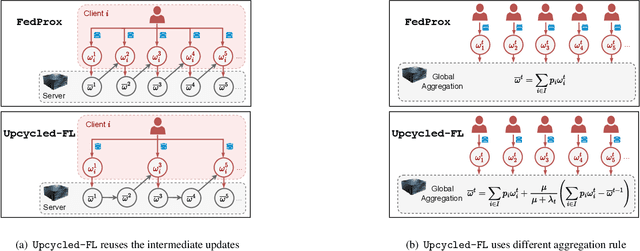
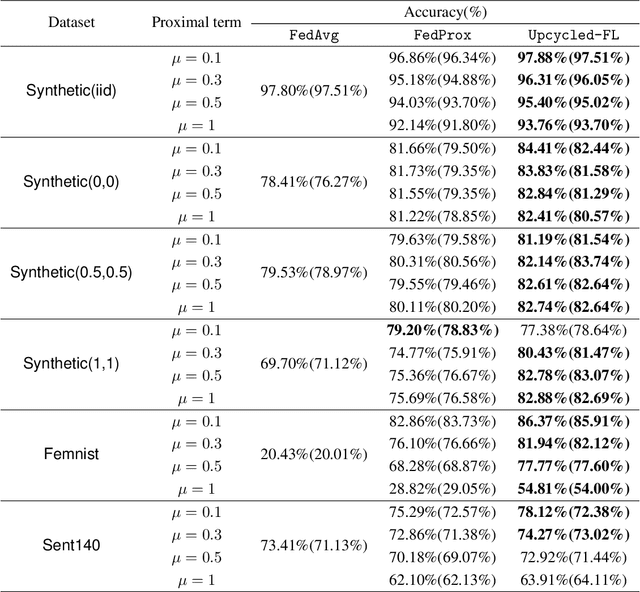
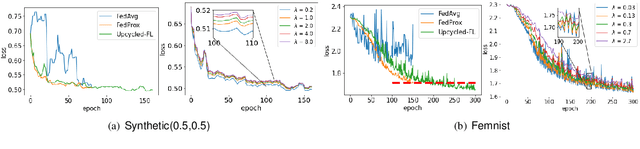
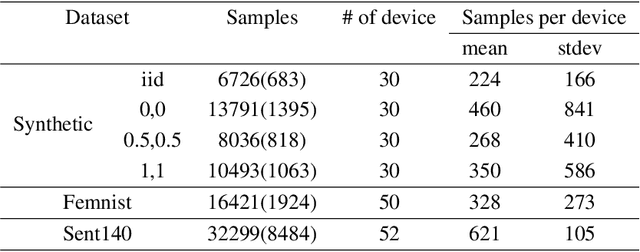
Federated learning (FL) is a distributed learning paradigm that allows multiple decentralized clients to collaboratively learn a common model without sharing local data. Although local data is not exposed directly, privacy concerns nonetheless exist as clients' sensitive information can be inferred from intermediate computations. Moreover, such information leakage accumulates substantially over time as the same data is repeatedly used during the iterative learning process. As a result, it can be particularly difficult to balance the privacy-accuracy trade-off when designing privacy-preserving FL algorithms. In this paper, we introduce Upcycled-FL, a novel federated learning framework with first-order approximation applied at every even iteration. Under this framework, half of the FL updates incur no information leakage and require much less computation. We first conduct the theoretical analysis on the convergence (rate) of Upcycled-FL, and then apply perturbation mechanisms to preserve privacy. Experiments on real-world data show that Upcycled-FL consistently outperforms existing methods over heterogeneous data, and significantly improves privacy-accuracy trade-off while reducing 48% of the training time on average.
