Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind Your Language: Abuse and Offense Detection for Code-Switched Languages
Paper and Code

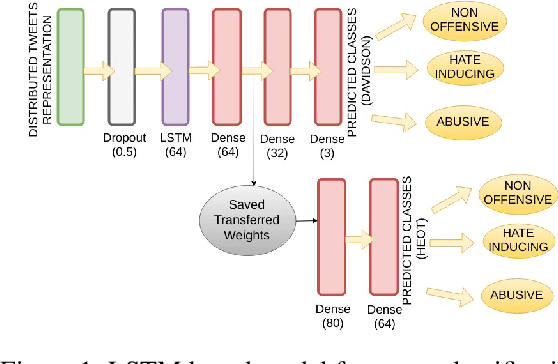


In multilingual societies like the Indian subcontinent, use of code-switched languages is much popular and convenient for the users. In this paper, we study offense and abuse detection in the code-switched pair of Hindi and English (i.e. Hinglish), the pair that is the most spoken. The task is made difficult due to non-fixed grammar, vocabulary, semantics and spellings of Hinglish language. We apply transfer learning and make a LSTM based model for hate speech classification. This model surpasses the performance shown by the current best models to establish itself as the state-of-the-art in the unexplored domain of Hinglish offensive text classification.We also release our model and the embeddings trained for research purposes
View paper on