 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Benchmarking through the Lense of Concept Learning
Oct 23, 2025Evaluating competing systems in a comparable way, i.e., benchmarking them, is an undeniable pillar of the scientific method. However, system performance is often summarized via a small number of metrics. The analysis of the evaluation details and the derivation of insights for further development or use remains a tedious manual task with often biased results. Thus, this paper argues for a new type of benchmarking, which is dubbed explainable benchmarking. The aim of explainable benchmarking approaches is to automatically generate explanations for the performance of systems in a benchmark. We provide a first instantiation of this paradigm for knowledge-graph-based question answering systems. We compute explanations by using a novel concept learning approach developed for large knowledge graphs called PruneCEL. Our evaluation shows that PruneCEL outperforms state-of-the-art concept learners on the task of explainable benchmarking by up to 0.55 points F1 measure. A task-driven user study with 41 participants shows that in 80\% of the cases, the majority of participants can accurately predict the behavior of a system based on our explanations. Our code and data are available at https://github.com/dice-group/PruneCEL/tree/K-cap2025
LOLA -- An Open-Source Massively Multilingual Large Language Model
Sep 19, 2024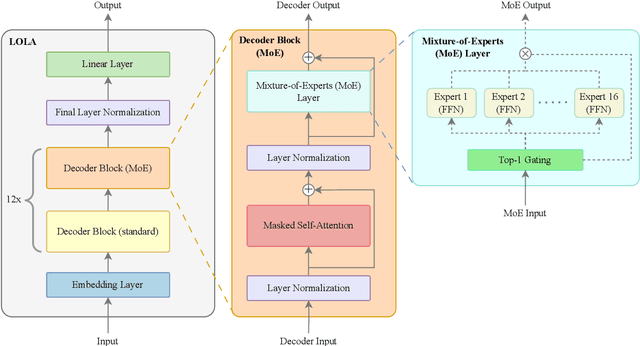
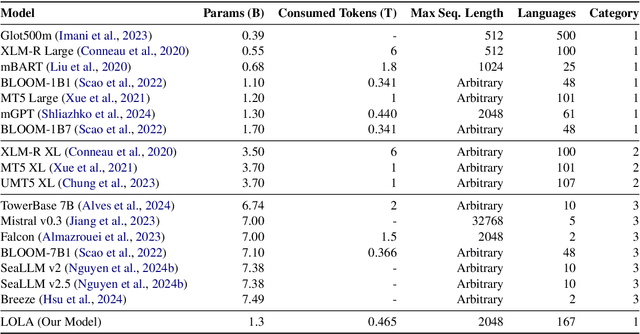
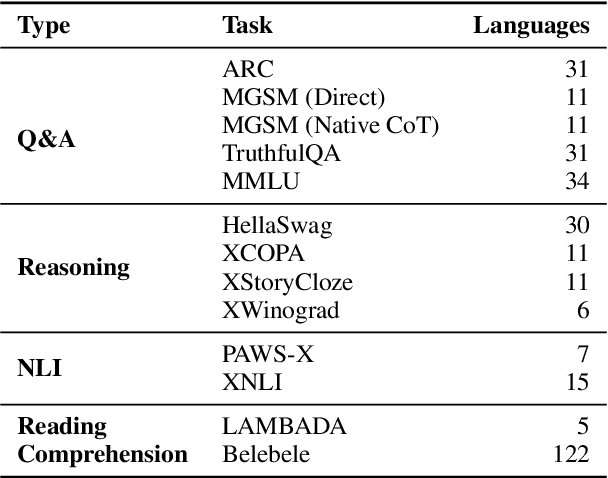
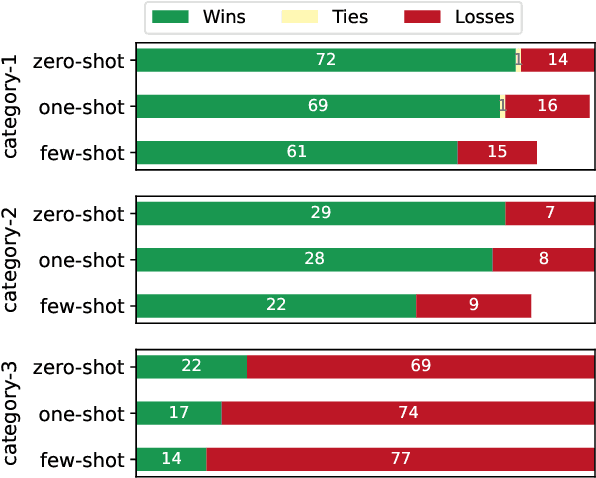
This paper presents LOLA, a massively multilingual large language model trained on more than 160 languages using a sparse Mixture-of-Experts Transformer architecture. Our architectural and implementation choices address the challenge of harnessing linguistic diversity while maintaining efficiency and avoiding the common pitfalls of multilinguality. Our analysis of the evaluation results shows competitive performance in natural language generation and understanding tasks. Additionally, we demonstrate how the learned expert-routing mechanism exploits implicit phylogenetic linguistic patterns to potentially alleviate the curse of multilinguality. We provide an in-depth look at the training process, an analysis of the datasets, and a balanced exploration of the model's strengths and limitations. As an open-source model, LOLA promotes reproducibility and serves as a robust foundation for future research. Our findings enable the development of compute-efficient multilingual models with strong, scalable performance across languages.
