 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards LLM-generated explanations for Component-based Knowledge Graph Question Answering Systems
Aug 20, 2025Over time, software systems have reached a level of complexity that makes it difficult for their developers and users to explain particular decisions made by them. In this paper, we focus on the explainability of component-based systems for Question Answering (QA). These components often conduct processes driven by AI methods, in which behavior and decisions cannot be clearly explained or justified, s.t., even for QA experts interpreting the executed process and its results is hard. To address this challenge, we present an approach that considers the components' input and output data flows as a source for representing the behavior and provide explanations for the components, enabling users to comprehend what happened. In the QA framework used here, the data flows of the components are represented as SPARQL queries (inputs) and RDF triples (outputs). Hence, we are also providing valuable insights on verbalization regarding these data types. In our experiments, the approach generates explanations while following template-based settings (baseline) or via the use of Large Language Models (LLMs) with different configurations (automatic generation). Our evaluation shows that the explanations generated via LLMs achieve high quality and mostly outperform template-based approaches according to the users' ratings. Therefore, it enables us to automatically explain the behavior and decisions of QA components to humans while using RDF and SPARQL as a context for explanations.
Post-hoc LLM-Supported Debugging of Distributed Processes
Aug 20, 2025In this paper, we address the problem of manual debugging, which nowadays remains resource-intensive and in some parts archaic. This problem is especially evident in increasingly complex and distributed software systems. Therefore, our objective of this work is to introduce an approach that can possibly be applied to any system, at both the macro- and micro-level, to ease this debugging process. This approach utilizes a system's process data, in conjunction with generative AI, to generate natural-language explanations. These explanations are generated from the actual process data, interface information, and documentation to guide the developers more efficiently to understand the behavior and possible errors of a process and its sub-processes. Here, we present a demonstrator that employs this approach on a component-based Java system. However, our approach is language-agnostic. Ideally, the generated explanations will provide a good understanding of the process, even if developers are not familiar with all the details of the considered system. Our demonstrator is provided as an open-source web application that is freely accessible to all users.
Text-to-SPARQL Goes Beyond English: Multilingual Question Answering Over Knowledge Graphs through Human-Inspired Reasoning
Jul 22, 2025Accessing knowledge via multilingual natural-language interfaces is one of the emerging challenges in the field of information retrieval and related ones. Structured knowledge stored in knowledge graphs can be queried via a specific query language (e.g., SPARQL). Therefore, one needs to transform natural-language input into a query to fulfill an information need. Prior approaches mostly focused on combining components (e.g., rule-based or neural-based) that solve downstream tasks and come up with an answer at the end. We introduce mKGQAgent, a human-inspired framework that breaks down the task of converting natural language questions into SPARQL queries into modular, interpretable subtasks. By leveraging a coordinated LLM agent workflow for planning, entity linking, and query refinement - guided by an experience pool for in-context learning - mKGQAgent efficiently handles multilingual KGQA. Evaluated on the DBpedia- and Corporate-based KGQA benchmarks within the Text2SPARQL challenge 2025, our approach took first place among the other participants. This work opens new avenues for developing human-like reasoning systems in multilingual semantic parsing.
RDF-Based Structured Quality Assessment Representation of Multilingual LLM Evaluations
Apr 30, 2025Large Language Models (LLMs) increasingly serve as knowledge interfaces, yet systematically assessing their reliability with conflicting information remains difficult. We propose an RDF-based framework to assess multilingual LLM quality, focusing on knowledge conflicts. Our approach captures model responses across four distinct context conditions (complete, incomplete, conflicting, and no-context information) in German and English. This structured representation enables the comprehensive analysis of knowledge leakage-where models favor training data over provided context-error detection, and multilingual consistency. We demonstrate the framework through a fire safety domain experiment, revealing critical patterns in context prioritization and language-specific performance, and demonstrating that our vocabulary was sufficient to express every assessment facet encountered in the 28-question study.
