 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating Feedback Analysis in Surgical Training: Detection, Categorization, and Assessment
Dec 01, 2024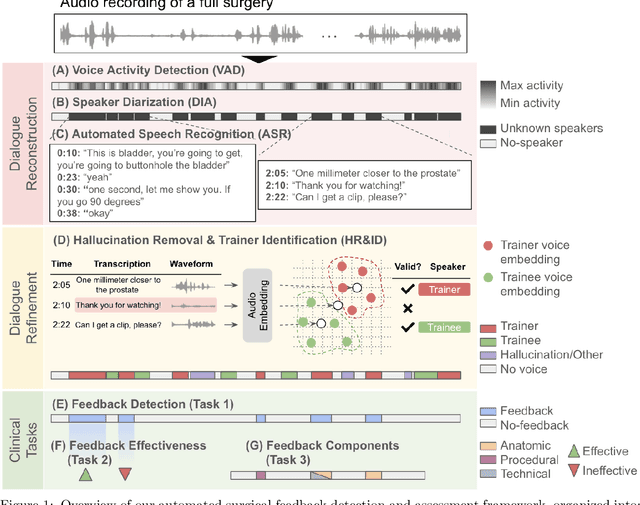
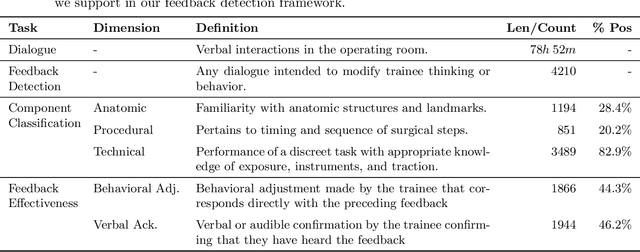

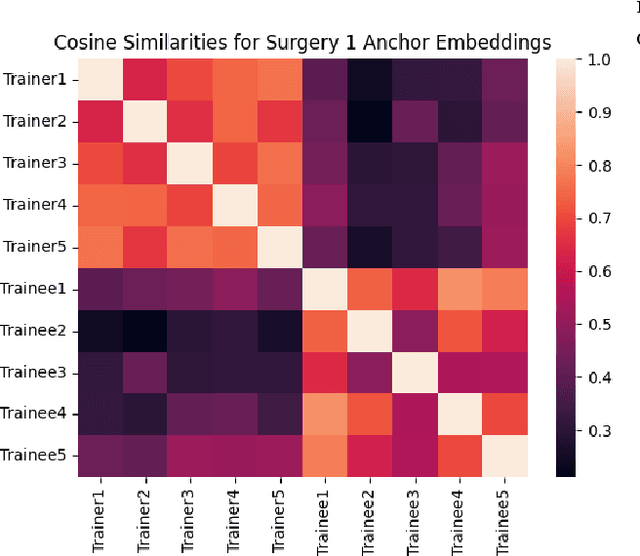
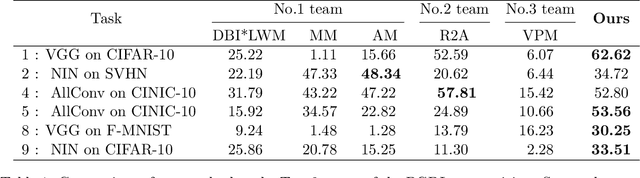
This work introduces the first framework for reconstructing surgical dialogue from unstructured real-world recordings, which is crucial for characterizing teaching tasks. In surgical training, the formative verbal feedback that trainers provide to trainees during live surgeries is crucial for ensuring safety, correcting behavior immediately, and facilitating long-term skill acquisition. However, analyzing and quantifying this feedback is challenging due to its unstructured and specialized nature. Automated systems are essential to manage these complexities at scale, allowing for the creation of structured datasets that enhance feedback analysis and improve surgical education. Our framework integrates voice activity detection, speaker diarization, and automated speech recaognition, with a novel enhancement that 1) removes hallucinations (non-existent utterances generated during speech recognition fueled by noise in the operating room) and 2) separates speech from trainers and trainees using few-shot voice samples. These aspects are vital for reconstructing accurate surgical dialogues and understanding the roles of operating room participants. Using data from 33 real-world surgeries, we demonstrated the system's capability to reconstruct surgical teaching dialogues and detect feedback instances effectively (F1 score of 0.79+/-0.07). Moreover, our hallucination removal step improves feedback detection performance by ~14%. Evaluation on downstream clinically relevant tasks of predicting Behavioral Adjustment of trainees and classifying Technical feedback, showed performances comparable to manual annotations with F1 scores of 0.82+/0.03 and 0.81+/0.03 respectively. These results highlight the effectiveness of our framework in supporting clinically relevant tasks and improving over manual methods.
