 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtisanGS: Interactive Tools for Gaussian Splat Selection with AI and Human in the Loop
Feb 10, 2026Representation in the family of 3D Gaussian Splats (3DGS) are growing into a viable alternative to traditional graphics for an expanding number of application, including recent techniques that facilitate physics simulation and animation. However, extracting usable objects from in-the-wild captures remains challenging and controllable editing techniques for this representation are limited. Unlike the bulk of emerging techniques, focused on automatic solutions or high-level editing, we introduce an interactive suite of tools centered around versatile Gaussian Splat selection and segmentation. We propose a fast AI-driven method to propagate user-guided 2D selection masks to 3DGS selections. This technique allows for user intervention in the case of errors and is further coupled with flexible manual selection and segmentation tools. These allow a user to achieve virtually any binary segmentation of an unstructured 3DGS scene. We evaluate our toolset against the state-of-the-art for Gaussian Splat selection and demonstrate their utility for downstream applications by developing a user-guided local editing approach, leveraging a custom Video Diffusion Model. With flexible selection tools, users have direct control over the areas that the AI can modify. Our selection and editing tools can be used for any in-the-wild capture without additional optimization.
VoMP: Predicting Volumetric Mechanical Property Fields
Oct 27, 2025Physical simulation relies on spatially-varying mechanical properties, often laboriously hand-crafted. VoMP is a feed-forward method trained to predict Young's modulus ($E$), Poisson's ratio ($\nu$), and density ($\rho$) throughout the volume of 3D objects, in any representation that can be rendered and voxelized. VoMP aggregates per-voxel multi-view features and passes them to our trained Geometry Transformer to predict per-voxel material latent codes. These latents reside on a manifold of physically plausible materials, which we learn from a real-world dataset, guaranteeing the validity of decoded per-voxel materials. To obtain object-level training data, we propose an annotation pipeline combining knowledge from segmented 3D datasets, material databases, and a vision-language model, along with a new benchmark. Experiments show that VoMP estimates accurate volumetric properties, far outperforming prior art in accuracy and speed.
XDGAN: Multi-Modal 3D Shape Generation in 2D Space
Oct 06, 2022

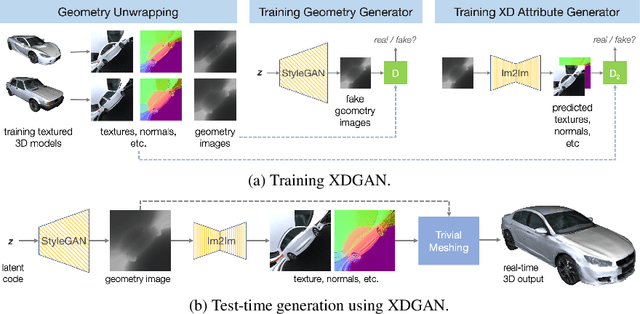
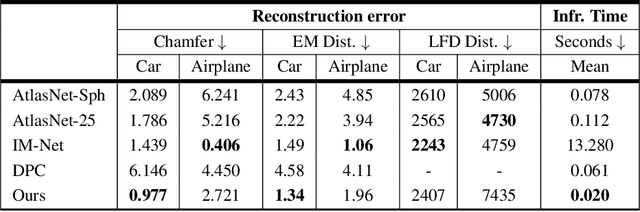
Generative models for 2D images has recently seen tremendous progress in quality, resolution and speed as a result of the efficiency of 2D convolutional architectures. However it is difficult to extend this progress into the 3D domain since most current 3D representations rely on custom network components. This paper addresses a central question: Is it possible to directly leverage 2D image generative models to generate 3D shapes instead? To answer this, we propose XDGAN, an effective and fast method for applying 2D image GAN architectures to the generation of 3D object geometry combined with additional surface attributes, like color textures and normals. Specifically, we propose a novel method to convert 3D shapes into compact 1-channel geometry images and leverage StyleGAN3 and image-to-image translation networks to generate 3D objects in 2D space. The generated geometry images are quick to convert to 3D meshes, enabling real-time 3D object synthesis, visualization and interactive editing. Moreover, the use of standard 2D architectures can help bring more 2D advances into the 3D realm. We show both quantitatively and qualitatively that our method is highly effective at various tasks such as 3D shape generation, single view reconstruction and shape manipulation, while being significantly faster and more flexible compared to recent 3D generative models.
