 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlayground v3: Improving Text-to-Image Alignment with Deep-Fusion Large Language Models
Paper and Code
Sep 16, 2024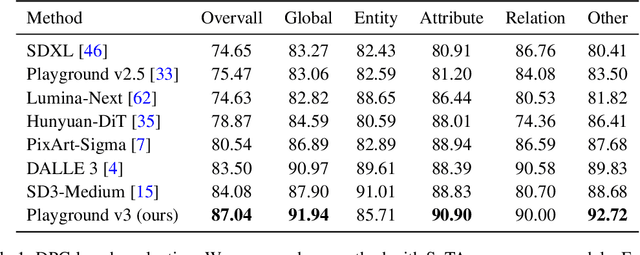
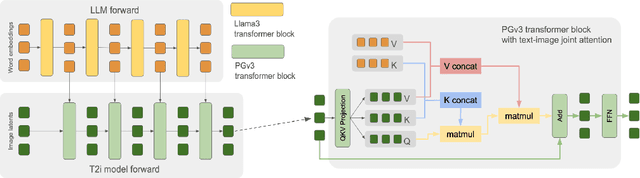
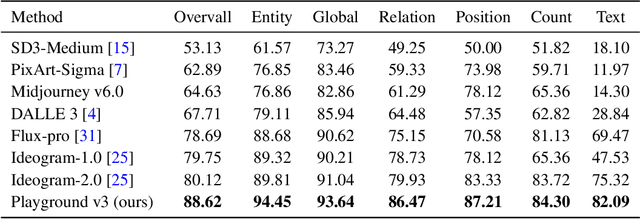

We introduce Playground v3 (PGv3), our latest text-to-image model that achieves state-of-the-art (SoTA) performance across multiple testing benchmarks, excels in graphic design abilities and introduces new capabilities. Unlike traditional text-to-image generative models that rely on pre-trained language models like T5 or CLIP text encoders, our approach fully integrates Large Language Models (LLMs) with a novel structure that leverages text conditions exclusively from a decoder-only LLM. Additionally, to enhance image captioning quality-we developed an in-house captioner, capable of generating captions with varying levels of detail, enriching the diversity of text structures. We also introduce a new benchmark CapsBench to evaluate detailed image captioning performance. Experimental results demonstrate that PGv3 excels in text prompt adherence, complex reasoning, and accurate text rendering. User preference studies indicate the super-human graphic design ability of our model for common design applications, such as stickers, posters, and logo designs. Furthermore, PGv3 introduces new capabilities, including precise RGB color control and robust multilingual understanding.