 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformative Risk Control: Calibrating Models for Reliable Deployment under Performativity
May 30, 2025Calibrating blackbox machine learning models to achieve risk control is crucial to ensure reliable decision-making. A rich line of literature has been studying how to calibrate a model so that its predictions satisfy explicit finite-sample statistical guarantees under a fixed, static, and unknown data-generating distribution. However, prediction-supported decisions may influence the outcome they aim to predict, a phenomenon named performativity of predictions, which is commonly seen in social science and economics. In this paper, we introduce Performative Risk Control, a framework to calibrate models to achieve risk control under performativity with provable theoretical guarantees. Specifically, we provide an iteratively refined calibration process, where we ensure the predictions are improved and risk-controlled throughout the process. We also study different types of risk measures and choices of tail bounds. Lastly, we demonstrate the effectiveness of our framework by numerical experiments on the task of predicting credit default risk. To the best of our knowledge, this work is the first one to study statistically rigorous risk control under performativity, which will serve as an important safeguard against a wide range of strategic manipulation in decision-making processes.
ADiff4TPP: Asynchronous Diffusion Models for Temporal Point Processes
Apr 29, 2025


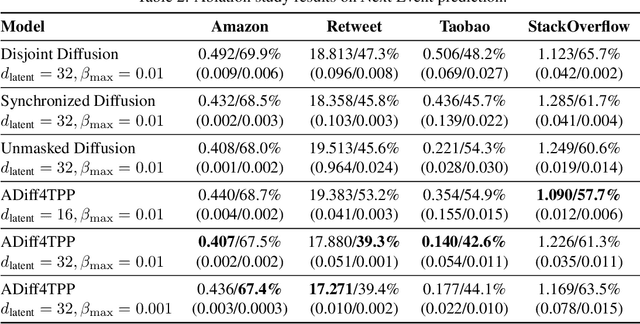
This work introduces a novel approach to modeling temporal point processes using diffusion models with an asynchronous noise schedule. At each step of the diffusion process, the noise schedule injects noise of varying scales into different parts of the data. With a careful design of the noise schedules, earlier events are generated faster than later ones, thus providing stronger conditioning for forecasting the more distant future. We derive an objective to effectively train these models for a general family of noise schedules based on conditional flow matching. Our method models the joint distribution of the latent representations of events in a sequence and achieves state-of-the-art results in predicting both the next inter-event time and event type on benchmark datasets. Additionally, it flexibly accommodates varying lengths of observation and prediction windows in different forecasting settings by adjusting the starting and ending points of the generation process. Finally, our method shows superior performance in long-horizon prediction tasks, outperforming existing baseline methods.
IceFormer: Accelerated Inference with Long-Sequence Transformers on CPUs
May 05, 2024



