Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Scale Language Modeling in Automatic Speech Recognition
Paper and Code
Oct 31, 2012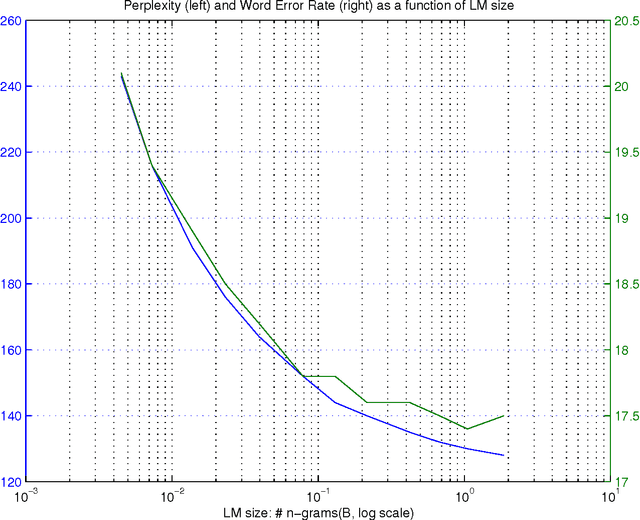
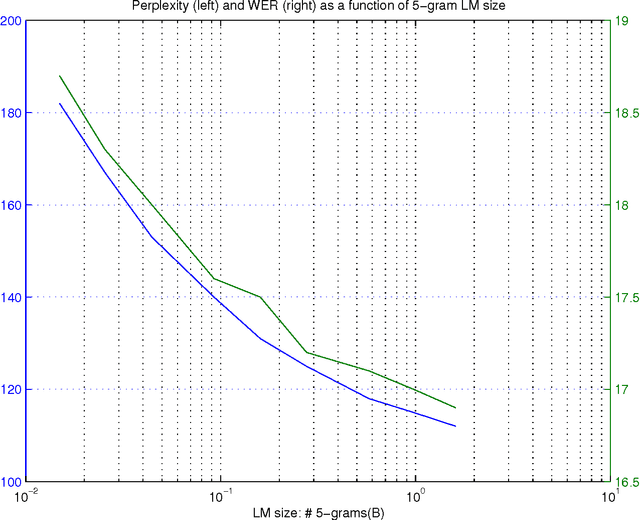


Large language models have been proven quite beneficial for a variety of automatic speech recognition tasks in Google. We summarize results on Voice Search and a few YouTube speech transcription tasks to highlight the impact that one can expect from increasing both the amount of training data, and the size of the language model estimated from such data. Depending on the task, availability and amount of training data used, language model size and amount of work and care put into integrating them in the lattice rescoring step we observe reductions in word error rate between 6% and 10% relative, for systems on a wide range of operating points between 17% and 52% word error rate.
View paper on