Performance Evaluation of Knowledge Graph Embedding Approaches under Non-adversarial Attacks
Jul 09, 2024



Knowledge Graph Embedding (KGE) transforms a discrete Knowledge Graph (KG) into a continuous vector space facilitating its use in various AI-driven applications like Semantic Search, Question Answering, or Recommenders. While KGE approaches are effective in these applications, most existing approaches assume that all information in the given KG is correct. This enables attackers to influence the output of these approaches, e.g., by perturbing the input. Consequently, the robustness of such KGE approaches has to be addressed. Recent work focused on adversarial attacks. However, non-adversarial attacks on all attack surfaces of these approaches have not been thoroughly examined. We close this gap by evaluating the impact of non-adversarial attacks on the performance of 5 state-of-the-art KGE algorithms on 5 datasets with respect to attacks on 3 attack surfaces-graph, parameter, and label perturbation. Our evaluation results suggest that label perturbation has a strong effect on the KGE performance, followed by parameter perturbation with a moderate and graph with a low effect.
BENGAL: An Automatic Benchmark Generator for Entity Recognition and Linking
Nov 01, 2018
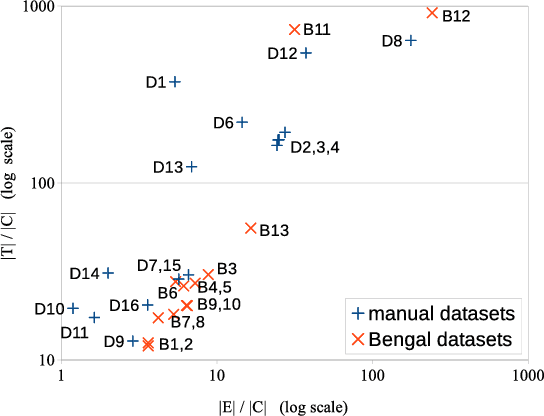
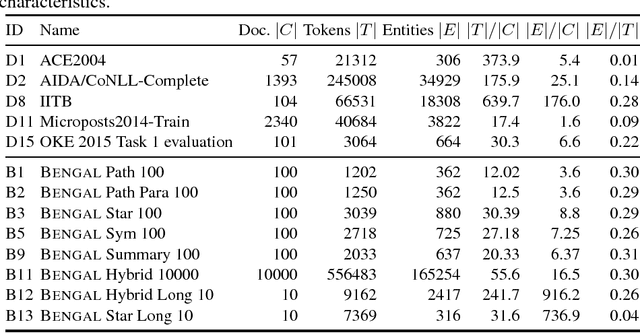

The manual creation of gold standards for named entity recognition and entity linking is time- and resource-intensive. Moreover, recent works show that such gold standards contain a large proportion of mistakes in addition to being difficult to maintain. We hence present BENGAL, a novel automatic generation of such gold standards as a complement to manually created benchmarks. The main advantage of our benchmarks is that they can be readily generated at any time. They are also cost-effective while being guaranteed to be free of annotation errors. We compare the performance of 11 tools on benchmarks in English generated by BENGAL and on 16benchmarks created manually. We show that our approach can be ported easily across languages by presenting results achieved by 4 tools on both Brazilian Portuguese and Spanish. Overall, our results suggest that our automatic benchmark generation approach can create varied benchmarks that have characteristics similar to those of existing benchmarks. Our approach is open-source. Our experimental results are available at http://faturl.com/bengalexpinlg and the code at https://github.com/dice-group/BENGAL.
