 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHELPER-X: A Unified Instructable Embodied Agent to Tackle Four Interactive Vision-Language Domains with Memory-Augmented Language Models
Apr 29, 2024Recent research on instructable agents has used memory-augmented Large Language Models (LLMs) as task planners, a technique that retrieves language-program examples relevant to the input instruction and uses them as in-context examples in the LLM prompt to improve the performance of the LLM in inferring the correct action and task plans. In this technical report, we extend the capabilities of HELPER, by expanding its memory with a wider array of examples and prompts, and by integrating additional APIs for asking questions. This simple expansion of HELPER into a shared memory enables the agent to work across the domains of executing plans from dialogue, natural language instruction following, active question asking, and commonsense room reorganization. We evaluate the agent on four diverse interactive visual-language embodied agent benchmarks: ALFRED, TEACh, DialFRED, and the Tidy Task. HELPER-X achieves few-shot, state-of-the-art performance across these benchmarks using a single agent, without requiring in-domain training, and remains competitive with agents that have undergone in-domain training.
OmniACT: A Dataset and Benchmark for Enabling Multimodal Generalist Autonomous Agents for Desktop and Web
Feb 28, 2024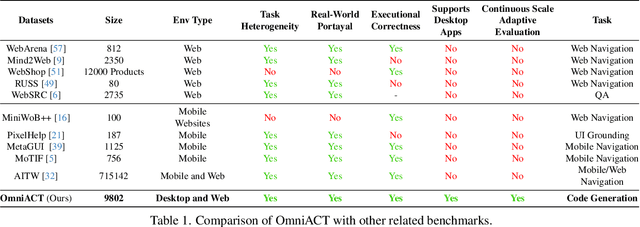
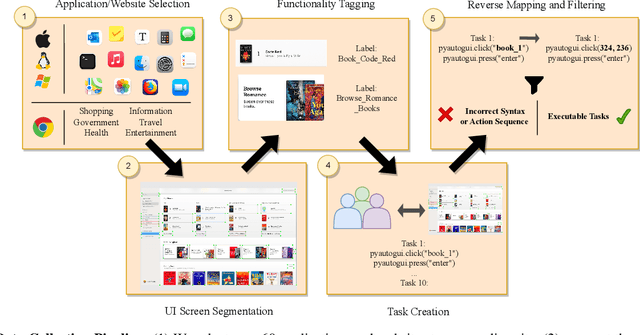

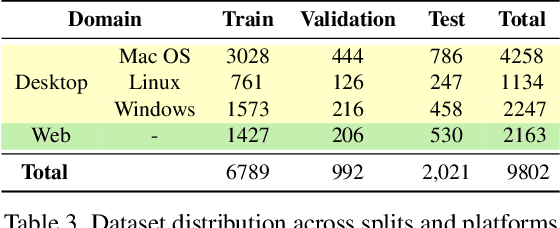
For decades, human-computer interaction has fundamentally been manual. Even today, almost all productive work done on the computer necessitates human input at every step. Autonomous virtual agents represent an exciting step in automating many of these menial tasks. Virtual agents would empower users with limited technical proficiency to harness the full possibilities of computer systems. They could also enable the efficient streamlining of numerous computer tasks, ranging from calendar management to complex travel bookings, with minimal human intervention. In this paper, we introduce OmniACT, the first-of-a-kind dataset and benchmark for assessing an agent's capability to generate executable programs to accomplish computer tasks. Our scope extends beyond traditional web automation, covering a diverse range of desktop applications. The dataset consists of fundamental tasks such as "Play the next song", as well as longer horizon tasks such as "Send an email to John Doe mentioning the time and place to meet". Specifically, given a pair of screen image and a visually-grounded natural language task, the goal is to generate a script capable of fully executing the task. We run several strong baseline language model agents on our benchmark. The strongest baseline, GPT-4, performs the best on our benchmark However, its performance level still reaches only 15% of the human proficiency in generating executable scripts capable of completing the task, demonstrating the challenge of our task for conventional web agents. Our benchmark provides a platform to measure and evaluate the progress of language model agents in automating computer tasks and motivates future work towards building multimodal models that bridge large language models and the visual grounding of computer screens.
MoEmo Vision Transformer: Integrating Cross-Attention and Movement Vectors in 3D Pose Estimation for HRI Emotion Detection
Oct 15, 2023Emotion detection presents challenges to intelligent human-robot interaction (HRI). Foundational deep learning techniques used in emotion detection are limited by information-constrained datasets or models that lack the necessary complexity to learn interactions between input data elements, such as the the variance of human emotions across different contexts. In the current effort, we introduce 1) MoEmo (Motion to Emotion), a cross-attention vision transformer (ViT) for human emotion detection within robotics systems based on 3D human pose estimations across various contexts, and 2) a data set that offers full-body videos of human movement and corresponding emotion labels based on human gestures and environmental contexts. Compared to existing approaches, our method effectively leverages the subtle connections between movement vectors of gestures and environmental contexts through the use of cross-attention on the extracted movement vectors of full-body human gestures/poses and feature maps of environmental contexts. We implement a cross-attention fusion model to combine movement vectors and environment contexts into a joint representation to derive emotion estimation. Leveraging our Naturalistic Motion Database, we train the MoEmo system to jointly analyze motion and context, yielding emotion detection that outperforms the current state-of-the-art.
* IEEE/RSJ International Conference on Intelligent Robots (IROS), Detroit, Michigan
SummQA at MEDIQA-Chat 2023:In-Context Learning with GPT-4 for Medical Summarization
Jun 30, 2023