QALD-9-plus: A Multilingual Dataset for Question Answering over DBpedia and Wikidata Translated by Native Speakers
Feb 07, 2022
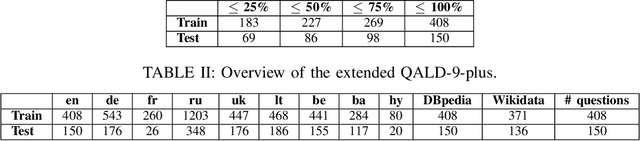

The ability to have the same experience for different user groups (i.e., accessibility) is one of the most important characteristics of Web-based systems. The same is true for Knowledge Graph Question Answering (KGQA) systems that provide the access to Semantic Web data via natural language interface. While following our research agenda on the multilingual aspect of accessibility of KGQA systems, we identified several ongoing challenges. One of them is the lack of multilingual KGQA benchmarks. In this work, we extend one of the most popular KGQA benchmarks - QALD-9 by introducing high-quality questions' translations to 8 languages provided by native speakers, and transferring the SPARQL queries of QALD-9 from DBpedia to Wikidata, s.t., the usability and relevance of the dataset is strongly increased. Five of the languages - Armenian, Ukrainian, Lithuanian, Bashkir and Belarusian - to our best knowledge were never considered in KGQA research community before. The latter two of the languages are considered as "endangered" by UNESCO. We call the extended dataset QALD-9-plus and made it available online https://github.com/Perevalov/qald_9_plus.
Knowledge Graph Question Answering Leaderboard: A Community Resource to Prevent a Replication Crisis
Jan 20, 2022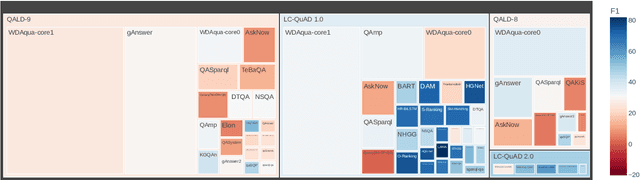
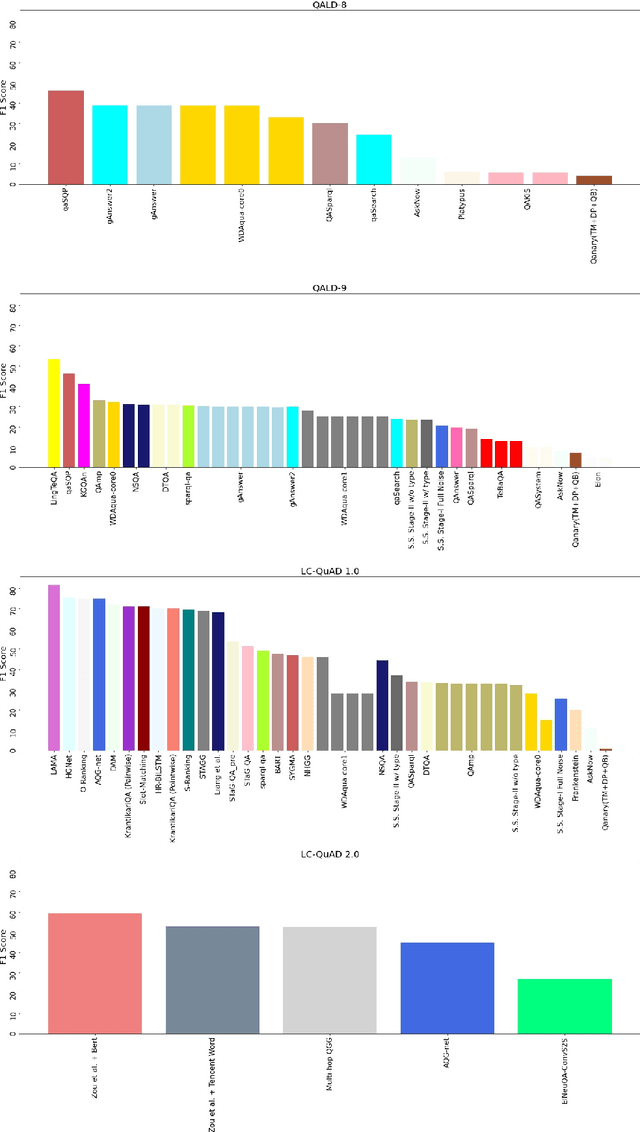
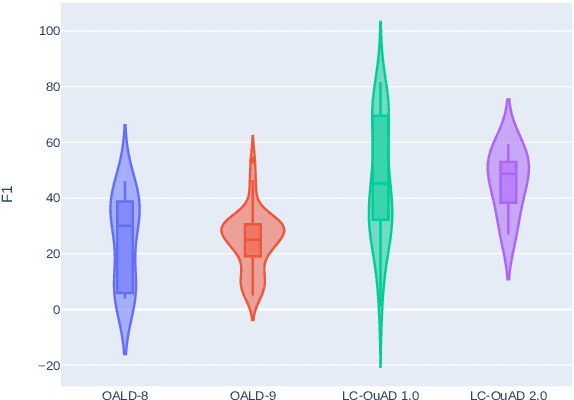
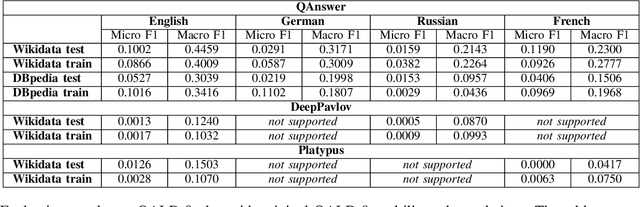
Data-driven systems need to be evaluated to establish trust in the scientific approach and its applicability. In particular, this is true for Knowledge Graph (KG) Question Answering (QA), where complex data structures are made accessible via natural-language interfaces. Evaluating the capabilities of these systems has been a driver for the community for more than ten years