 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRumour detection using graph neural network and oversampling in benchmark Twitter dataset
Dec 20, 2022Recently, online social media has become a primary source for new information and misinformation or rumours. In the absence of an automatic rumour detection system the propagation of rumours has increased manifold leading to serious societal damages. In this work, we propose a novel method for building automatic rumour detection system by focusing on oversampling to alleviating the fundamental challenges of class imbalance in rumour detection task. Our oversampling method relies on contextualised data augmentation to generate synthetic samples for underrepresented classes in the dataset. The key idea exploits selection of tweets in a thread for augmentation which can be achieved by introducing a non-random selection criteria to focus the augmentation process on relevant tweets. Furthermore, we propose two graph neural networks(GNN) to model non-linear conversations on a thread. To enhance the tweet representations in our method we employed a custom feature selection technique based on state-of-the-art BERTweet model. Experiments of three publicly available datasets confirm that 1) our GNN models outperform the the current state-of-the-art classifiers by more than 20%(F1-score); 2) our oversampling technique increases the model performance by more than 9%;(F1-score) 3) focusing on relevant tweets for data augmentation via non-random selection criteria can further improve the results; and 4) our method has superior capabilities to detect rumours at very early stage.
Hate Me Not: Detecting Hate Inducing Memes in Code Switched Languages
Apr 24, 2022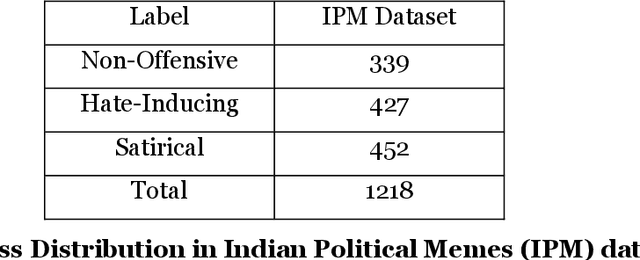


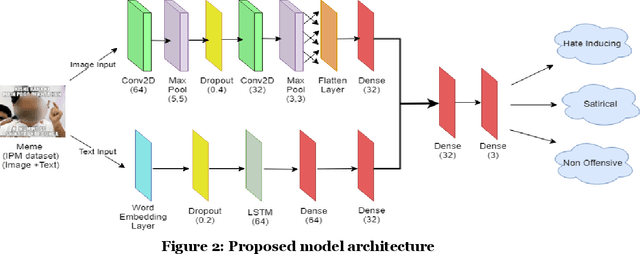
The rise in the number of social media users has led to an increase in the hateful content posted online. In countries like India, where multiple languages are spoken, these abhorrent posts are from an unusual blend of code-switched languages. This hate speech is depicted with the help of images to form "Memes" which create a long-lasting impact on the human mind. In this paper, we take up the task of hate and offense detection from multimodal data, i.e. images (Memes) that contain text in code-switched languages. We firstly present a novel triply annotated Indian political Memes (IPM) dataset, which comprises memes from various Indian political events that have taken place post-independence and are classified into three distinct categories. We also propose a binary-channelled CNN cum LSTM based model to process the images using the CNN model and text using the LSTM model to get state-of-the-art results for this task.