Medical dialogue summarization is challenging due to the unstructured nature of medical conversations, the use of medical terminology in gold summaries, and the need to identify key information across multiple symptom sets. We present a novel system for the Dialogue2Note Medical Summarization tasks in the MEDIQA 2023 Shared Task. Our approach for section-wise summarization (Task A) is a two-stage process of selecting semantically similar dialogues and using the top-k similar dialogues as in-context examples for GPT-4. For full-note summarization (Task B), we use a similar solution with k=1. We achieved 3rd place in Task A (2nd among all teams), 4th place in Task B Division Wise Summarization (2nd among all teams), 15th place in Task A Section Header Classification (9th among all teams), and 8th place among all teams in Task B. Our results highlight the effectiveness of few-shot prompting for this task, though we also identify several weaknesses of prompting-based approaches. We compare GPT-4 performance with several finetuned baselines. We find that GPT-4 summaries are more abstractive and shorter. We make our code publicly available.
Hate Me Not: Detecting Hate Inducing Memes in Code Switched Languages
Apr 24, 2022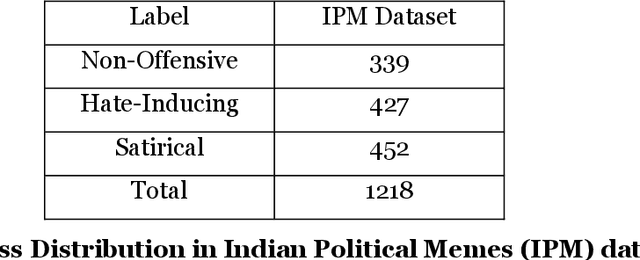


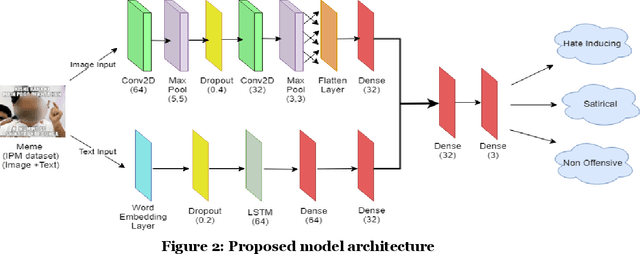
The rise in the number of social media users has led to an increase in the hateful content posted online. In countries like India, where multiple languages are spoken, these abhorrent posts are from an unusual blend of code-switched languages. This hate speech is depicted with the help of images to form "Memes" which create a long-lasting impact on the human mind. In this paper, we take up the task of hate and offense detection from multimodal data, i.e. images (Memes) that contain text in code-switched languages. We firstly present a novel triply annotated Indian political Memes (IPM) dataset, which comprises memes from various Indian political events that have taken place post-independence and are classified into three distinct categories. We also propose a binary-channelled CNN cum LSTM based model to process the images using the CNN model and text using the LSTM model to get state-of-the-art results for this task.
Mind Your Language: Abuse and Offense Detection for Code-Switched Languages
Sep 23, 2018
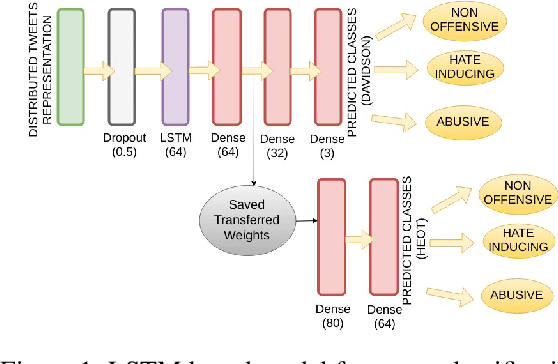


In multilingual societies like the Indian subcontinent, use of code-switched languages is much popular and convenient for the users. In this paper, we study offense and abuse detection in the code-switched pair of Hindi and English (i.e. Hinglish), the pair that is the most spoken. The task is made difficult due to non-fixed grammar, vocabulary, semantics and spellings of Hinglish language. We apply transfer learning and make a LSTM based model for hate speech classification. This model surpasses the performance shown by the current best models to establish itself as the state-of-the-art in the unexplored domain of Hinglish offensive text classification.We also release our model and the embeddings trained for research purposes