while establishing different KGQA benchmark datasets. However, comparing different approaches is cumbersome. The lack of existing and curated leaderboards leads to a missing global view over the research field and could inject mistrust into the results. In particular, the latest and most-used datasets in the KGQA community, LC-QuAD and QALD, miss providing central and up-to-date points of trust. In this paper, we survey and analyze a wide range of evaluation results with significant coverage of 100 publications and 98 systems from the last decade. We provide a new central and open leaderboard for any KGQA benchmark dataset as a focal point for the community - https://kgqa.github.io/leaderboard. Our analysis highlights existing problems during the evaluation of KGQA systems. Thus, we will point to possible improvements for future evaluations.
Improving the Question Answering Quality using Answer Candidate Filtering based on Natural-Language Features
Dec 10, 2021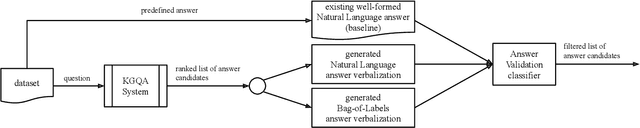
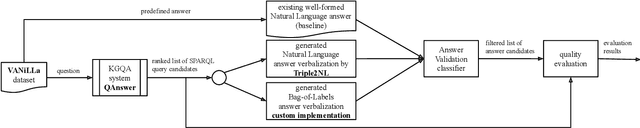
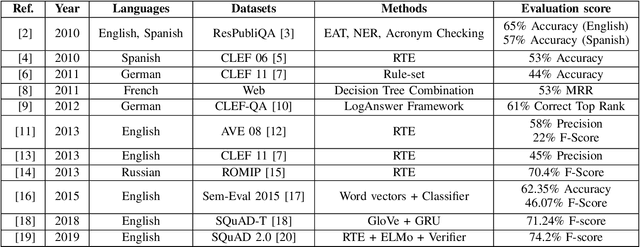
Software with natural-language user interfaces has an ever-increasing importance. However, the quality of the included Question Answering (QA) functionality is still not sufficient regarding the number of questions that are answered correctly. In our work, we address the research problem of how the QA quality of a given system can be improved just by evaluating the natural-language input (i.e., the user's question) and output (i.e., the system's answer). Our main contribution is an approach capable of identifying wrong answers provided by a QA system. Hence, filtering incorrect answers from a list of answer candidates is leading to a highly improved QA quality. In particular, our approach has shown its potential while removing in many cases the majority of incorrect answers, which increases the QA quality significantly in comparison to the non-filtered output of a system.