Entity Linking in 40 Languages using MAG
May 29, 2018


A plethora of Entity Linking (EL) approaches has recently been developed. While many claim to be multilingual, the MAG (Multilingual AGDISTIS) approach has been shown recently to outperform the state of the art in multilingual EL on 7 languages. With this demo, we extend MAG to support EL in 40 different languages, including especially low-resources languages such as Ukrainian, Greek, Hungarian, Croatian, Portuguese, Japanese and Korean. Our demo relies on online web services which allow for an easy access to our entity linking approaches and can disambiguate against DBpedia and Wikidata. During the demo, we will show how to use MAG by means of POST requests as well as using its user-friendly web interface. All data used in the demo is available at https://hobbitdata.informatik.uni-leipzig.de/agdistis/
Using Multi-Label Classification for Improved Question Answering
Oct 24, 2017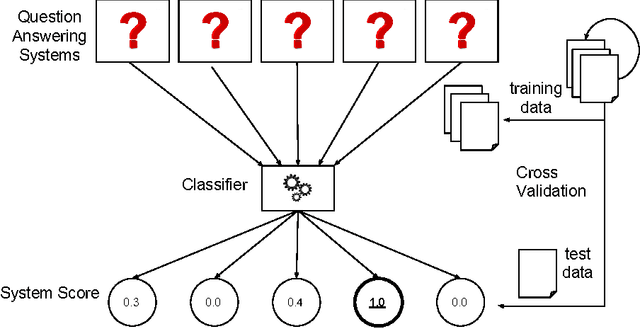


A plethora of diverse approaches for question answering over RDF data have been developed in recent years. While the accuracy of these systems has increased significantly over time, most systems still focus on particular types of questions or particular challenges in question answering. What is a curse for single systems is a blessing for the combination of these systems. We show in this paper how machine learning techniques can be applied to create a more accurate question answering metasystem by reusing existing systems. In particular, we develop a multi-label classification-based metasystem for question answering over 6 existing systems using an innovative set of 14 question features. The metasystem outperforms the best single system by 14% F-measure on the recent QALD-6 benchmark. Furthermore, we analyzed the influence and correlation of the underlying features on the metasystem quality.
