 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokTalk: Expressive Real-time Facial Animation from Audio-LLM Tokens
May 29, 2026Recent advances in Audio-LLMs like GPT-4o have ushered in an era of conversational interaction with language models. Conversational avatars however, still seem robotic in facial expression and conversational flow, in part due to sequential stages of speech recognition, text generation, turn-based text response, speech synthesis, and audio driven facial animation. Based on our insight that audio-tokens produced by current Audio-LLMs carry sufficient information to reconstruct a plausible facial performance, we present TokTalk, a system that directly outputs expressive facial animation in real-time from streaming audio-tokens. We construct a novel audio-token to 3D facial motion dataset, on which TokTalk is trained using a Chunk-based Conditional Flow Matching model. A lightweight adaptation strategy allows our trained model to seamlessly connect to any token-based Audio-LLM at minimal computational overhead. Our chunk-based processing further enables parametric trade-off between latency and facial quality, shown through ablation studies. We further show that the real-time performance of TokTalk is comparable in latency to prior art solutions, and significantly favorable (via a perceptual study) in terms of quality, expressivity and control of the 3D facial performance. We showcase TokTalk's flexibility using a chatbot Avatar, a voice-driven user Avatar, and an animation Director's interface, as diverse audio-visual face applications.
HalluWorld: A Controlled Benchmark for Hallucination via Reference World Models
May 19, 2026Hallucination remains a central failure mode of large language models, but existing benchmarks operationalize it inconsistently across summarization, question answering, retrieval-augmented generation, and agentic interaction. This fragmentation makes it unclear whether a mitigation that works in one setting reduces hallucinations across contexts. Current benchmarks either require human annotation and fixed references that may be memorized, or rely on observations in settings that are difficult to reproduce. To study root causes, we introduce HalluWorld, an extensible benchmark grounded in an explicit reference-world formulation: a model hallucinates when it produces an observable claim that is false with respect to this world. Building on this view, we construct synthetic and semi-synthetic environments in which the reference world is fully specified, the model's view is controlled, and hallucination labels are generated automatically. HalluWorld spans gridworlds, chess, and realistic terminal tasks, enabling controlled variation of world complexity, observability, temporal change, and source-conflict policy, and disentangling hallucinations into fine-grained error categories. We evaluate frontier and open-weight language models across these settings and find consistent patterns: perceptual hallucination on directly observed information is near-solved for frontier models, while multi-step state tracking and causal forward simulation remain difficult and are not generally solved by extended thinking. In the terminal setting, models also struggle with when to abstain. The uneven profile of failures across probe types and domains suggests that hallucinations arise from distinct failure modes rather than a single capability. Our results suggest that controlled reference worlds offer a scalable and reproducible path toward measuring and reducing hallucinations in modern language models.
Replicable Bandits with UCB based Exploration
Apr 21, 2026We study replicable algorithms for stochastic multi-armed bandits (MAB) and linear bandits with UCB (Upper Confidence Bound) based exploration. A bandit algorithm is $ρ$-replicable if two executions using shared internal randomness but independent reward realizations, produce the same action sequence with probability at least $1-ρ$. Prior work is primarily elimination-based and, in linear bandits with infinitely many actions, relies on discretization, leading to suboptimal dependence on the dimension $d$ and $ρ$. We develop optimistic alternatives for both settings. For stochastic multi-armed bandits, we propose RepUCB, a replicable batched UCB algorithm and show that it attains a regret $O\!\left(\frac{K^2\log^2 T}{ρ^2}\sum_{a:Δ_a>0}\left(Δ_a+\frac{\log(KT\log T)}{Δ_a}\right)\right)$. For stochastic linear bandits, we first introduce RepRidge, a replicable ridge regression estimator that satisfies both a confidence guarantee and a $ρ$-replicability guarantee. Beyond its role in our bandit algorithm, this estimator and its guarantees may also be of independent interest in other statistical estimation settings. We then use RepRidge to design RepLinUCB, a replicable optimistic algorithm for stochastic linear bandits, and show that its regret is bounded by $\widetilde{O}\!\big(\big(d+\frac{d^3}ρ\big)\sqrt{T}\big)$. This improves the best prior regret guarantee by a factor of $O(d/ρ)$, showing that our optimistic algorithm can substantially reduce the price of replicability.