One limitation of existing Transformer-based models is that they cannot handle very long sequences as input since their self-attention operations exhibit quadratic time and space complexity. This problem becomes especially acute when Transformers are deployed on hardware platforms equipped only with CPUs. To address this issue, we propose a novel method for accelerating self-attention at inference time that works with pretrained Transformer models out-of-the-box without requiring retraining. We experiment using our method to accelerate various long-sequence Transformers, including a leading LLaMA 2-based LLM, on various benchmarks and demonstrate a greater speedup of 2.73x - 7.63x while retaining 98.6% - 99.6% of the accuracy of the original pretrained models. The code is available on our project website at https://yuzhenmao.github.io/IceFormer/.
Dynamic Transfer Learning across Graphs
May 02, 2023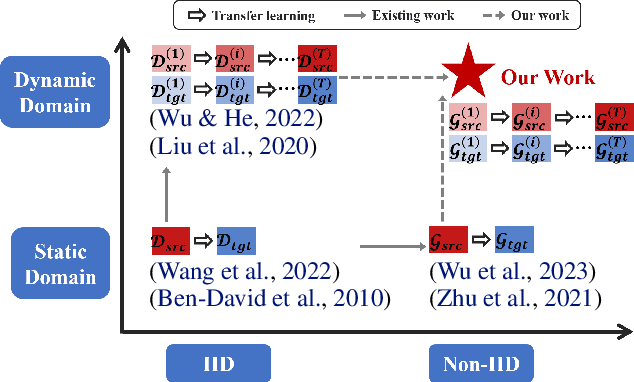
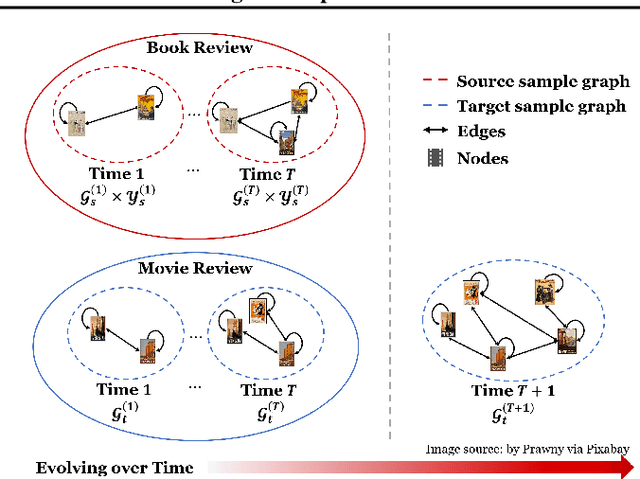
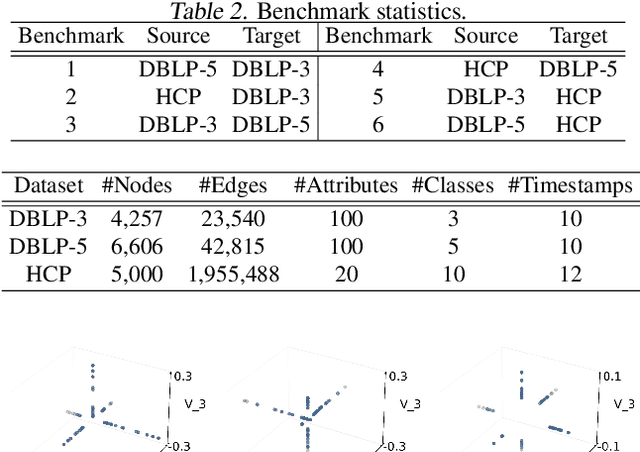
Transferring knowledge across graphs plays a pivotal role in many high-stake domains, ranging from transportation networks to e-commerce networks, from neuroscience to finance. To date, the vast majority of existing works assume both source and target domains are sampled from a universal and stationary distribution. However, many real-world systems are intrinsically dynamic, where the underlying domains are evolving over time. To bridge the gap, we propose to shift the problem to the dynamic setting and ask: given the label-rich source graphs and the label-scarce target graphs observed in previous T timestamps, how can we effectively characterize the evolving domain discrepancy and optimize the generalization performance of the target domain at the incoming T+1 timestamp? To answer the question, for the first time, we propose a generalization bound under the setting of dynamic transfer learning across graphs, which implies the generalization performance is dominated by domain evolution and domain discrepancy between source and target domains. Inspired by the theoretical results, we propose a novel generic framework DyTrans to improve knowledge transferability across dynamic graphs. In particular, we start with a transformer-based temporal encoding module to model temporal information of the evolving domains; then, we further design a dynamic domain unification module to efficiently learn domain-invariant representations across the source and target domains. Finally, extensive experiments on various real-world datasets demonstrate the effectiveness of DyTrans in transferring knowledge from dynamic source domains to dynamic target domains.
Last-Layer Fairness Fine-tuning is Simple and Effective for Neural Networks
Apr 08, 2023As machine learning has been deployed ubiquitously across applications in modern data science, algorithmic fairness has become a great concern and varieties of fairness criteria have been proposed. Among them, imposing fairness constraints during learning, i.e. in-processing fair training, has been a popular type of training method because they don't require accessing sensitive attributes during test time in contrast to post-processing methods. Although imposing fairness constraints have been studied extensively for classical machine learning models, the effect these techniques have on deep neural networks is still unclear. Recent research has shown that adding fairness constraints to the objective function leads to severe over-fitting to fairness criteria in large models, and how to solve this challenge is an important open question. To address this challenge, we leverage the wisdom and power of pre-training and fine-tuning and develop a simple but novel framework to train fair neural networks in an efficient and inexpensive way. We conduct comprehensive experiments on two popular image datasets with state-of-art architectures under different fairness notions to show that last-layer fine-tuning is sufficient for promoting fairness of the deep neural network. Our framework brings new insights into representation learning in training fair neural networks.
Augmenting Knowledge Transfer across Graphs
Dec 09, 2022



Given a resource-rich source graph and a resource-scarce target graph, how can we effectively transfer knowledge across graphs and ensure a good generalization performance? In many high-impact domains (e.g., brain networks and molecular graphs), collecting and annotating data is prohibitively expensive and time-consuming, which makes domain adaptation an attractive option to alleviate the label scarcity issue. In light of this, the state-of-the-art methods focus on deriving domain-invariant graph representation that minimizes the domain discrepancy. However, it has recently been shown that a small domain discrepancy loss may not always guarantee a good generalization performance, especially in the presence of disparate graph structures and label distribution shifts. In this paper, we present TRANSNET, a generic learning framework for augmenting knowledge transfer across graphs. In particular, we introduce a novel notion named trinity signal that can naturally formulate various graph signals at different granularity (e.g., node attributes, edges, and subgraphs). With that, we further propose a domain unification module together with a trinity-signal mixup scheme to jointly minimize the domain discrepancy and augment the knowledge transfer across graphs. Finally, comprehensive empirical results show that TRANSNET outperforms all existing approaches on seven benchmark datasets by a significant margin.