Skill-Mix: a Flexible and Expandable Family of Evaluations for AI models
Oct 26, 2023



With LLMs shifting their role from statistical modeling of language to serving as general-purpose AI agents, how should LLM evaluations change? Arguably, a key ability of an AI agent is to flexibly combine, as needed, the basic skills it has learned. The capability to combine skills plays an important role in (human) pedagogy and also in a paper on emergence phenomena (Arora & Goyal, 2023). This work introduces Skill-Mix, a new evaluation to measure ability to combine skills. Using a list of $N$ skills the evaluator repeatedly picks random subsets of $k$ skills and asks the LLM to produce text combining that subset of skills. Since the number of subsets grows like $N^k$, for even modest $k$ this evaluation will, with high probability, require the LLM to produce text significantly different from any text in the training set. The paper develops a methodology for (a) designing and administering such an evaluation, and (b) automatic grading (plus spot-checking by humans) of the results using GPT-4 as well as the open LLaMA-2 70B model. Administering a version of to popular chatbots gave results that, while generally in line with prior expectations, contained surprises. Sizeable differences exist among model capabilities that are not captured by their ranking on popular LLM leaderboards ("cramming for the leaderboard"). Furthermore, simple probability calculations indicate that GPT-4's reasonable performance on $k=5$ is suggestive of going beyond "stochastic parrot" behavior (Bender et al., 2021), i.e., it combines skills in ways that it had not seen during training. We sketch how the methodology can lead to a Skill-Mix based eco-system of open evaluations for AI capabilities of future models.
Online Nonstochastic Model-Free Reinforcement Learning
May 27, 2023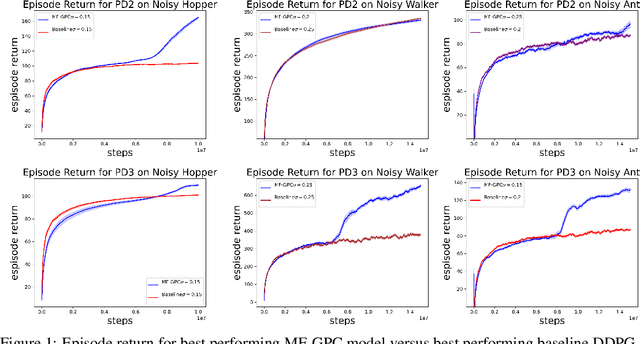
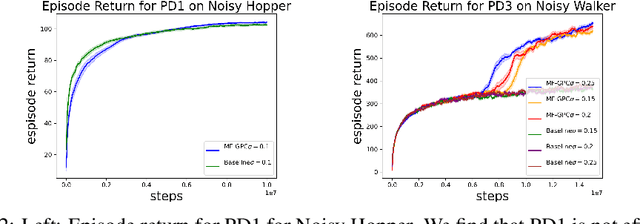

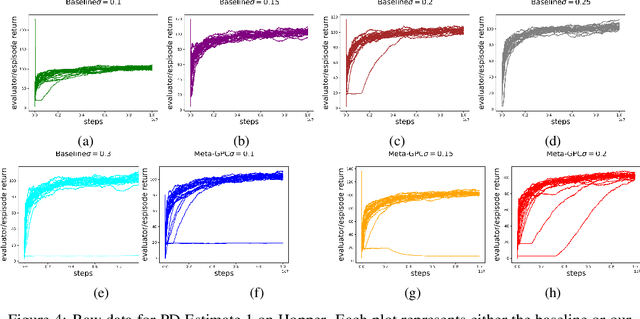
In this work, we explore robust model-free reinforcement learning algorithms for environments that may be dynamic or even adversarial. Conventional state-based policies fail to accommodate the challenge imposed by the presence of unmodeled disturbances in such settings. Additionally, optimizing linear state-based policies pose obstacle for efficient optimization, leading to nonconvex objectives even in benign environments like linear dynamical systems. Drawing inspiration from recent advancements in model-based control, we introduce a novel class of policies centered on disturbance signals. We define several categories of these signals, referred to as pseudo-disturbances, and corresponding policy classes based on them. We provide efficient and practical algorithms for optimizing these policies. Next, we examine the task of online adaptation of reinforcement learning agents to adversarial disturbances. Our methods can be integrated with any black-box model-free approach, resulting in provable regret guarantees if the underlying dynamics is linear. We evaluate our method over different standard RL benchmarks and demonstrate improved robustness.