Better Call the Plumber: Orchestrating Dynamic Information Extraction Pipelines
Feb 22, 2021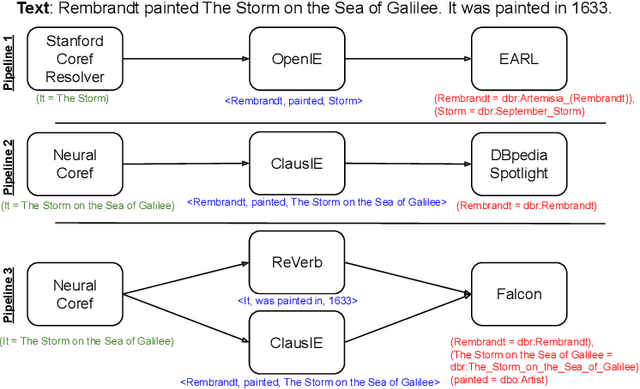
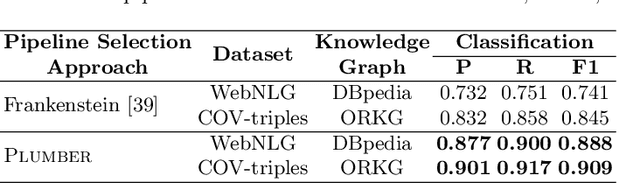
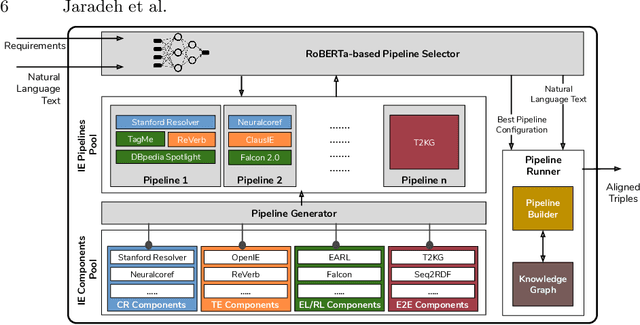
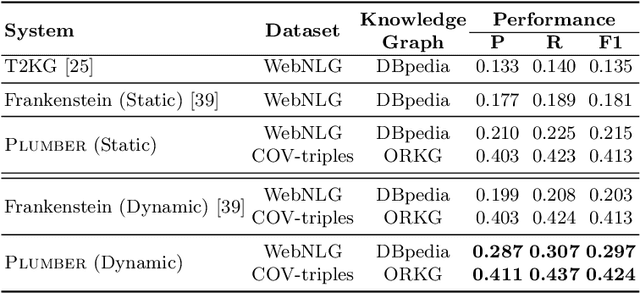
In the last decade, a large number of Knowledge Graph (KG) information extraction approaches were proposed. Albeit effective, these efforts are disjoint, and their collective strengths and weaknesses in effective KG information extraction (IE) have not been studied in the literature. We propose Plumber, the first framework that brings together the research community's disjoint IE efforts. The Plumber architecture comprises 33 reusable components for various KG information extraction subtasks, such as coreference resolution, entity linking, and relation extraction. Using these components,Plumber dynamically generates suitable information extraction pipelines and offers overall 264 distinct pipelines.We study the optimization problem of choosing suitable pipelines based on input sentences. To do so, we train a transformer-based classification model that extracts contextual embeddings from the input and finds an appropriate pipeline. We study the efficacy of Plumber for extracting the KG triples using standard datasets over two KGs: DBpedia, and Open Research Knowledge Graph (ORKG). Our results demonstrate the effectiveness of Plumber in dynamically generating KG information extraction pipelines,outperforming all baselines agnostics of the underlying KG. Furthermore,we provide an analysis of collective failure cases, study the similarities and synergies among integrated components, and discuss their limitations.
Towards a Question Answering System over the Semantic Web
Mar 02, 2018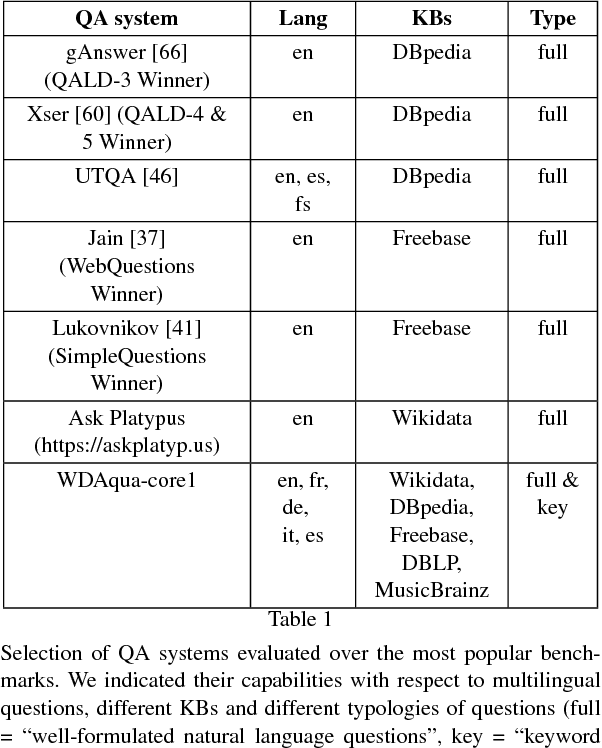
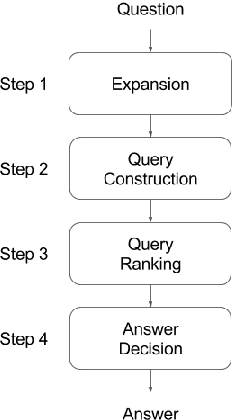
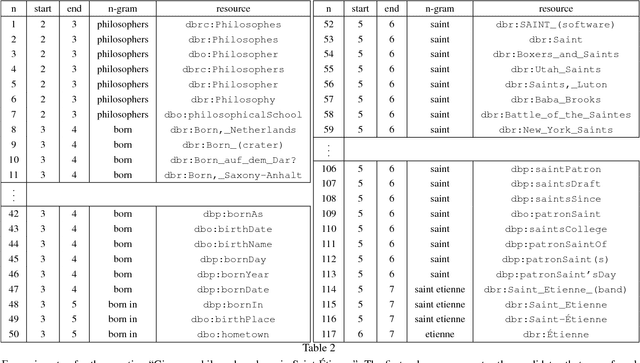