MAG: A Multilingual, Knowledge-base Agnostic and Deterministic Entity Linking Approach
Oct 17, 2017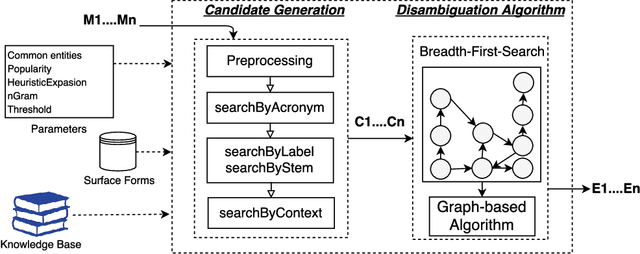

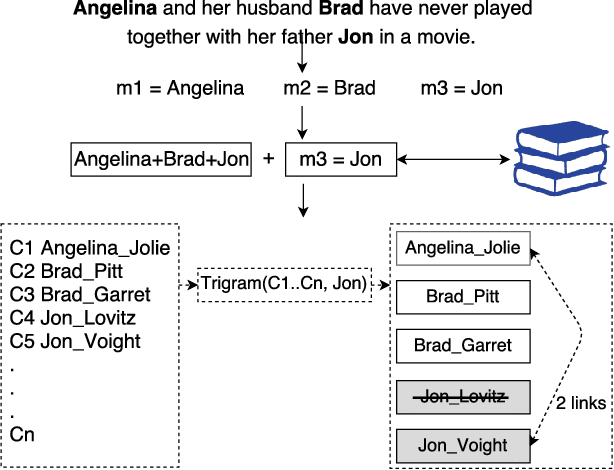
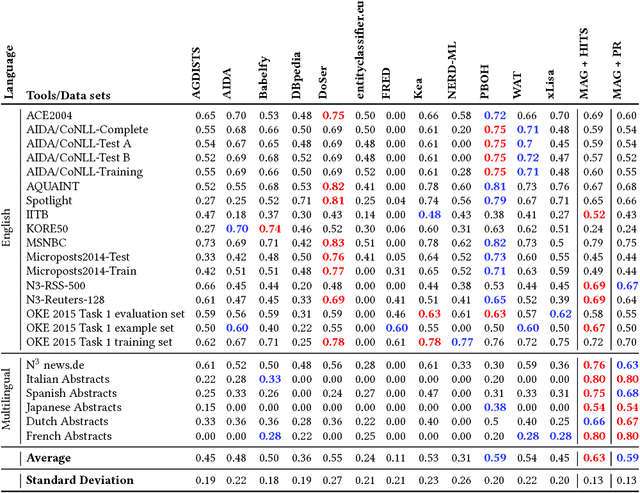
Entity linking has recently been the subject of a significant body of research. Currently, the best performing approaches rely on trained mono-lingual models. Porting these approaches to other languages is consequently a difficult endeavor as it requires corresponding training data and retraining of the models. We address this drawback by presenting a novel multilingual, knowledge-based agnostic and deterministic approach to entity linking, dubbed MAG. MAG is based on a combination of context-based retrieval on structured knowledge bases and graph algorithms. We evaluate MAG on 23 data sets and in 7 languages. Our results show that the best approach trained on English datasets (PBOH) achieves a micro F-measure that is up to 4 times worse on datasets in other languages. MAG, on the other hand, achieves state-of-the-art performance on English datasets and reaches a micro F-measure that is up to 0.6 higher than that of PBOH on non-English languages.
Evaluating topic coherence measures
Mar 25, 2014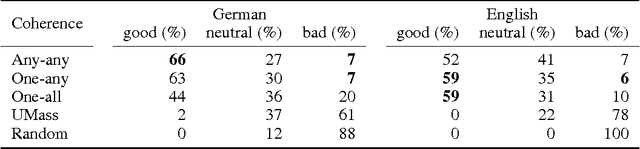
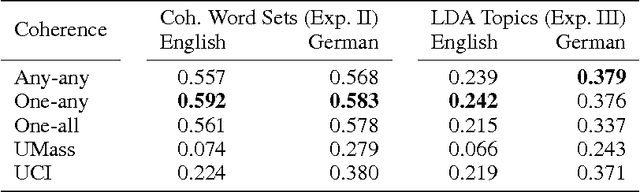
Topic models extract representative word sets - called topics - from word counts in documents without requiring any semantic annotations. Topics are not guaranteed to be well interpretable, therefore, coherence measures have been proposed to distinguish between good and bad topics. Studies of topic coherence so far are limited to measures that score pairs of individual words. For the first time, we include coherence measures from scientific philosophy that score pairs of more complex word subsets and apply them to topic scoring.