Fair Classifiers that Abstain without Harm
Oct 09, 2023In critical applications, it is vital for classifiers to defer decision-making to humans. We propose a post-hoc method that makes existing classifiers selectively abstain from predicting certain samples. Our abstaining classifier is incentivized to maintain the original accuracy for each sub-population (i.e. no harm) while achieving a set of group fairness definitions to a user specified degree. To this end, we design an Integer Programming (IP) procedure that assigns abstention decisions for each training sample to satisfy a set of constraints. To generalize the abstaining decisions to test samples, we then train a surrogate model to learn the abstaining decisions based on the IP solutions in an end-to-end manner. We analyze the feasibility of the IP procedure to determine the possible abstention rate for different levels of unfairness tolerance and accuracy constraint for achieving no harm. To the best of our knowledge, this work is the first to identify the theoretical relationships between the constraint parameters and the required abstention rate. Our theoretical results are important since a high abstention rate is often infeasible in practice due to a lack of human resources. Our framework outperforms existing methods in terms of fairness disparity without sacrificing accuracy at similar abstention rates.
Professional Basketball Player Behavior Synthesis via Planning with Diffusion
Jun 10, 2023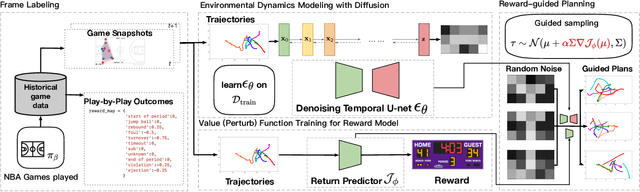
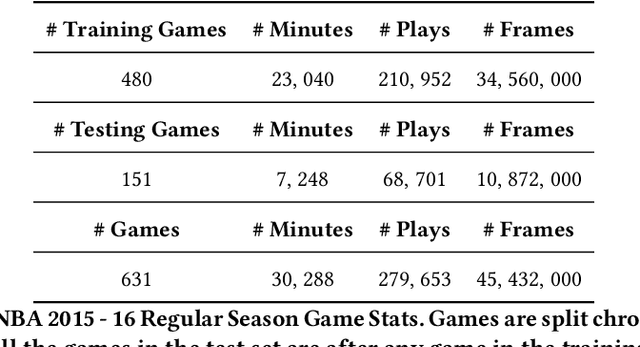
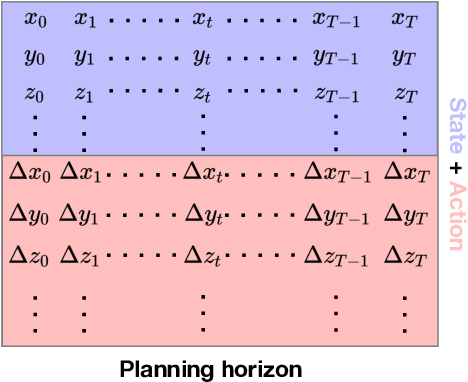

Dynamically planning in multi-agent systems has been explored to improve decision-making in various domains. Professional basketball serves as a compelling example of a dynamic spatio-temporal game, encompassing both concealed strategic policies and decision-making. However, processing the diverse on-court signals and navigating the vast space of potential actions and outcomes makes it difficult for existing approaches to swiftly identify optimal strategies in response to evolving circumstances. In this study, we first formulate the sequential decision-making process as a conditional trajectory generation process. We further introduce PLAYBEST (PLAYer BEhavior SynThesis), a method for enhancing player decision-making. We extend the state-of-the-art generative model, diffusion probabilistic model, to learn challenging multi-agent environmental dynamics from historical National Basketball Association (NBA) player motion tracking data. To incorporate data-driven strategies, an auxiliary value function is trained using the play-by-play data with corresponding rewards acting as the plan guidance. To accomplish reward-guided trajectory generation, conditional sampling is introduced to condition the diffusion model on the value function and conduct classifier-guided sampling. We validate the effectiveness of PLAYBEST via comprehensive simulation studies from real-world data, contrasting the generated trajectories and play strategies with those employed by professional basketball teams. Our results reveal that the model excels at generating high-quality basketball trajectories that yield efficient plays, surpassing conventional planning techniques in terms of adaptability, flexibility, and overall performance. Moreover, the synthesized play strategies exhibit a remarkable alignment with professional tactics, highlighting the model's capacity to capture the intricate dynamics of basketball games.