Hierarchical Neural Implicit Pose Network for Animation and Motion Retargeting
Dec 02, 2021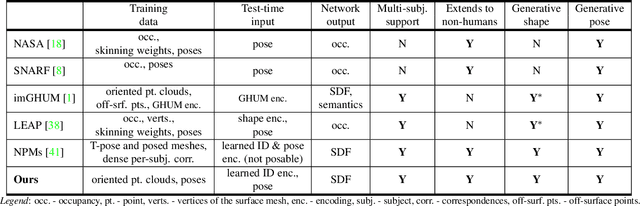
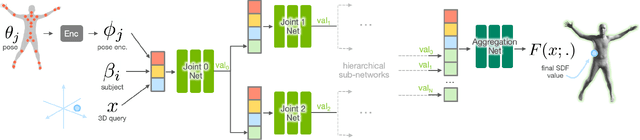
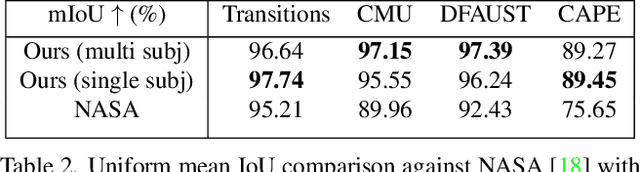
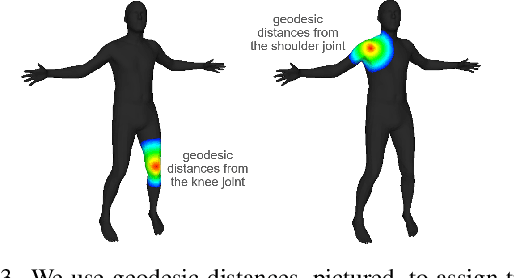
We present HIPNet, a neural implicit pose network trained on multiple subjects across many poses. HIPNet can disentangle subject-specific details from pose-specific details, effectively enabling us to retarget motion from one subject to another or to animate between keyframes through latent space interpolation. To this end, we employ a hierarchical skeleton-based representation to learn a signed distance function on a canonical unposed space. This joint-based decomposition enables us to represent subtle details that are local to the space around the body joint. Unlike previous neural implicit method that requires ground-truth SDF for training, our model we only need a posed skeleton and the point cloud for training, and we have no dependency on a traditional parametric model or traditional skinning approaches. We achieve state-of-the-art results on various single-subject and multi-subject benchmarks.
ATISS: Autoregressive Transformers for Indoor Scene Synthesis
Oct 07, 2021

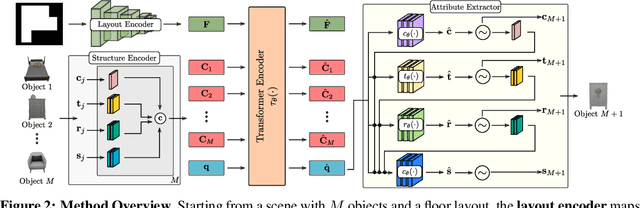
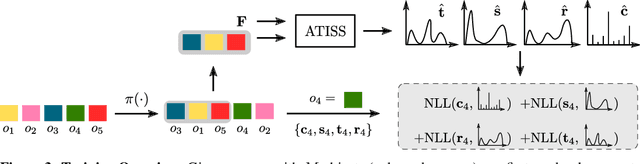
The ability to synthesize realistic and diverse indoor furniture layouts automatically or based on partial input, unlocks many applications, from better interactive 3D tools to data synthesis for training and simulation. In this paper, we present ATISS, a novel autoregressive transformer architecture for creating diverse and plausible synthetic indoor environments, given only the room type and its floor plan. In contrast to prior work, which poses scene synthesis as sequence generation, our model generates rooms as unordered sets of objects. We argue that this formulation is more natural, as it makes ATISS generally useful beyond fully automatic room layout synthesis. For example, the same trained model can be used in interactive applications for general scene completion, partial room re-arrangement with any objects specified by the user, as well as object suggestions for any partial room. To enable this, our model leverages the permutation equivariance of the transformer when conditioning on the partial scene, and is trained to be permutation-invariant across object orderings. Our model is trained end-to-end as an autoregressive generative model using only labeled 3D bounding boxes as supervision. Evaluations on four room types in the 3D-FRONT dataset demonstrate that our model consistently generates plausible room layouts that are more realistic than existing methods. In addition, it has fewer parameters, is simpler to implement and train and runs up to 8 times faster than existing methods.
