 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReviving The Classics: Active Reward Modeling in Large Language Model Alignment
Feb 04, 2025



Building neural reward models from human preferences is a pivotal component in reinforcement learning from human feedback (RLHF) and large language model alignment research. Given the scarcity and high cost of human annotation, how to select the most informative pairs to annotate is an essential yet challenging open problem. In this work, we highlight the insight that an ideal comparison dataset for reward modeling should balance exploration of the representation space and make informative comparisons between pairs with moderate reward differences. Technically, challenges arise in quantifying the two objectives and efficiently prioritizing the comparisons to be annotated. To address this, we propose the Fisher information-based selection strategies, adapt theories from the classical experimental design literature, and apply them to the final linear layer of the deep neural network-based reward modeling tasks. Empirically, our method demonstrates remarkable performance, high computational efficiency, and stability compared to other selection methods from deep learning and classical statistical literature across multiple open-source LLMs and datasets. Further ablation studies reveal that incorporating cross-prompt comparisons in active reward modeling significantly enhances labeling efficiency, shedding light on the potential for improved annotation strategies in RLHF.
Conformal Counterfactual Inference under Hidden Confounding
May 20, 2024
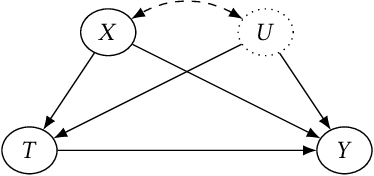

Personalized decision making requires the knowledge of potential outcomes under different treatments, and confidence intervals about the potential outcomes further enrich this decision-making process and improve its reliability in high-stakes scenarios. Predicting potential outcomes along with its uncertainty in a counterfactual world poses the foundamental challenge in causal inference. Existing methods that construct confidence intervals for counterfactuals either rely on the assumption of strong ignorability, or need access to un-identifiable lower and upper bounds that characterize the difference between observational and interventional distributions. To overcome these limitations, we first propose a novel approach wTCP-DR based on transductive weighted conformal prediction, which provides confidence intervals for counterfactual outcomes with marginal converage guarantees, even under hidden confounding. With less restrictive assumptions, our approach requires access to a fraction of interventional data (from randomized controlled trials) to account for the covariate shift from observational distributoin to interventional distribution. Theoretical results explicitly demonstrate the conditions under which our algorithm is strictly advantageous to the naive method that only uses interventional data. After ensuring valid intervals on counterfactuals, it is straightforward to construct intervals for individual treatment effects (ITEs). We demonstrate our method across synthetic and real-world data, including recommendation systems, to verify the superiority of our methods compared against state-of-the-art baselines in terms of both coverage and efficiency
Fair Classifiers that Abstain without Harm
Oct 09, 2023In critical applications, it is vital for classifiers to defer decision-making to humans. We propose a post-hoc method that makes existing classifiers selectively abstain from predicting certain samples. Our abstaining classifier is incentivized to maintain the original accuracy for each sub-population (i.e. no harm) while achieving a set of group fairness definitions to a user specified degree. To this end, we design an Integer Programming (IP) procedure that assigns abstention decisions for each training sample to satisfy a set of constraints. To generalize the abstaining decisions to test samples, we then train a surrogate model to learn the abstaining decisions based on the IP solutions in an end-to-end manner. We analyze the feasibility of the IP procedure to determine the possible abstention rate for different levels of unfairness tolerance and accuracy constraint for achieving no harm. To the best of our knowledge, this work is the first to identify the theoretical relationships between the constraint parameters and the required abstention rate. Our theoretical results are important since a high abstention rate is often infeasible in practice due to a lack of human resources. Our framework outperforms existing methods in terms of fairness disparity without sacrificing accuracy at similar abstention rates.
Fair Learning to Rank with Distribution-free Risk Control
Jun 13, 2023
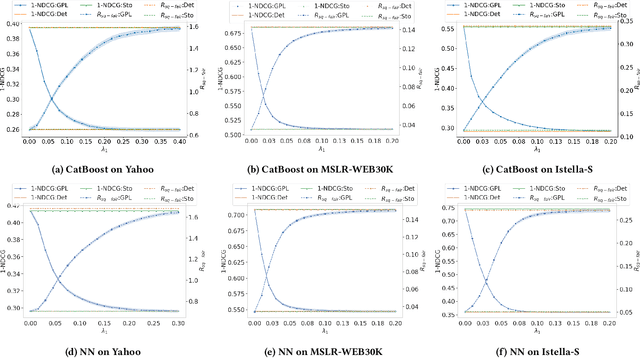