Performative Federated Learning: A Solution to Model-Dependent and Heterogeneous Distribution Shifts
May 08, 2023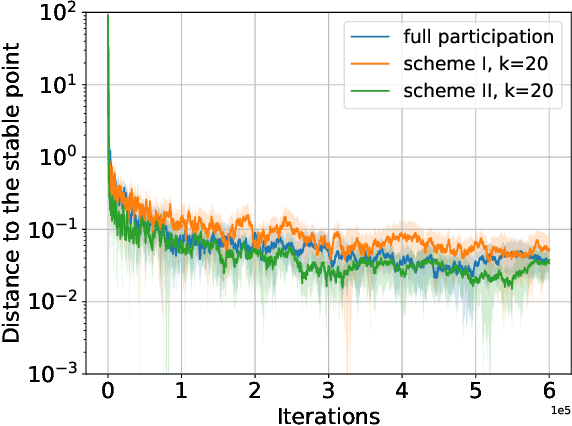
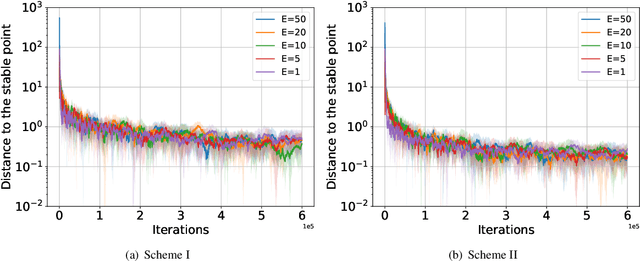
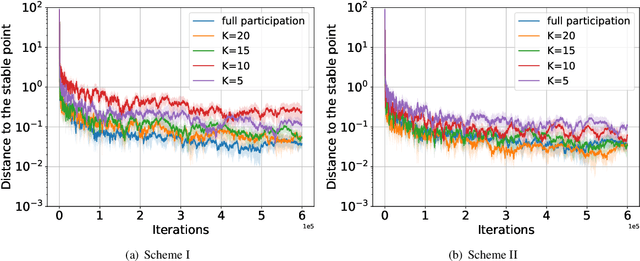
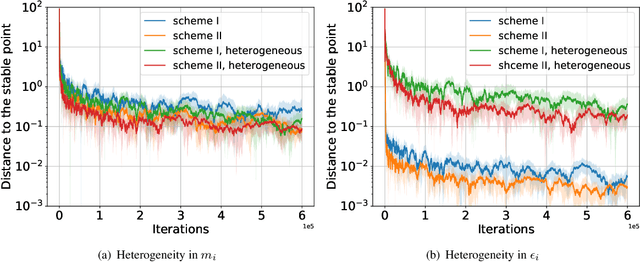
We consider a federated learning (FL) system consisting of multiple clients and a server, where the clients aim to collaboratively learn a common decision model from their distributed data. Unlike the conventional FL framework that assumes the client's data is static, we consider scenarios where the clients' data distributions may be reshaped by the deployed decision model. In this work, we leverage the idea of distribution shift mappings in performative prediction to formalize this model-dependent data distribution shift and propose a performative federated learning framework. We first introduce necessary and sufficient conditions for the existence of a unique performative stable solution and characterize its distance to the performative optimal solution. Then we propose the performative FedAvg algorithm and show that it converges to the performative stable solution at a rate of O(1/T) under both full and partial participation schemes. In particular, we use novel proof techniques and show how the clients' heterogeneity influences the convergence. Numerical results validate our analysis and provide valuable insights into real-world applications.
