 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReflect, Retry, Reward: Self-Improving LLMs via Reinforcement Learning
May 30, 2025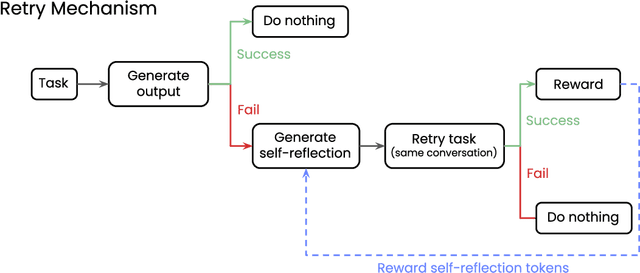
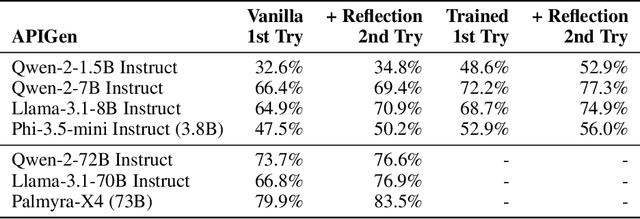
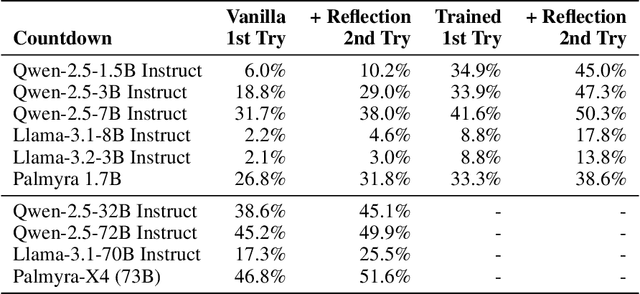
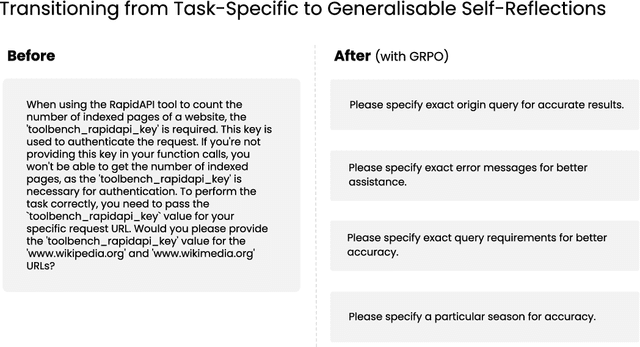
We explore a method for improving the performance of large language models through self-reflection and reinforcement learning. By incentivizing the model to generate better self-reflections when it answers incorrectly, we demonstrate that a model's ability to solve complex, verifiable tasks can be enhanced even when generating synthetic data is infeasible and only binary feedback is available. Our framework operates in two stages: first, upon failing a given task, the model generates a self-reflective commentary analyzing its previous attempt; second, the model is given another attempt at the task with the self-reflection in context. If the subsequent attempt succeeds, the tokens generated during the self-reflection phase are rewarded. Our experimental results show substantial performance gains across a variety of model architectures, as high as 34.7% improvement at math equation writing and 18.1% improvement at function calling. Notably, smaller fine-tuned models (1.5 billion to 7 billion parameters) outperform models in the same family that are 10 times larger. Our novel paradigm is thus an exciting pathway to more useful and reliable language models that can self-improve on challenging tasks with limited external feedback.