Learning to Rank (LTR) methods are vital in online economies, affecting users and item providers. Fairness in LTR models is crucial to allocate exposure proportionally to item relevance. The deterministic ranking model can lead to unfair exposure distribution when items with the same relevance receive slightly different scores. Stochastic LTR models, incorporating the Plackett-Luce (PL) model, address fairness issues but have limitations in computational cost and performance guarantees. To overcome these limitations, we propose FairLTR-RC, a novel post-hoc model-agnostic method. FairLTR-RC leverages a pretrained scoring function to create a stochastic LTR model, eliminating the need for expensive training. Furthermore, FairLTR-RC provides finite-sample guarantees on a user-specified utility using distribution-free risk control framework. By additionally incorporating the Thresholded PL (TPL) model, we are able to achieve an effective trade-off between utility and fairness. Experimental results on several benchmark datasets demonstrate that FairLTR-RC significantly improves fairness in widely-used deterministic LTR models while guaranteeing a specified level of utility.
Grassmann Stein Variational Gradient Descent
Feb 07, 2022
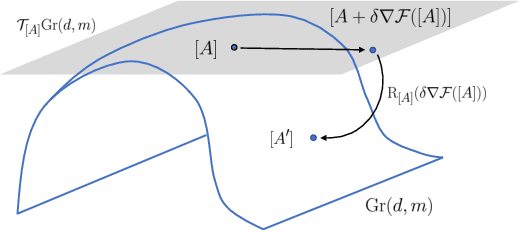
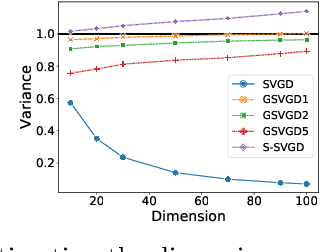
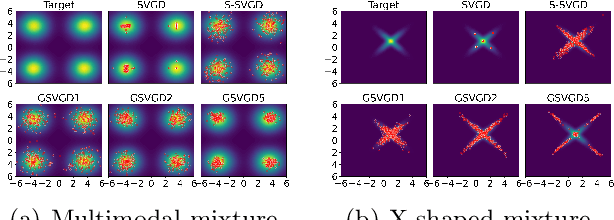
Stein variational gradient descent (SVGD) is a deterministic particle inference algorithm that provides an efficient alternative to Markov chain Monte Carlo. However, SVGD has been found to suffer from variance underestimation when the dimensionality of the target distribution is high. Recent developments have advocated projecting both the score function and the data onto real lines to sidestep this issue, although this can severely overestimate the epistemic (model) uncertainty. In this work, we propose Grassmann Stein variational gradient descent (GSVGD) as an alternative approach, which permits projections onto arbitrary dimensional subspaces. Compared with other variants of SVGD that rely on dimensionality reduction, GSVGD updates the projectors simultaneously for the score function and the data, and the optimal projectors are determined through a coupled Grassmann-valued diffusion process which explores favourable subspaces. Both our theoretical and experimental results suggest that GSVGD enjoys efficient state-space exploration in high-dimensional problems that have an intrinsic low-dimensional structure.
BayesIMP: Uncertainty Quantification for Causal Data Fusion
Jun 07, 2021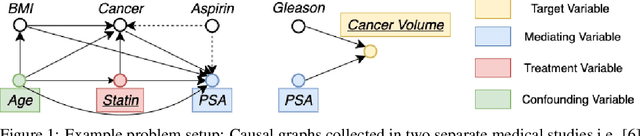
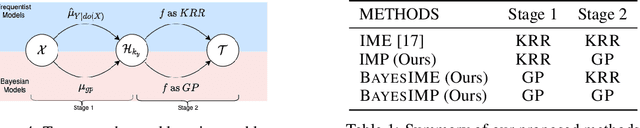

While causal models are becoming one of the mainstays of machine learning, the problem of uncertainty quantification in causal inference remains challenging. In this paper, we study the causal data fusion problem, where datasets pertaining to multiple causal graphs are combined to estimate the average treatment effect of a target variable. As data arises from multiple sources and can vary in quality and quantity, principled uncertainty quantification becomes essential. To that end, we introduce Bayesian Interventional Mean Processes, a framework which combines ideas from probabilistic integration and kernel mean embeddings to represent interventional distributions in the reproducing kernel Hilbert space, while taking into account the uncertainty within each causal graph. To demonstrate the utility of our uncertainty estimation, we apply our method to the Causal Bayesian Optimisation task and show improvements over state-of-the-art methods.