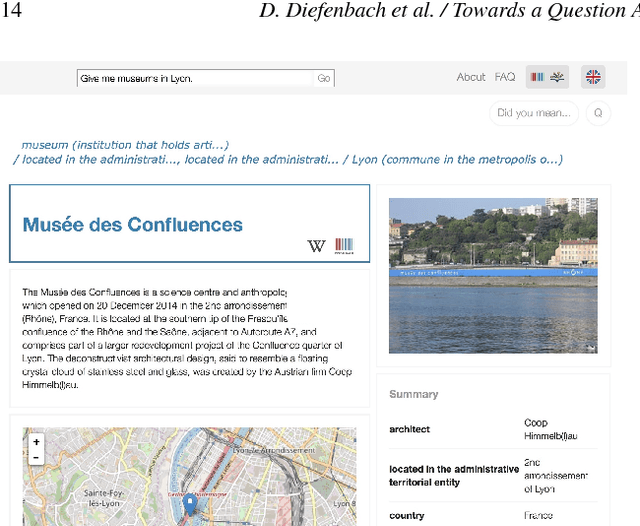
Thanks to the development of the Semantic Web, a lot of new structured data has become available on the Web in the form of knowledge bases (KBs). Making this valuable data accessible and usable for end-users is one of the main goals of Question Answering (QA) over KBs. Most current QA systems query one KB, in one language (namely English). The existing approaches are not designed to be easily adaptable to new KBs and languages. We first introduce a new approach for translating natural language questions to SPARQL queries. It is able to query several KBs simultaneously, in different languages, and can easily be ported to other KBs and languages. In our evaluation, the impact of our approach is proven using 5 different well-known and large KBs: Wikidata, DBpedia, MusicBrainz, DBLP and Freebase as well as 5 different languages namely English, German, French, Italian and Spanish. Second, we show how we integrated our approach, to make it easily accessible by the research community and by end-users. To summarize, we provided a conceptional solution for multilingual, KB-agnostic Question Answering over the Semantic Web. The provided first approximation validates this concept.
Evaluating topic coherence measures
Mar 25, 2014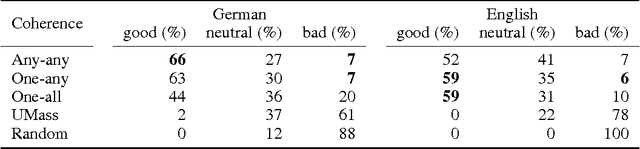
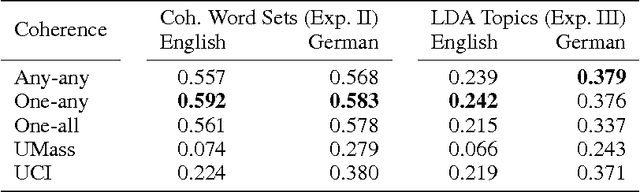
Topic models extract representative word sets - called topics - from word counts in documents without requiring any semantic annotations. Topics are not guaranteed to be well interpretable, therefore, coherence measures have been proposed to distinguish between good and bad topics. Studies of topic coherence so far are limited to measures that score pairs of individual words. For the first time, we include coherence measures from scientific philosophy that score pairs of more complex word subsets and apply them to topic scoring.