 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating an Image From 1,000 Words: Enhancing Text-to-Image With Structured Captions
Nov 10, 2025



Text-to-image models have rapidly evolved from casual creative tools to professional-grade systems, achieving unprecedented levels of image quality and realism. Yet, most models are trained to map short prompts into detailed images, creating a gap between sparse textual input and rich visual outputs. This mismatch reduces controllability, as models often fill in missing details arbitrarily, biasing toward average user preferences and limiting precision for professional use. We address this limitation by training the first open-source text-to-image model on long structured captions, where every training sample is annotated with the same set of fine-grained attributes. This design maximizes expressive coverage and enables disentangled control over visual factors. To process long captions efficiently, we propose DimFusion, a fusion mechanism that integrates intermediate tokens from a lightweight LLM without increasing token length. We also introduce the Text-as-a-Bottleneck Reconstruction (TaBR) evaluation protocol. By assessing how well real images can be reconstructed through a captioning-generation loop, TaBR directly measures controllability and expressiveness, even for very long captions where existing evaluation methods fail. Finally, we demonstrate our contributions by training the large-scale model FIBO, achieving state-of-the-art prompt alignment among open-source models. Model weights are publicly available at https://huggingface.co/briaai/FIBO
Playground v3: Improving Text-to-Image Alignment with Deep-Fusion Large Language Models
Sep 16, 2024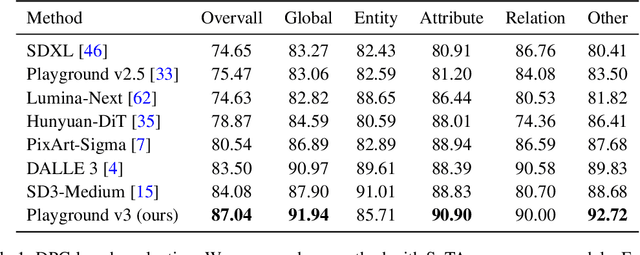
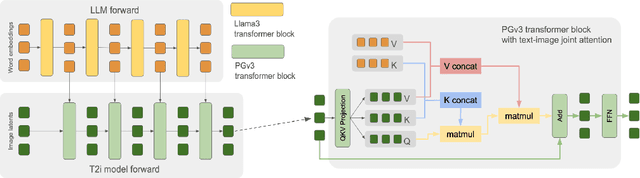
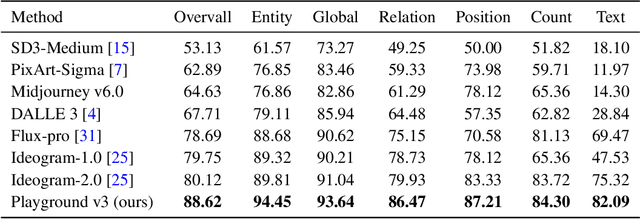

We introduce Playground v3 (PGv3), our latest text-to-image model that achieves state-of-the-art (SoTA) performance across multiple testing benchmarks, excels in graphic design abilities and introduces new capabilities. Unlike traditional text-to-image generative models that rely on pre-trained language models like T5 or CLIP text encoders, our approach fully integrates Large Language Models (LLMs) with a novel structure that leverages text conditions exclusively from a decoder-only LLM. Additionally, to enhance image captioning quality-we developed an in-house captioner, capable of generating captions with varying levels of detail, enriching the diversity of text structures. We also introduce a new benchmark CapsBench to evaluate detailed image captioning performance. Experimental results demonstrate that PGv3 excels in text prompt adherence, complex reasoning, and accurate text rendering. User preference studies indicate the super-human graphic design ability of our model for common design applications, such as stickers, posters, and logo designs. Furthermore, PGv3 introduces new capabilities, including precise RGB color control and robust multilingual understanding.
NLLB-CLIP -- train performant multilingual image retrieval model on a budget
Sep 04, 2023Today, the exponential rise of large models developed by academic and industrial institutions with the help of massive computing resources raises the question of whether someone without access to such resources can make a valuable scientific contribution. To explore this, we tried to solve the challenging task of multilingual image retrieval having a limited budget of $1,000. As a result, we present NLLB-CLIP - CLIP model with a text encoder from the NLLB model. To train the model, we used an automatically created dataset of 106,246 good-quality images with captions in 201 languages derived from the LAION COCO dataset. We trained multiple models using image and text encoders of various sizes and kept different parts of the model frozen during the training. We thoroughly analyzed the trained models using existing evaluation datasets and newly created XTD200 and Flickr30k-200 datasets. We show that NLLB-CLIP is comparable in quality to state-of-the-art models and significantly outperforms them on low-resource languages.