 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Learning to Rank with Distribution-free Risk Control
Paper and Code

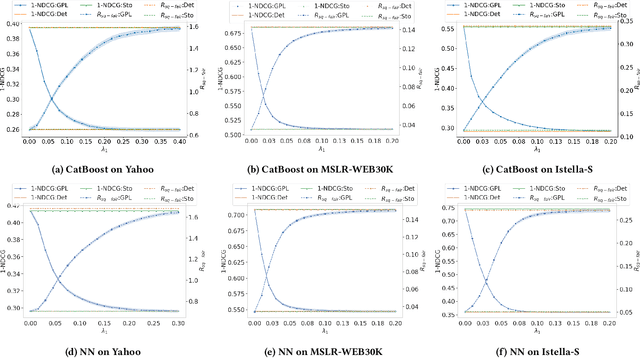


Learning to Rank (LTR) methods are vital in online economies, affecting users and item providers. Fairness in LTR models is crucial to allocate exposure proportionally to item relevance. The deterministic ranking model can lead to unfair exposure distribution when items with the same relevance receive slightly different scores. Stochastic LTR models, incorporating the Plackett-Luce (PL) model, address fairness issues but have limitations in computational cost and performance guarantees. To overcome these limitations, we propose FairLTR-RC, a novel post-hoc model-agnostic method. FairLTR-RC leverages a pretrained scoring function to create a stochastic LTR model, eliminating the need for expensive training. Furthermore, FairLTR-RC provides finite-sample guarantees on a user-specified utility using distribution-free risk control framework. By additionally incorporating the Thresholded PL (TPL) model, we are able to achieve an effective trade-off between utility and fairness. Experimental results on several benchmark datasets demonstrate that FairLTR-RC significantly improves fairness in widely-used deterministic LTR models while guaranteeing a specified level of utility.