3DStyleNet: Creating 3D Shapes with Geometric and Texture Style Variations
Aug 30, 2021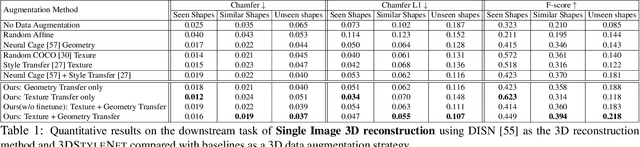
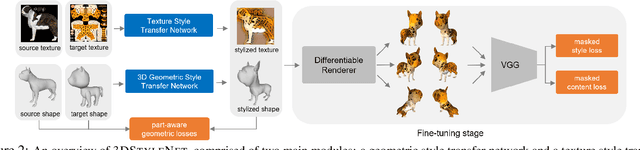
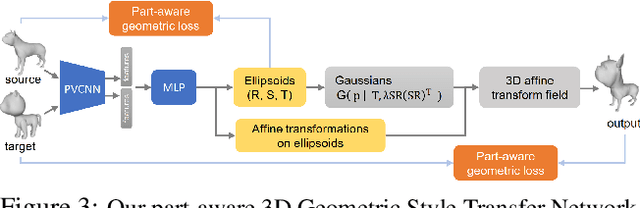
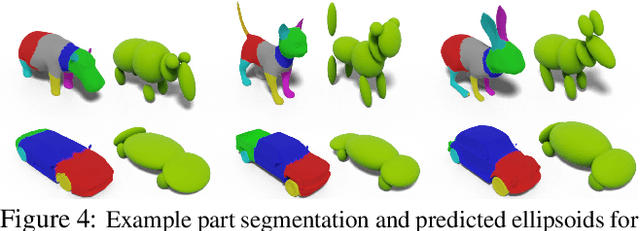
We propose a method to create plausible geometric and texture style variations of 3D objects in the quest to democratize 3D content creation. Given a pair of textured source and target objects, our method predicts a part-aware affine transformation field that naturally warps the source shape to imitate the overall geometric style of the target. In addition, the texture style of the target is transferred to the warped source object with the help of a multi-view differentiable renderer. Our model, 3DStyleNet, is composed of two sub-networks trained in two stages. First, the geometric style network is trained on a large set of untextured 3D shapes. Second, we jointly optimize our geometric style network and a pre-trained image style transfer network with losses defined over both the geometry and the rendering of the result. Given a small set of high-quality textured objects, our method can create many novel stylized shapes, resulting in effortless 3D content creation and style-ware data augmentation. We showcase our approach qualitatively on 3D content stylization, and provide user studies to validate the quality of our results. In addition, our method can serve as a valuable tool to create 3D data augmentations for computer vision tasks. Extensive quantitative analysis shows that 3DStyleNet outperforms alternative data augmentation techniques for the downstream task of single-image 3D reconstruction.
UniCon: Universal Neural Controller For Physics-based Character Motion
Nov 30, 2020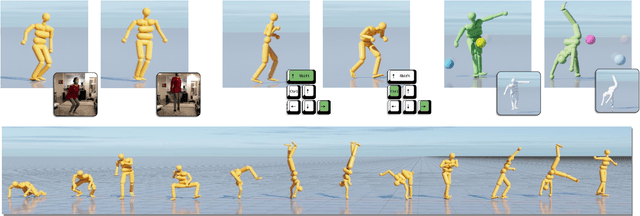
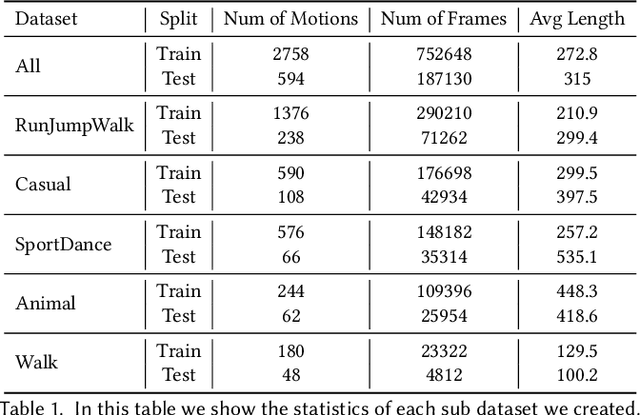
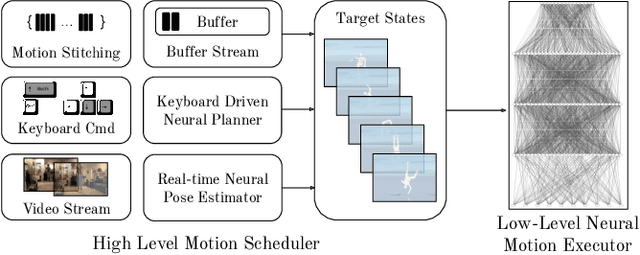

The field of physics-based animation is gaining importance due to the increasing demand for realism in video games and films, and has recently seen wide adoption of data-driven techniques, such as deep reinforcement learning (RL), which learn control from (human) demonstrations. While RL has shown impressive results at reproducing individual motions and interactive locomotion, existing methods are limited in their ability to generalize to new motions and their ability to compose a complex motion sequence interactively. In this paper, we propose a physics-based universal neural controller (UniCon) that learns to master thousands of motions with different styles by learning on large-scale motion datasets. UniCon is a two-level framework that consists of a high-level motion scheduler and an RL-powered low-level motion executor, which is our key innovation. By systematically analyzing existing multi-motion RL frameworks, we introduce a novel objective function and training techniques which make a significant leap in performance. Once trained, our motion executor can be combined with different high-level schedulers without the need for retraining, enabling a variety of real-time interactive applications. We show that UniCon can support keyboard-driven control, compose motion sequences drawn from a large pool of locomotion and acrobatics skills and teleport a person captured on video to a physics-based virtual avatar. Numerical and qualitative results demonstrate a significant improvement in efficiency, robustness and generalizability of UniCon over prior state-of-the-art, showcasing transferability to unseen motions, unseen humanoid models and unseen perturbation.