New Definitions and Evaluations for Saliency Methods: Staying Intrinsic, Complete and Sound
Nov 05, 2022



Saliency methods compute heat maps that highlight portions of an input that were most {\em important} for the label assigned to it by a deep net. Evaluations of saliency methods convert this heat map into a new {\em masked input} by retaining the $k$ highest-ranked pixels of the original input and replacing the rest with \textquotedblleft uninformative\textquotedblright\ pixels, and checking if the net's output is mostly unchanged. This is usually seen as an {\em explanation} of the output, but the current paper highlights reasons why this inference of causality may be suspect. Inspired by logic concepts of {\em completeness \& soundness}, it observes that the above type of evaluation focuses on completeness of the explanation, but ignores soundness. New evaluation metrics are introduced to capture both notions, while staying in an {\em intrinsic} framework -- i.e., using the dataset and the net, but no separately trained nets, human evaluations, etc. A simple saliency method is described that matches or outperforms prior methods in the evaluations. Experiments also suggest new intrinsic justifications, based on soundness, for popular heuristic tricks such as TV regularization and upsampling.
Understanding Influence Functions and Datamodels via Harmonic Analysis
Oct 03, 2022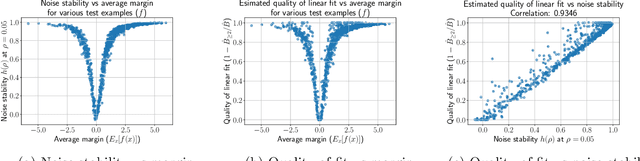
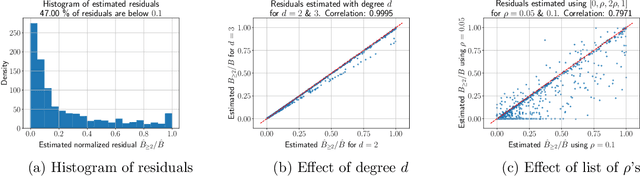
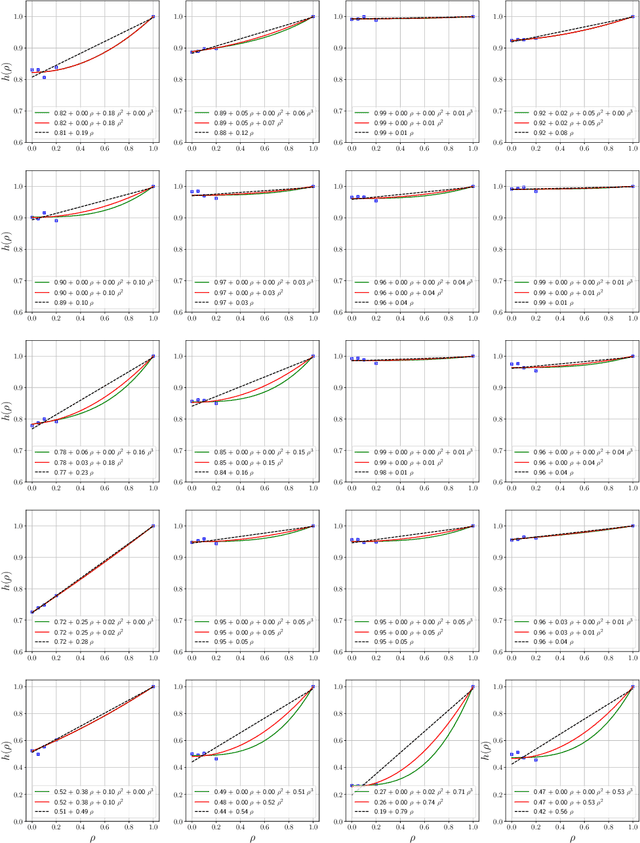
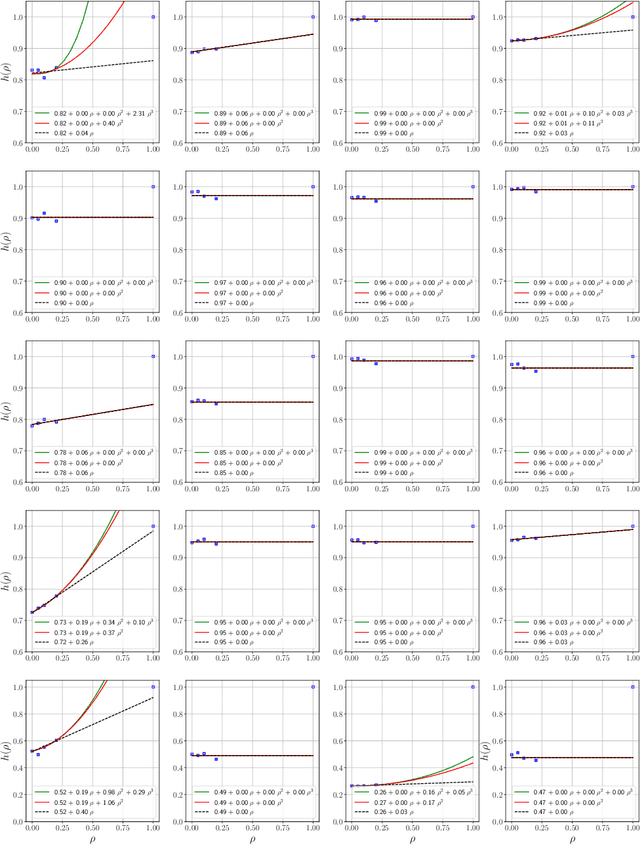
Influence functions estimate effect of individual data points on predictions of the model on test data and were adapted to deep learning in Koh and Liang [2017]. They have been used for detecting data poisoning, detecting helpful and harmful examples, influence of groups of datapoints, etc. Recently, Ilyas et al. [2022] introduced a linear regression method they termed datamodels to predict the effect of training points on outputs on test data. The current paper seeks to provide a better theoretical understanding of such interesting empirical phenomena. The primary tool is harmonic analysis and the idea of noise stability. Contributions include: (a) Exact characterization of the learnt datamodel in terms of Fourier coefficients. (b) An efficient method to estimate the residual error and quality of the optimum linear datamodel without having to train the datamodel. (c) New insights into when influences of groups of datapoints may or may not add up linearly.