To Memorize or to Retrieve: Scaling Laws for RAG-Considerate Pretraining
Apr 01, 2026Retrieval-augmented generation (RAG) improves language model (LM) performance by providing relevant context at test time for knowledge-intensive situations. However, the relationship between parametric knowledge acquired during pretraining and non-parametric knowledge accessed via retrieval remains poorly understood, especially under fixed data budgets. In this work, we systematically study the trade-off between pretraining corpus size and retrieval store size across a wide range of model and data scales. We train OLMo-2-based LMs ranging from 30M to 3B parameters on up to 100B tokens of DCLM data, while varying both pretraining data scale (1-150x the number of parameters) and retrieval store size (1-20x), and evaluate performance across a diverse suite of benchmarks spanning reasoning, scientific QA, and open-domain QA. We find that retrieval consistently improves performance over parametric-only baselines across model scales and introduce a three-dimensional scaling framework that models performance as a function of model size, pretraining tokens, and retrieval corpus size. This scaling manifold enables us to estimate optimal allocations of a fixed data budget between pretraining and retrieval, revealing that the marginal utility of retrieval depends strongly on model scale, task type, and the degree of pretraining saturation. Our results provide a quantitative foundation for understanding when and how retrieval should complement pretraining, offering practical guidance for allocating data resources in the design of scalable language modeling systems.
Learning to Build Shapes by Extrusion
Jan 30, 2026We introduce Text Encoded Extrusion (TEE), a text-based representation that expresses mesh construction as sequences of face extrusions rather than polygon lists, and a method for generating 3D meshes from TEE using a large language model (LLM). By learning extrusion sequences that assemble a mesh, similar to the way artists create meshes, our approach naturally supports arbitrary output face counts and produces manifold meshes by design, in contrast to recent transformer-based models. The learnt extrusion sequences can also be applied to existing meshes - enabling editing in addition to generation. To train our model, we decompose a library of quadrilateral meshes with non-self-intersecting face loops into constituent loops, which can be viewed as their building blocks, and finetune an LLM on the steps for reassembling the meshes by performing a sequence of extrusions. We demonstrate that our representation enables reconstruction, novel shape synthesis, and the addition of new features to existing meshes.
Model See Model Do: Speech-Driven Facial Animation with Style Control
May 02, 2025Speech-driven 3D facial animation plays a key role in applications such as virtual avatars, gaming, and digital content creation. While existing methods have made significant progress in achieving accurate lip synchronization and generating basic emotional expressions, they often struggle to capture and effectively transfer nuanced performance styles. We propose a novel example-based generation framework that conditions a latent diffusion model on a reference style clip to produce highly expressive and temporally coherent facial animations. To address the challenge of accurately adhering to the style reference, we introduce a novel conditioning mechanism called style basis, which extracts key poses from the reference and additively guides the diffusion generation process to fit the style without compromising lip synchronization quality. This approach enables the model to capture subtle stylistic cues while ensuring that the generated animations align closely with the input speech. Extensive qualitative, quantitative, and perceptual evaluations demonstrate the effectiveness of our method in faithfully reproducing the desired style while achieving superior lip synchronization across various speech scenarios.
Sample-Optimal Agnostic Boosting with Unlabeled Data
Mar 06, 2025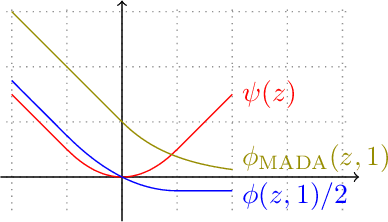

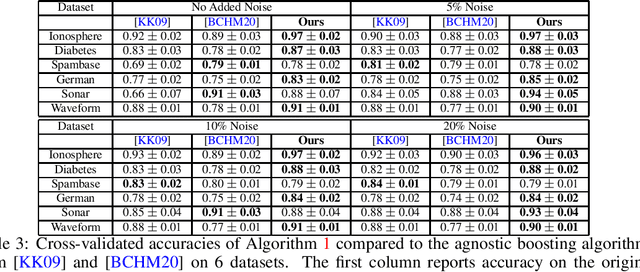
Boosting provides a practical and provably effective framework for constructing accurate learning algorithms from inaccurate rules of thumb. It extends the promise of sample-efficient learning to settings where direct Empirical Risk Minimization (ERM) may not be implementable efficiently. In the realizable setting, boosting is known to offer this computational reprieve without compromising on sample efficiency. However, in the agnostic case, existing boosting algorithms fall short of achieving the optimal sample complexity. This paper highlights an unexpected and previously unexplored avenue of improvement: unlabeled samples. We design a computationally efficient agnostic boosting algorithm that matches the sample complexity of ERM, given polynomially many additional unlabeled samples. In fact, we show that the total number of samples needed, unlabeled and labeled inclusive, is never more than that for the best known agnostic boosting algorithm -- so this result is never worse -- while only a vanishing fraction of these need to be labeled for the algorithm to succeed. This is particularly fortuitous for learning-theoretic applications of agnostic boosting, which often take place in the distribution-specific setting, where unlabeled samples can be availed for free. We detail other applications of this result in reinforcement learning.