Long-Term Fairness with Unknown Dynamics
Apr 19, 2023



While machine learning can myopically reinforce social inequalities, it may also be used to dynamically seek equitable outcomes. In this paper, we formalize long-term fairness in the context of online reinforcement learning. This formulation can accommodate dynamical control objectives, such as driving equity inherent in the state of a population, that cannot be incorporated into static formulations of fairness. We demonstrate that this framing allows an algorithm to adapt to unknown dynamics by sacrificing short-term incentives to drive a classifier-population system towards more desirable equilibria. For the proposed setting, we develop an algorithm that adapts recent work in online learning. We prove that this algorithm achieves simultaneous probabilistic bounds on cumulative loss and cumulative violations of fairness (as statistical regularities between demographic groups). We compare our proposed algorithm to the repeated retraining of myopic classifiers, as a baseline, and to a deep reinforcement learning algorithm that lacks safety guarantees. Our experiments model human populations according to evolutionary game theory and integrate real-world datasets.
DensePure: Understanding Diffusion Models towards Adversarial Robustness
Nov 01, 2022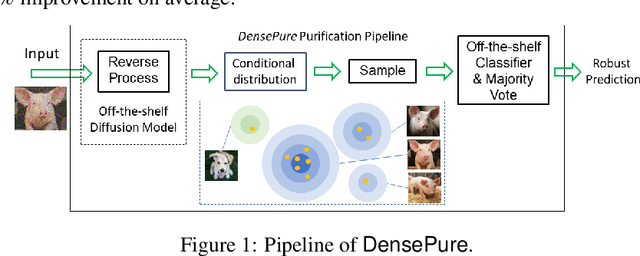
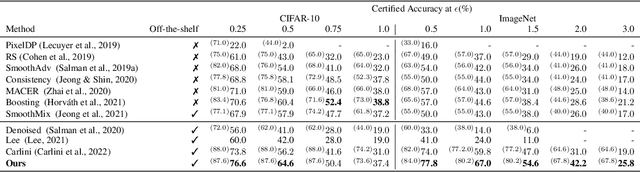
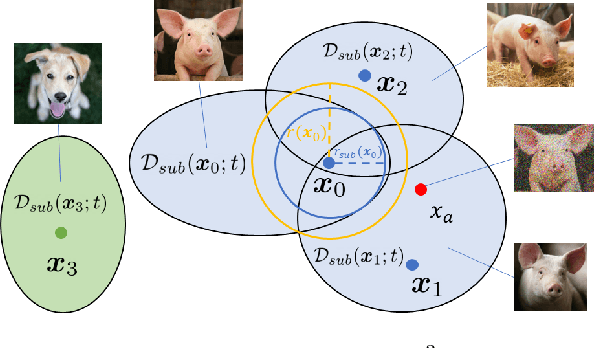

Diffusion models have been recently employed to improve certified robustness through the process of denoising. However, the theoretical understanding of why diffusion models are able to improve the certified robustness is still lacking, preventing from further improvement. In this study, we close this gap by analyzing the fundamental properties of diffusion models and establishing the conditions under which they can enhance certified robustness. This deeper understanding allows us to propose a new method DensePure, designed to improve the certified robustness of a pretrained model (i.e. classifier). Given an (adversarial) input, DensePure consists of multiple runs of denoising via the reverse process of the diffusion model (with different random seeds) to get multiple reversed samples, which are then passed through the classifier, followed by majority voting of inferred labels to make the final prediction. This design of using multiple runs of denoising is informed by our theoretical analysis of the conditional distribution of the reversed sample. Specifically, when the data density of a clean sample is high, its conditional density under the reverse process in a diffusion model is also high; thus sampling from the latter conditional distribution can purify the adversarial example and return the corresponding clean sample with a high probability. By using the highest density point in the conditional distribution as the reversed sample, we identify the robust region of a given instance under the diffusion model's reverse process. We show that this robust region is a union of multiple convex sets, and is potentially much larger than the robust regions identified in previous works. In practice, DensePure can approximate the label of the high density region in the conditional distribution so that it can enhance certified robustness.
