 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Video Generation using Holistic Attribute Control
Paper and Code
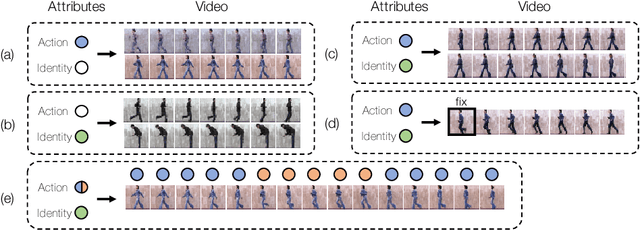
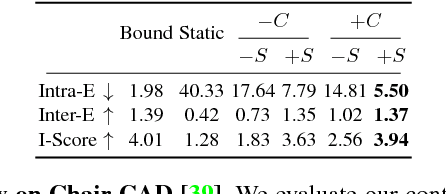
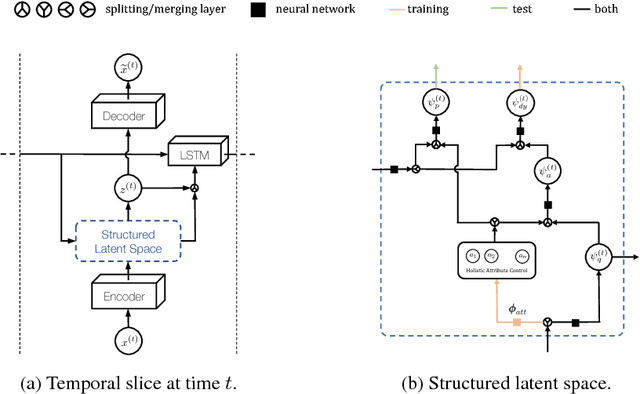

Videos express highly structured spatio-temporal patterns of visual data. A video can be thought of as being governed by two factors: (i) temporally invariant (e.g., person identity), or slowly varying (e.g., activity), attribute-induced appearance, encoding the persistent content of each frame, and (ii) an inter-frame motion or scene dynamics (e.g., encoding evolution of the person ex-ecuting the action). Based on this intuition, we propose a generative framework for video generation and future prediction. The proposed framework generates a video (short clip) by decoding samples sequentially drawn from a latent space distribution into full video frames. Variational Autoencoders (VAEs) are used as a means of encoding/decoding frames into/from the latent space and RNN as a wayto model the dynamics in the latent space. We improve the video generation consistency through temporally-conditional sampling and quality by structuring the latent space with attribute controls; ensuring that attributes can be both inferred and conditioned on during learning/generation. As a result, given attributes and/orthe first frame, our model is able to generate diverse but highly consistent sets ofvideo sequences, accounting for the inherent uncertainty in the prediction task. Experimental results on Chair CAD, Weizmann Human Action, and MIT-Flickr datasets, along with detailed comparison to the state-of-the-art, verify effectiveness of the framework.