Expect the Unexpected: FailSafe Long Context QA for Finance
Feb 10, 2025



We propose a new long-context financial benchmark, FailSafeQA, designed to test the robustness and context-awareness of LLMs against six variations in human-interface interactions in LLM-based query-answer systems within finance. We concentrate on two case studies: Query Failure and Context Failure. In the Query Failure scenario, we perturb the original query to vary in domain expertise, completeness, and linguistic accuracy. In the Context Failure case, we simulate the uploads of degraded, irrelevant, and empty documents. We employ the LLM-as-a-Judge methodology with Qwen2.5-72B-Instruct and use fine-grained rating criteria to define and calculate Robustness, Context Grounding, and Compliance scores for 24 off-the-shelf models. The results suggest that although some models excel at mitigating input perturbations, they must balance robust answering with the ability to refrain from hallucinating. Notably, Palmyra-Fin-128k-Instruct, recognized as the most compliant model, maintained strong baseline performance but encountered challenges in sustaining robust predictions in 17% of test cases. On the other hand, the most robust model, OpenAI o3-mini, fabricated information in 41% of tested cases. The results demonstrate that even high-performing models have significant room for improvement and highlight the role of FailSafeQA as a tool for developing LLMs optimized for dependability in financial applications. The dataset is available at: https://huggingface.co/datasets/Writer/FailSafeQA
Writing in the Margins: Better Inference Pattern for Long Context Retrieval
Aug 27, 2024



In this paper, we introduce Writing in the Margins (WiM), a new inference pattern for Large Language Models designed to optimize the handling of long input sequences in retrieval-oriented tasks. This approach leverages the chunked prefill of the key-value cache to perform segment-wise inference, which enables efficient processing of extensive contexts along with the generation and classification of intermediate information ("margins") that guide the model towards specific tasks. This method increases computational overhead marginally while significantly enhancing the performance of off-the-shelf models without the need for fine-tuning. Specifically, we observe that WiM provides an average enhancement of 7.5% in accuracy for reasoning skills (HotpotQA, MultiHop-RAG) and more than a 30.0% increase in the F1-score for aggregation tasks (CWE). Additionally, we show how the proposed pattern fits into an interactive retrieval design that provides end-users with ongoing updates about the progress of context processing, and pinpoints the integration of relevant information into the final response. We release our implementation of WiM using Hugging Face Transformers library at https://github.com/writer/writing-in-the-margins.
OmniACT: A Dataset and Benchmark for Enabling Multimodal Generalist Autonomous Agents for Desktop and Web
Feb 28, 2024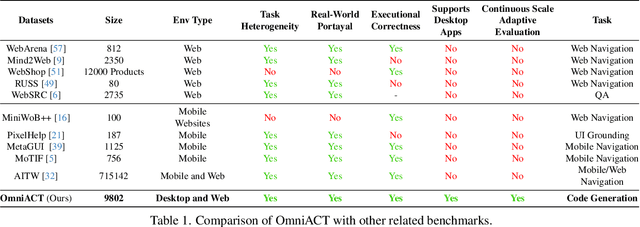
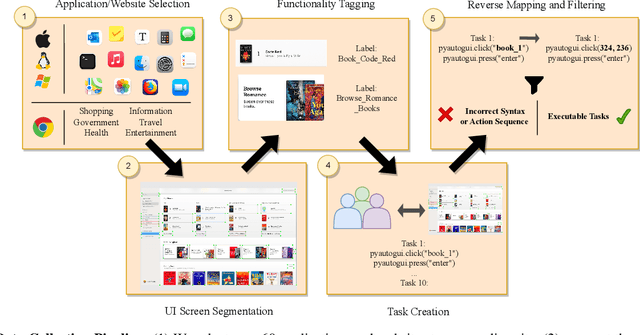

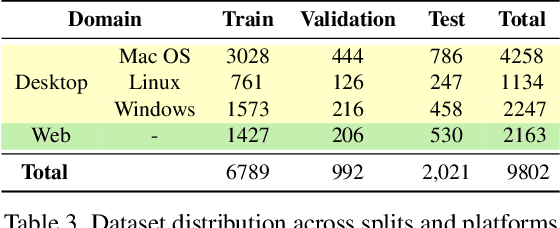