Motion Modes: What Could Happen Next?
Nov 29, 2024



Predicting diverse object motions from a single static image remains challenging, as current video generation models often entangle object movement with camera motion and other scene changes. While recent methods can predict specific motions from motion arrow input, they rely on synthetic data and predefined motions, limiting their application to complex scenes. We introduce Motion Modes, a training-free approach that explores a pre-trained image-to-video generator's latent distribution to discover various distinct and plausible motions focused on selected objects in static images. We achieve this by employing a flow generator guided by energy functions designed to disentangle object and camera motion. Additionally, we use an energy inspired by particle guidance to diversify the generated motions, without requiring explicit training data. Experimental results demonstrate that Motion Modes generates realistic and varied object animations, surpassing previous methods and even human predictions regarding plausibility and diversity. Project Webpage: https://motionmodes.github.io/
Sample-Efficient Agnostic Boosting
Oct 31, 2024
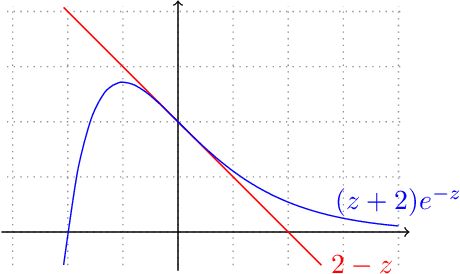
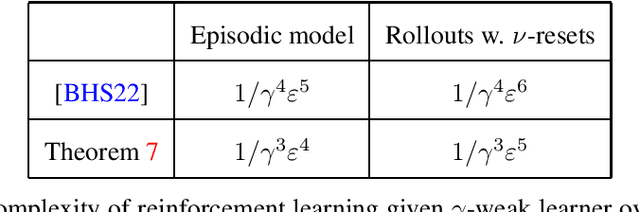
The theory of boosting provides a computational framework for aggregating approximate weak learning algorithms, which perform marginally better than a random predictor, into an accurate strong learner. In the realizable case, the success of the boosting approach is underscored by a remarkable fact that the resultant sample complexity matches that of a computationally demanding alternative, namely Empirical Risk Minimization (ERM). This in particular implies that the realizable boosting methodology has the potential to offer computational relief without compromising on sample efficiency. Despite recent progress, in agnostic boosting, where assumptions on the conditional distribution of labels given feature descriptions are absent, ERM outstrips the agnostic boosting methodology in being quadratically more sample efficient than all known agnostic boosting algorithms. In this paper, we make progress on closing this gap, and give a substantially more sample efficient agnostic boosting algorithm than those known, without compromising on the computational (or oracle) complexity. A key feature of our algorithm is that it leverages the ability to reuse samples across multiple rounds of boosting, while guaranteeing a generalization error strictly better than those obtained by blackbox applications of uniform convergence arguments. We also apply our approach to other previously studied learning problems, including boosting for reinforcement learning, and demonstrate improved results.
Improved Differentially Private and Lazy Online Convex Optimization
Dec 20, 2023We study the task of $(\epsilon, \delta)$-differentially private online convex optimization (OCO). In the online setting, the release of each distinct decision or iterate carries with it the potential for privacy loss. This problem has a long history of research starting with Jain et al. [2012] and the best known results for the regime of {\epsilon} not being very small are presented in Agarwal et al. [2023]. In this paper we improve upon the results of Agarwal et al. [2023] in terms of the dimension factors as well as removing the requirement of smoothness. Our results are now the best known rates for DP-OCO in this regime. Our algorithms builds upon the work of [Asi et al., 2023] which introduced the idea of explicitly limiting the number of switches via rejection sampling. The main innovation in our algorithm is the use of sampling from a strongly log-concave density which allows us to trade-off the dimension factors better leading to improved results.