 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLOLA -- An Open-Source Massively Multilingual Large Language Model
Sep 19, 2024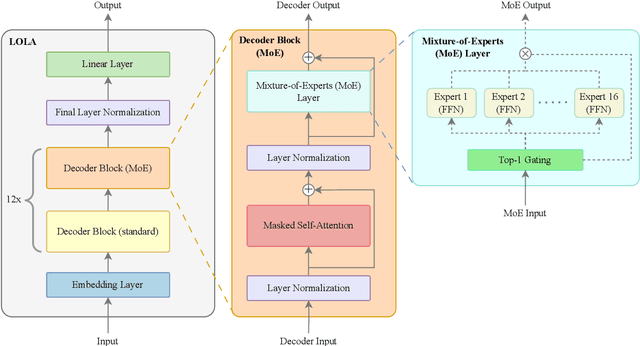
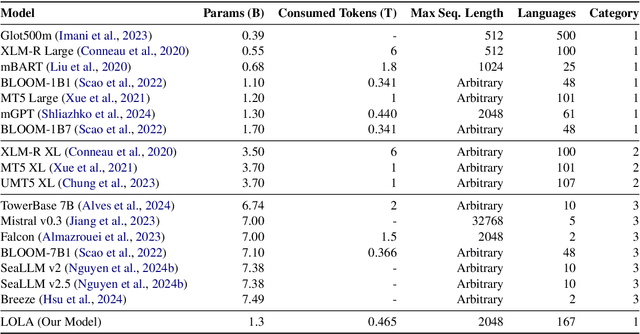
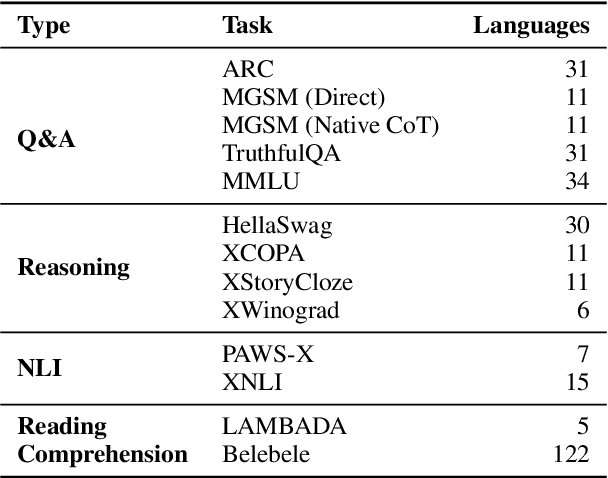
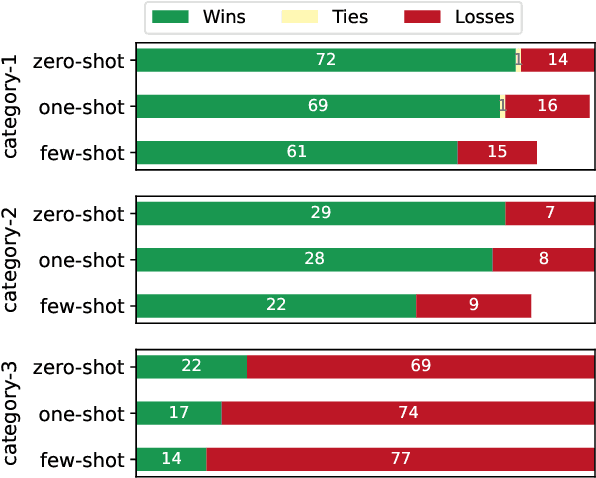
This paper presents LOLA, a massively multilingual large language model trained on more than 160 languages using a sparse Mixture-of-Experts Transformer architecture. Our architectural and implementation choices address the challenge of harnessing linguistic diversity while maintaining efficiency and avoiding the common pitfalls of multilinguality. Our analysis of the evaluation results shows competitive performance in natural language generation and understanding tasks. Additionally, we demonstrate how the learned expert-routing mechanism exploits implicit phylogenetic linguistic patterns to potentially alleviate the curse of multilinguality. We provide an in-depth look at the training process, an analysis of the datasets, and a balanced exploration of the model's strengths and limitations. As an open-source model, LOLA promotes reproducibility and serves as a robust foundation for future research. Our findings enable the development of compute-efficient multilingual models with strong, scalable performance across languages.