On Predicting Generalization using GANs
Nov 28, 2021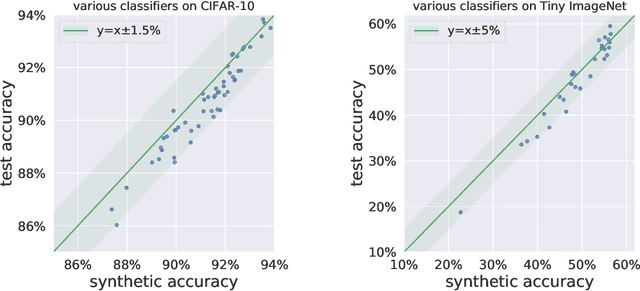
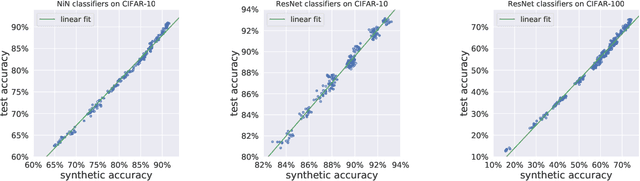
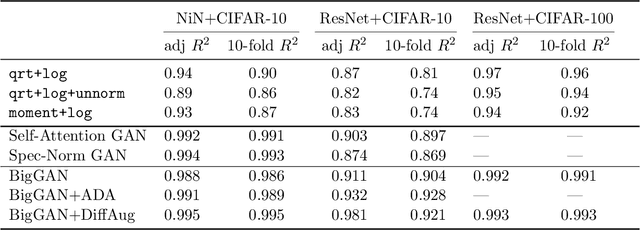
Research on generalization bounds for deep networks seeks to give ways to predict test error using just the training dataset and the network parameters. While generalization bounds can give many insights about architecture design, training algorithms etc., what they do not currently do is yield good predictions for actual test error. A recently introduced Predicting Generalization in Deep Learning competition aims to encourage discovery of methods to better predict test error. The current paper investigates a simple idea: can test error be predicted using 'synthetic data' produced using a Generative Adversarial Network (GAN) that was trained on the same training dataset? Upon investigating several GAN models and architectures, we find that this turns out to be the case. In fact, using GANs pre-trained on standard datasets, the test error can be predicted without requiring any additional hyper-parameter tuning. This result is surprising because GANs have well-known limitations (e.g. mode collapse) and are known to not learn the data distribution accurately. Yet the generated samples are good enough to substitute for test data. Several additional experiments are presented to explore reasons why GANs do well at this task. In addition to a new approach for predicting generalization, the counter-intuitive phenomena presented in our work may also call for a better understanding of GANs' strengths and limitations.
A Representation Learning Perspective on the Importance of Train-Validation Splitting in Meta-Learning
Jun 29, 2021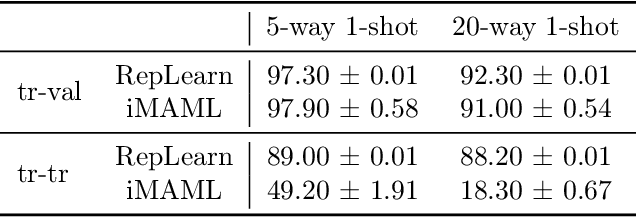
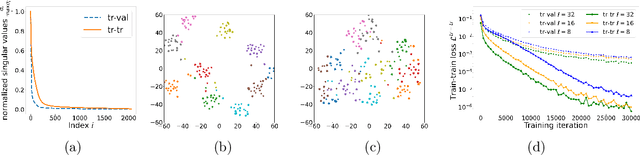

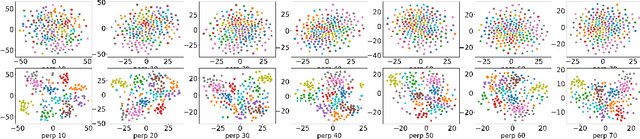
An effective approach in meta-learning is to utilize multiple "train tasks" to learn a good initialization for model parameters that can help solve unseen "test tasks" with very few samples by fine-tuning from this initialization. Although successful in practice, theoretical understanding of such methods is limited. This work studies an important aspect of these methods: splitting the data from each task into train (support) and validation (query) sets during meta-training. Inspired by recent work (Raghu et al., 2020), we view such meta-learning methods through the lens of representation learning and argue that the train-validation split encourages the learned representation to be low-rank without compromising on expressivity, as opposed to the non-splitting variant that encourages high-rank representations. Since sample efficiency benefits from low-rankness, the splitting strategy will require very few samples to solve unseen test tasks. We present theoretical results that formalize this idea for linear representation learning on a subspace meta-learning instance, and experimentally verify this practical benefit of splitting in simulations and on standard meta-learning benchmarks.
