 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate Failure Prediction in Agents Does Not Imply Effective Failure Prevention
Feb 03, 2026Proactive interventions by LLM critic models are often assumed to improve reliability, yet their effects at deployment time are poorly understood. We show that a binary LLM critic with strong offline accuracy (AUROC 0.94) can nevertheless cause severe performance degradation, inducing a 26 percentage point (pp) collapse on one model while affecting another by near zero pp. This variability demonstrates that LLM critic accuracy alone is insufficient to determine whether intervention is safe. We identify a disruption-recovery tradeoff: interventions may recover failing trajectories but also disrupt trajectories that would have succeeded. Based on this insight, we propose a pre-deployment test that uses a small pilot of 50 tasks to estimate whether intervention is likely to help or harm, without requiring full deployment. Across benchmarks, the test correctly anticipates outcomes: intervention degrades performance on high-success tasks (0 to -26 pp), while yielding a modest improvement on the high-failure ALFWorld benchmark (+2.8 pp, p=0.014). The primary value of our framework is therefore identifying when not to intervene, preventing severe regressions before deployment.
Llama 2: Open Foundation and Fine-Tuned Chat Models
Jul 19, 2023



In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. Our models outperform open-source chat models on most benchmarks we tested, and based on our human evaluations for helpfulness and safety, may be a suitable substitute for closed-source models. We provide a detailed description of our approach to fine-tuning and safety improvements of Llama 2-Chat in order to enable the community to build on our work and contribute to the responsible development of LLMs.
Exploring Dual Encoder Architectures for Question Answering
Apr 14, 2022
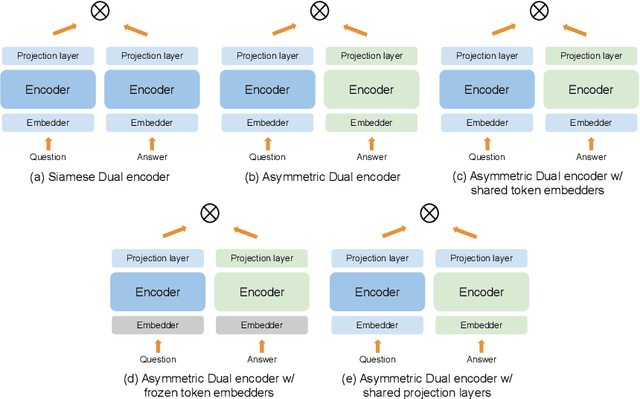
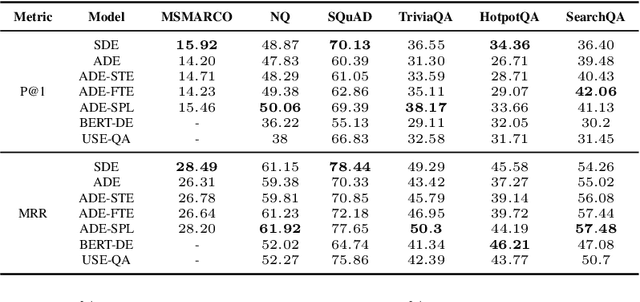

Dual encoders have been used for question-answering (QA) and information retrieval (IR) tasks with good results. There are two major types of dual encoders, Siamese Dual Encoders (SDE), with parameters shared across two encoders, and Asymmetric Dual Encoder (ADE), with two distinctly parameterized encoders. In this work, we explore the dual encoder architectures for QA retrieval tasks. By evaluating on MS MARCO and the MultiReQA benchmark, we show that SDE performs significantly better than ADE. We further propose three different improved versions of ADEs. Based on the evaluation of QA retrieval tasks and direct analysis of the embeddings, we demonstrate that sharing parameters in projection layers would enable ADEs to perform competitively with SDEs.
Large Scale Language Modeling in Automatic Speech Recognition
Oct 31, 2012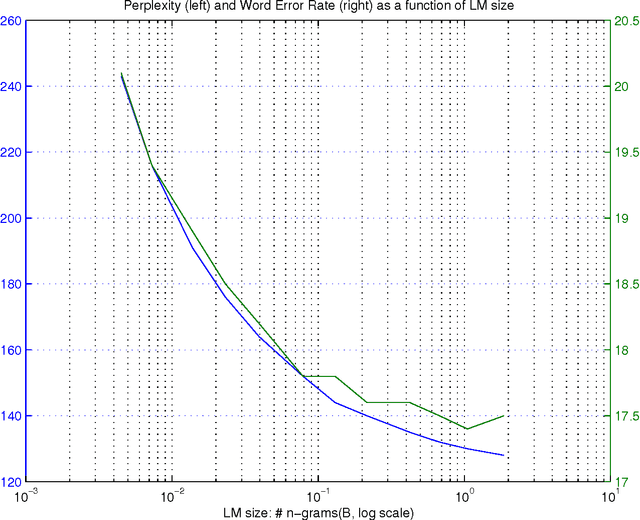
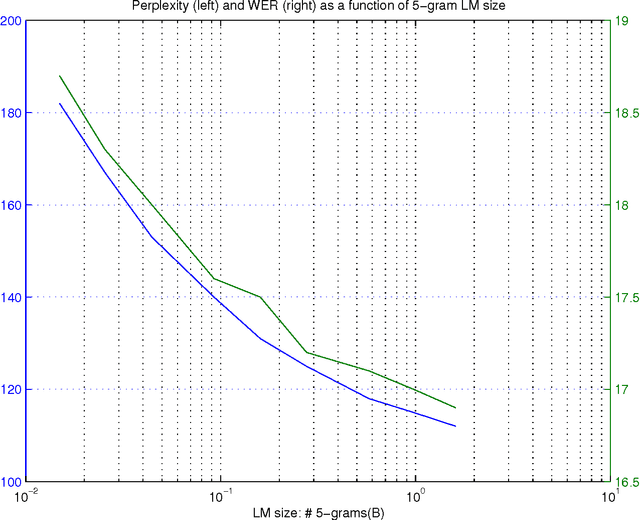


Large language models have been proven quite beneficial for a variety of automatic speech recognition tasks in Google. We summarize results on Voice Search and a few YouTube speech transcription tasks to highlight the impact that one can expect from increasing both the amount of training data, and the size of the language model estimated from such data. Depending on the task, availability and amount of training data used, language model size and amount of work and care put into integrating them in the lattice rescoring step we observe reductions in word error rate between 6% and 10% relative, for systems on a wide range of operating points between 17% and 52% word error rate.