 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBecoming self-instruct: introducing early stopping criteria for minimal instruct tuning
Paper and Code
Jul 05, 2023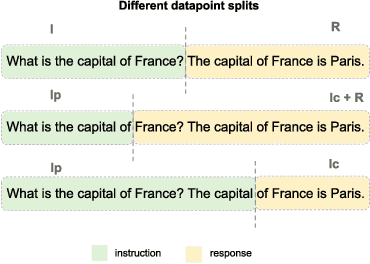
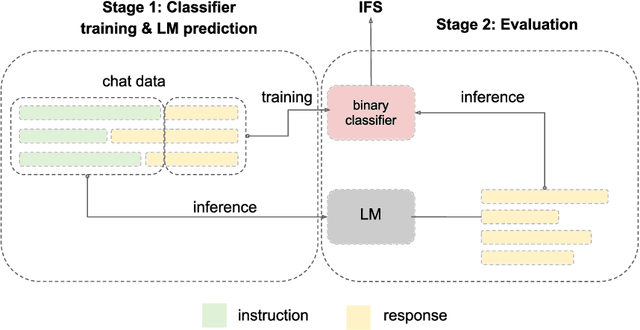
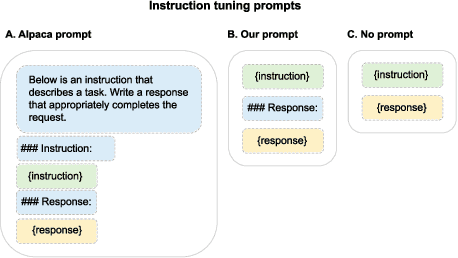
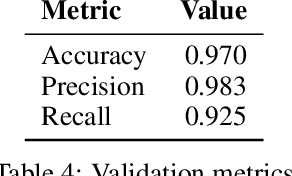
In this paper, we introduce the Instruction Following Score (IFS), a metric that detects language models' ability to follow instructions. The metric has a dual purpose. First, IFS can be used to distinguish between base and instruct models. We benchmark publicly available base and instruct models, and show that the ratio of well formatted responses to partial and full sentences can be an effective measure between those two model classes. Secondly, the metric can be used as an early stopping criteria for instruct tuning. We compute IFS for Supervised Fine-Tuning (SFT) of 7B and 13B LLaMA models, showing that models learn to follow instructions relatively early in the training process, and the further finetuning can result in changes in the underlying base model semantics. As an example of semantics change we show the objectivity of model predictions, as defined by an auxiliary metric ObjecQA. We show that in this particular case, semantic changes are the steepest when the IFS tends to plateau. We hope that decomposing instruct tuning into IFS and semantic factors starts a new trend in better controllable instruct tuning and opens possibilities for designing minimal instruct interfaces querying foundation models.