Inherent Noise in Gradient Based Methods
May 26, 2020

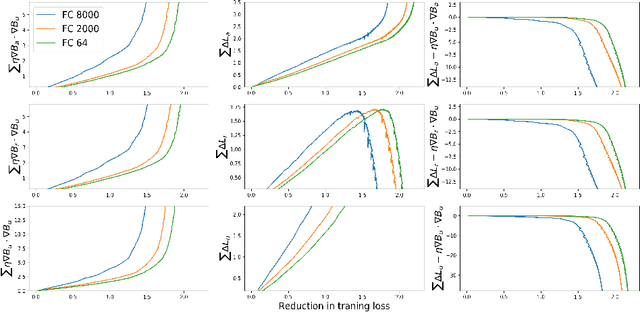

Previous work has examined the ability of larger capacity neural networks to generalize better than smaller ones, even without explicit regularizers, by analyzing gradient based algorithms such as GD and SGD. The presence of noise and its effect on robustness to parameter perturbations has been linked to generalization. We examine a property of GD and SGD, namely that instead of iterating through all scalar weights in the network and updating them one by one, GD (and SGD) updates all the parameters at the same time. As a result, each parameter $w^i$ calculates its partial derivative at the stale parameter $\mathbf{w_t}$, but then suffers loss $\hat{L}(\mathbf{w_{t+1}})$. We show that this causes noise to be introduced into the optimization. We find that this noise penalizes models that are sensitive to perturbations in the weights. We find that penalties are most pronounced for batches that are currently being used to update, and are higher for larger models.
A Simple Saliency Method That Passes the Sanity Checks
Jun 07, 2019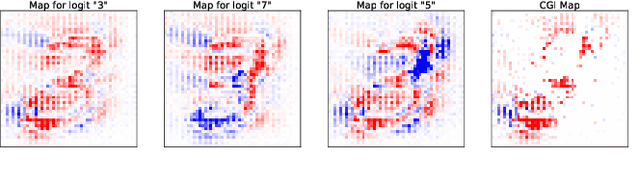
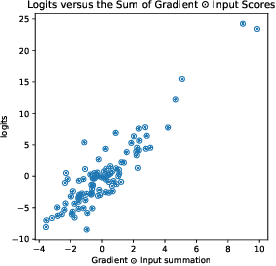

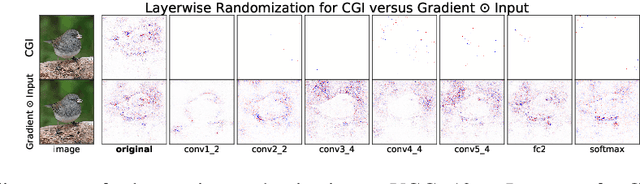
There is great interest in "saliency methods" (also called "attribution methods"), which give "explanations" for a deep net's decision, by assigning a "score" to each feature/pixel in the input. Their design usually involves credit-assignment via the gradient of the output with respect to input. Recently Adebayo et al. [arXiv:1810.03292] questioned the validity of many of these methods since they do not pass simple *sanity checks* which test whether the scores shift/vanish when layers of the trained net are randomized, or when the net is retrained using random labels for inputs. We propose a simple fix to existing saliency methods that helps them pass sanity checks, which we call "competition for pixels". This involves computing saliency maps for all possible labels in the classification task, and using a simple competition among them to identify and remove less relevant pixels from the map. The simplest variant of this is "Competitive Gradient $\odot$ Input (CGI)": it is efficient, requires no additional training, and uses only the input and gradient. Some theoretical justification is provided for it (especially for ReLU networks) and its performance is empirically demonstrated.
