 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhotorealistic Object Insertion with Diffusion-Guided Inverse Rendering
Paper and Code
Aug 19, 2024
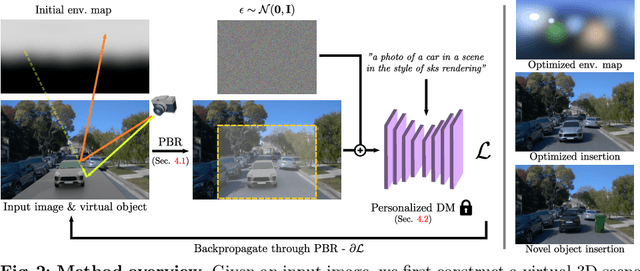
The correct insertion of virtual objects in images of real-world scenes requires a deep understanding of the scene's lighting, geometry and materials, as well as the image formation process. While recent large-scale diffusion models have shown strong generative and inpainting capabilities, we find that current models do not sufficiently "understand" the scene shown in a single picture to generate consistent lighting effects (shadows, bright reflections, etc.) while preserving the identity and details of the composited object. We propose using a personalized large diffusion model as guidance to a physically based inverse rendering process. Our method recovers scene lighting and tone-mapping parameters, allowing the photorealistic composition of arbitrary virtual objects in single frames or videos of indoor or outdoor scenes. Our physically based pipeline further enables automatic materials and tone-mapping refinement.