 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate Failure Prediction in Agents Does Not Imply Effective Failure Prevention
Feb 03, 2026Proactive interventions by LLM critic models are often assumed to improve reliability, yet their effects at deployment time are poorly understood. We show that a binary LLM critic with strong offline accuracy (AUROC 0.94) can nevertheless cause severe performance degradation, inducing a 26 percentage point (pp) collapse on one model while affecting another by near zero pp. This variability demonstrates that LLM critic accuracy alone is insufficient to determine whether intervention is safe. We identify a disruption-recovery tradeoff: interventions may recover failing trajectories but also disrupt trajectories that would have succeeded. Based on this insight, we propose a pre-deployment test that uses a small pilot of 50 tasks to estimate whether intervention is likely to help or harm, without requiring full deployment. Across benchmarks, the test correctly anticipates outcomes: intervention degrades performance on high-success tasks (0 to -26 pp), while yielding a modest improvement on the high-failure ALFWorld benchmark (+2.8 pp, p=0.014). The primary value of our framework is therefore identifying when not to intervene, preventing severe regressions before deployment.
OmniACT: A Dataset and Benchmark for Enabling Multimodal Generalist Autonomous Agents for Desktop and Web
Feb 28, 2024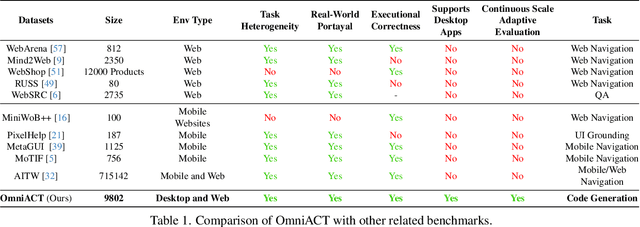
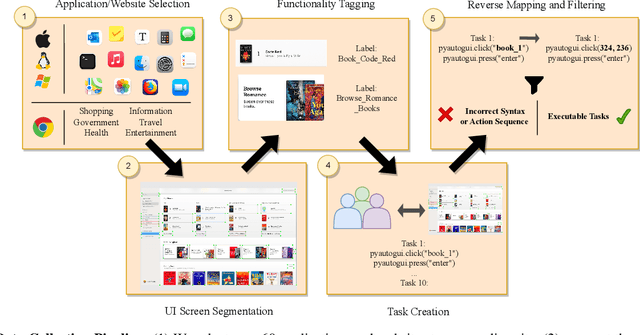

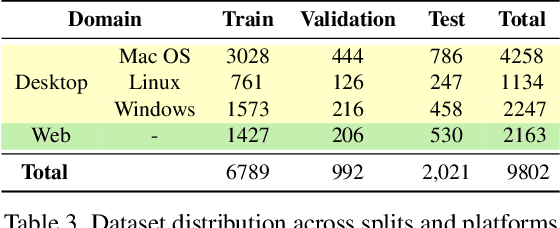
For decades, human-computer interaction has fundamentally been manual. Even today, almost all productive work done on the computer necessitates human input at every step. Autonomous virtual agents represent an exciting step in automating many of these menial tasks. Virtual agents would empower users with limited technical proficiency to harness the full possibilities of computer systems. They could also enable the efficient streamlining of numerous computer tasks, ranging from calendar management to complex travel bookings, with minimal human intervention. In this paper, we introduce OmniACT, the first-of-a-kind dataset and benchmark for assessing an agent's capability to generate executable programs to accomplish computer tasks. Our scope extends beyond traditional web automation, covering a diverse range of desktop applications. The dataset consists of fundamental tasks such as "Play the next song", as well as longer horizon tasks such as "Send an email to John Doe mentioning the time and place to meet". Specifically, given a pair of screen image and a visually-grounded natural language task, the goal is to generate a script capable of fully executing the task. We run several strong baseline language model agents on our benchmark. The strongest baseline, GPT-4, performs the best on our benchmark However, its performance level still reaches only 15% of the human proficiency in generating executable scripts capable of completing the task, demonstrating the challenge of our task for conventional web agents. Our benchmark provides a platform to measure and evaluate the progress of language model agents in automating computer tasks and motivates future work towards building multimodal models that bridge large language models and the visual grounding of computer screens.