Neural Turtle Graphics for Modeling City Road Layouts
Oct 04, 2019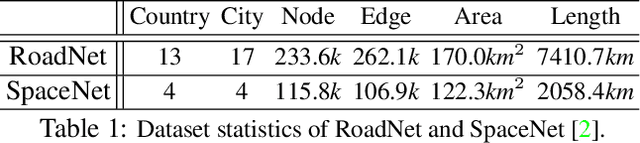
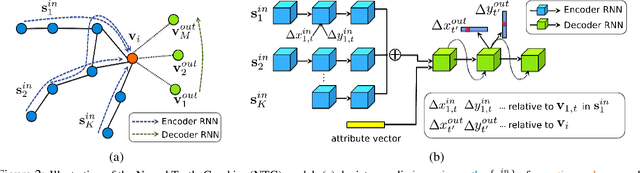
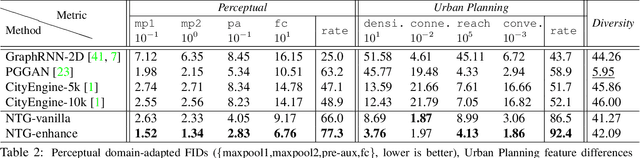

We propose Neural Turtle Graphics (NTG), a novel generative model for spatial graphs, and demonstrate its applications in modeling city road layouts. Specifically, we represent the road layout using a graph where nodes in the graph represent control points and edges in the graph represent road segments. NTG is a sequential generative model parameterized by a neural network. It iteratively generates a new node and an edge connecting to an existing node conditioned on the current graph. We train NTG on Open Street Map data and show that it outperforms existing approaches using a set of diverse performance metrics. Moreover, our method allows users to control styles of generated road layouts mimicking existing cities as well as to sketch parts of the city road layout to be synthesized. In addition to synthesis, the proposed NTG finds uses in an analytical task of aerial road parsing. Experimental results show that it achieves state-of-the-art performance on the SpaceNet dataset.
Color Sails: Discrete-Continuous Palettes for Deep Color Exploration
Jun 07, 2018
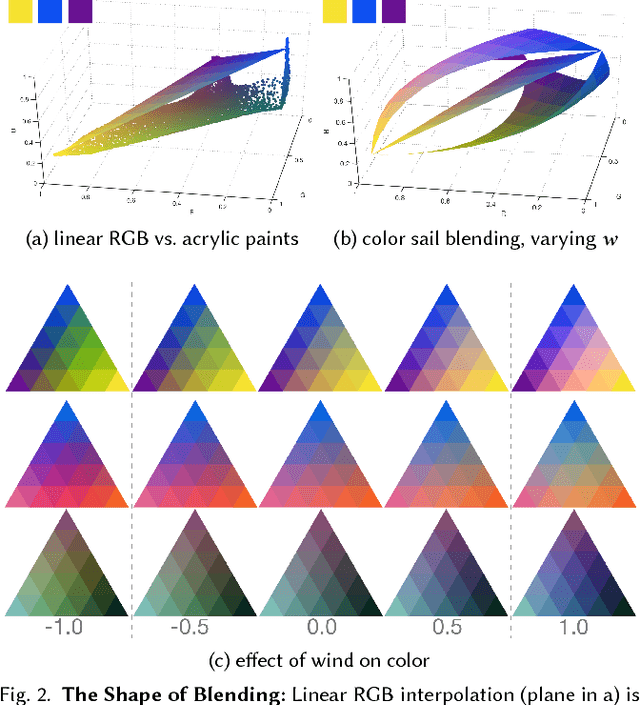
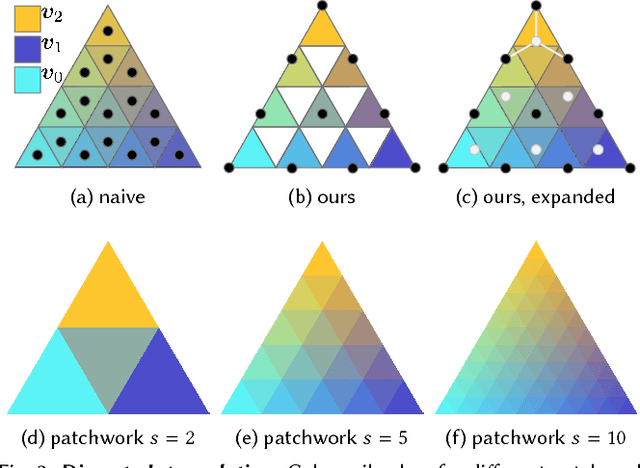
We present color sails, a discrete-continuous color gamut representation that extends the color gradient analogy to three dimensions and allows interactive control of the color blending behavior. Our representation models a wide variety of color distributions in a compact manner, and lends itself to applications such as color exploration