Non-Gaussian information from weak lensing data via deep learning
May 01, 2018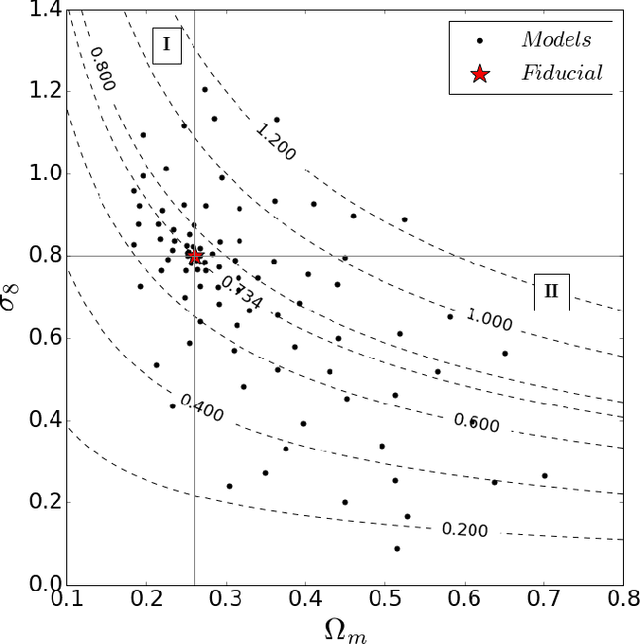
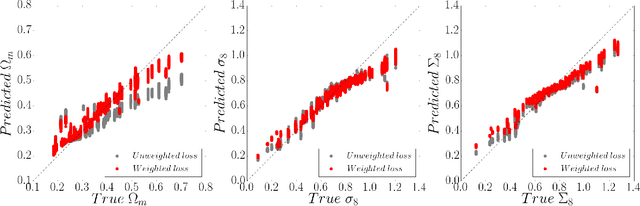
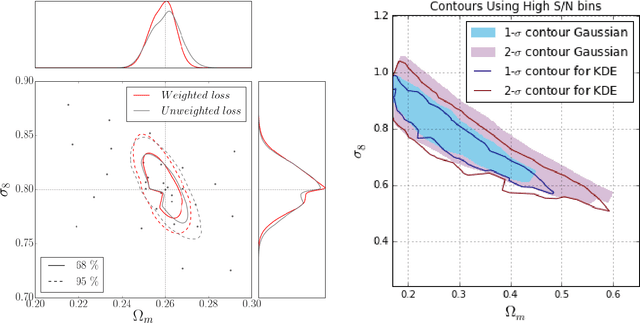
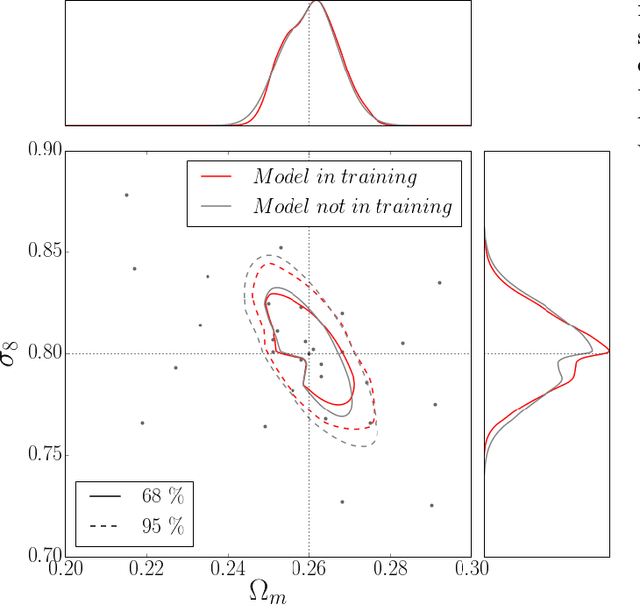
Weak lensing maps contain information beyond two-point statistics on small scales. Much recent work has tried to extract this information through a range of different observables or via nonlinear transformations of the lensing field. Here we train and apply a 2D convolutional neural network to simulated noiseless lensing maps covering 96 different cosmological models over a range of {$\Omega_m,\sigma_8$}. Using the area of the confidence contour in the {$\Omega_m,\sigma_8$} plane as a figure-of-merit, derived from simulated convergence maps smoothed on a scale of 1.0 arcmin, we show that the neural network yields $\approx 5 \times$ tighter constraints than the power spectrum, and $\approx 4 \times$ tighter than the lensing peaks. Such gains illustrate the extent to which weak lensing data encode cosmological information not accessible to the power spectrum or even other, non-Gaussian statistics such as lensing peaks.
* 15 pages, 13 figures, accepted to PRD