For decades, human-computer interaction has fundamentally been manual. Even today, almost all productive work done on the computer necessitates human input at every step. Autonomous virtual agents represent an exciting step in automating many of these menial tasks. Virtual agents would empower users with limited technical proficiency to harness the full possibilities of computer systems. They could also enable the efficient streamlining of numerous computer tasks, ranging from calendar management to complex travel bookings, with minimal human intervention. In this paper, we introduce OmniACT, the first-of-a-kind dataset and benchmark for assessing an agent's capability to generate executable programs to accomplish computer tasks. Our scope extends beyond traditional web automation, covering a diverse range of desktop applications. The dataset consists of fundamental tasks such as "Play the next song", as well as longer horizon tasks such as "Send an email to John Doe mentioning the time and place to meet". Specifically, given a pair of screen image and a visually-grounded natural language task, the goal is to generate a script capable of fully executing the task. We run several strong baseline language model agents on our benchmark. The strongest baseline, GPT-4, performs the best on our benchmark However, its performance level still reaches only 15% of the human proficiency in generating executable scripts capable of completing the task, demonstrating the challenge of our task for conventional web agents. Our benchmark provides a platform to measure and evaluate the progress of language model agents in automating computer tasks and motivates future work towards building multimodal models that bridge large language models and the visual grounding of computer screens.
Becoming self-instruct: introducing early stopping criteria for minimal instruct tuning
Jul 05, 2023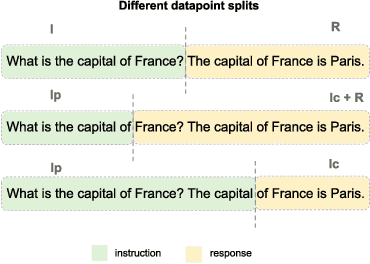
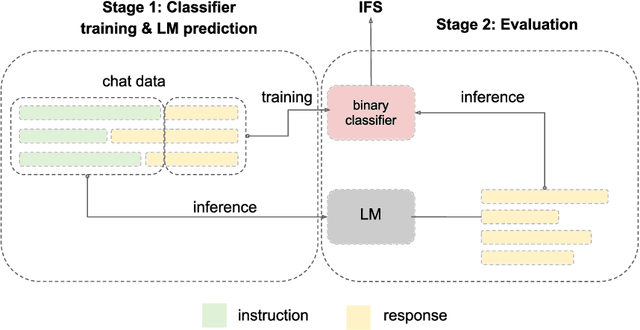
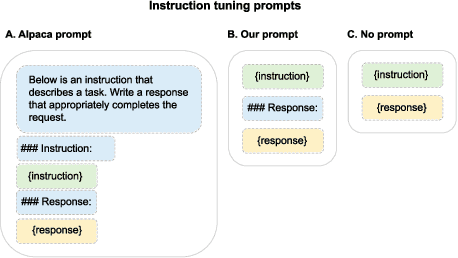
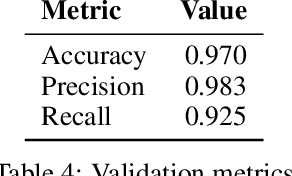
In this paper, we introduce the Instruction Following Score (IFS), a metric that detects language models' ability to follow instructions. The metric has a dual purpose. First, IFS can be used to distinguish between base and instruct models. We benchmark publicly available base and instruct models, and show that the ratio of well formatted responses to partial and full sentences can be an effective measure between those two model classes. Secondly, the metric can be used as an early stopping criteria for instruct tuning. We compute IFS for Supervised Fine-Tuning (SFT) of 7B and 13B LLaMA models, showing that models learn to follow instructions relatively early in the training process, and the further finetuning can result in changes in the underlying base model semantics. As an example of semantics change we show the objectivity of model predictions, as defined by an auxiliary metric ObjecQA. We show that in this particular case, semantic changes are the steepest when the IFS tends to plateau. We hope that decomposing instruct tuning into IFS and semantic factors starts a new trend in better controllable instruct tuning and opens possibilities for designing minimal instruct interfaces querying foundation models.