for graphic design, illustration and similar fields. We propose a Neural Network that can fit a color sail to any image. Then, the user can adjust color sail parameters to change the base colors, their blending behavior and the number of colors, exploring a wide range of options for the original design. In addition, we propose a Deep Learning model that learns to automatically segment an image into color-compatible alpha masks, each equipped with its own color sail. This allows targeted color exploration by either editing their corresponding color sails or using standard software packages. Our model is trained on a custom diverse dataset of art and design. We provide both quantitative evaluations, and a user study, demonstrating the effectiveness of color sail interaction. Interactive demos are available at www.colorsails.com.
Large Scale Language Modeling in Automatic Speech Recognition
Oct 31, 2012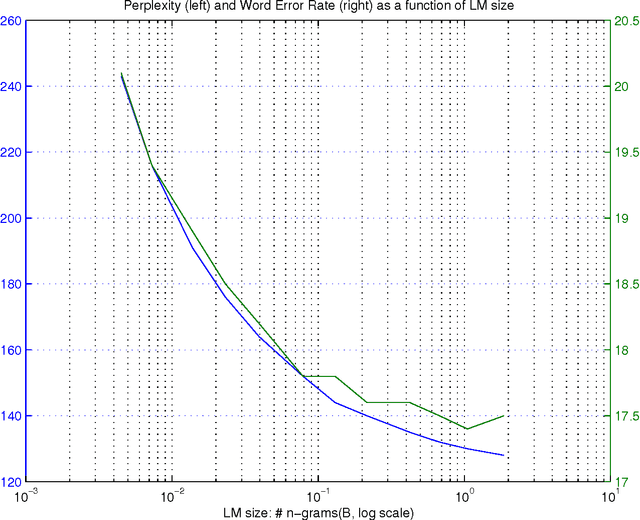
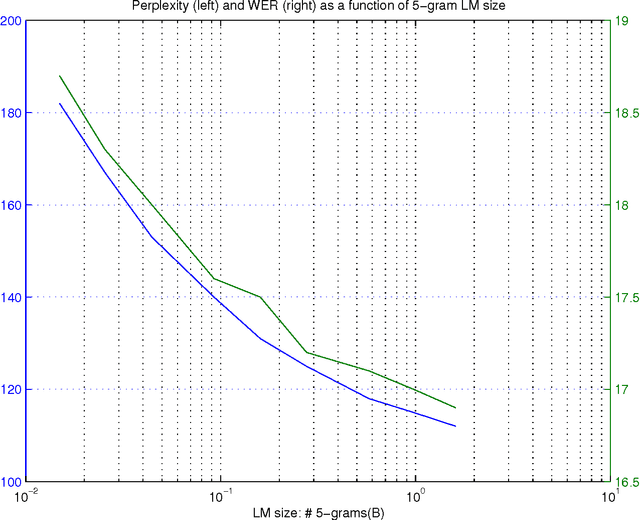


Large language models have been proven quite beneficial for a variety of automatic speech recognition tasks in Google. We summarize results on Voice Search and a few YouTube speech transcription tasks to highlight the impact that one can expect from increasing both the amount of training data, and the size of the language model estimated from such data. Depending on the task, availability and amount of training data used, language model size and amount of work and care put into integrating them in the lattice rescoring step we observe reductions in word error rate between 6% and 10% relative, for systems on a wide range of operating points between 17% and 52% word error rate.