Invisible for both Camera and LiDAR: Security of Multi-Sensor Fusion based Perception in Autonomous Driving Under Physical-World Attacks
Jun 17, 2021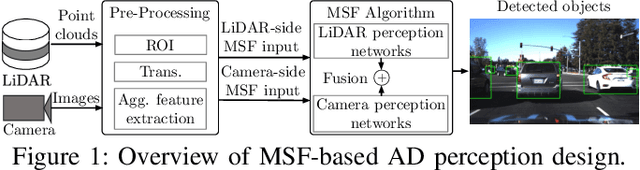



In Autonomous Driving (AD) systems, perception is both security and safety critical. Despite various prior studies on its security issues, all of them only consider attacks on camera- or LiDAR-based AD perception alone. However, production AD systems today predominantly adopt a Multi-Sensor Fusion (MSF) based design, which in principle can be more robust against these attacks under the assumption that not all fusion sources are (or can be) attacked at the same time. In this paper, we present the first study of security issues of MSF-based perception in AD systems. We directly challenge the basic MSF design assumption above by exploring the possibility of attacking all fusion sources simultaneously. This allows us for the first time to understand how much security guarantee MSF can fundamentally provide as a general defense strategy for AD perception. We formulate the attack as an optimization problem to generate a physically-realizable, adversarial 3D-printed object that misleads an AD system to fail in detecting it and thus crash into it. We propose a novel attack pipeline that addresses two main design challenges: (1) non-differentiable target camera and LiDAR sensing systems, and (2) non-differentiable cell-level aggregated features popularly used in LiDAR-based AD perception. We evaluate our attack on MSF included in representative open-source industry-grade AD systems in real-world driving scenarios. Our results show that the attack achieves over 90% success rate across different object types and MSF. Our attack is also found stealthy, robust to victim positions, transferable across MSF algorithms, and physical-world realizable after being 3D-printed and captured by LiDAR and camera devices. To concretely assess the end-to-end safety impact, we further perform simulation evaluation and show that it can cause a 100% vehicle collision rate for an industry-grade AD system.
How Do Fair Decisions Fare in Long-term Qualification?
Oct 21, 2020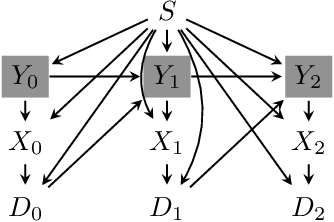
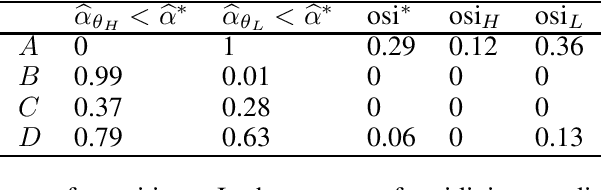
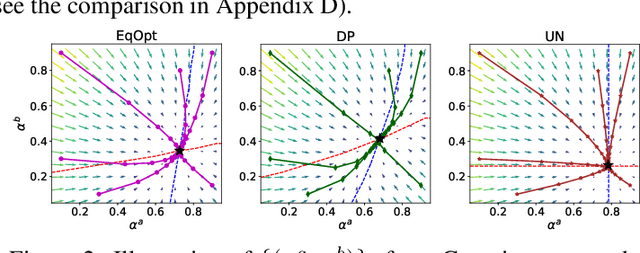

Although many fairness criteria have been proposed for decision making, their long-term impact on the well-being of a population remains unclear. In this work, we study the dynamics of population qualification and algorithmic decisions under a partially observed Markov decision problem setting. By characterizing the equilibrium of such dynamics, we analyze the long-term impact of static fairness constraints on the equality and improvement of group well-being. Our results show that static fairness constraints can either promote equality or exacerbate disparity depending on the driving factor of qualification transitions and the effect of sensitive attributes on feature distributions. We also consider possible interventions that can effectively improve group qualification or promote equality of group qualification. Our theoretical results and experiments on static real-world datasets with simulated dynamics show that our framework can be used to facilitate social science studies.