MasakhaNEWS: News Topic Classification for African languages
Apr 19, 2023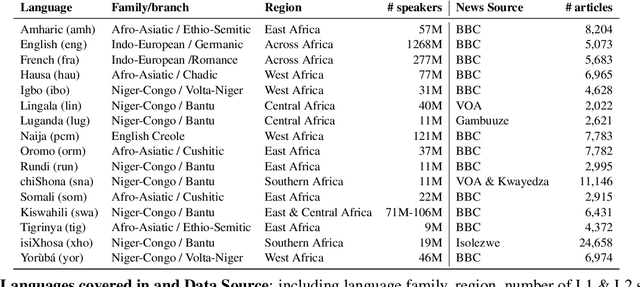
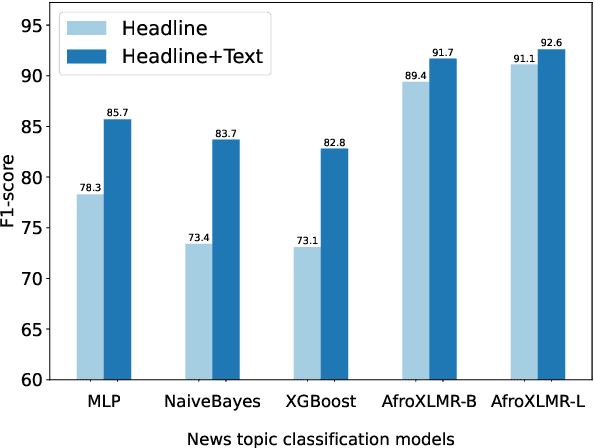
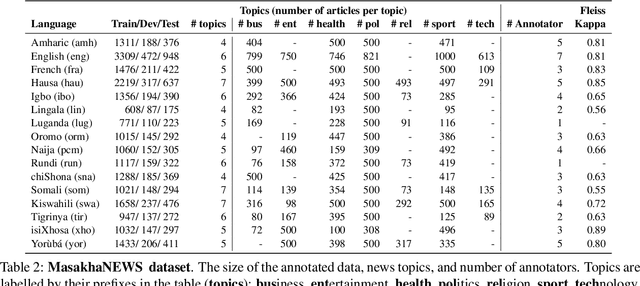
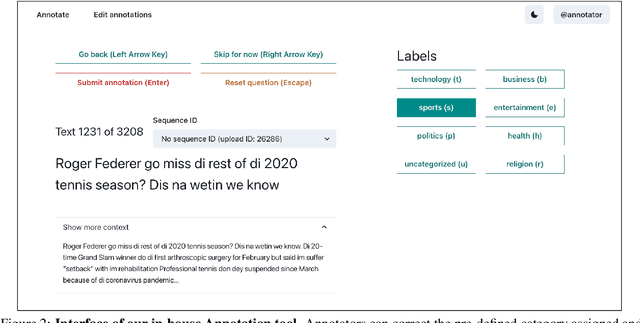
African languages are severely under-represented in NLP research due to lack of datasets covering several NLP tasks. While there are individual language specific datasets that are being expanded to different tasks, only a handful of NLP tasks (e.g. named entity recognition and machine translation) have standardized benchmark datasets covering several geographical and typologically-diverse African languages. In this paper, we develop MasakhaNEWS -- a new benchmark dataset for news topic classification covering 16 languages widely spoken in Africa. We provide an evaluation of baseline models by training classical machine learning models and fine-tuning several language models. Furthermore, we explore several alternatives to full fine-tuning of language models that are better suited for zero-shot and few-shot learning such as cross-lingual parameter-efficient fine-tuning (like MAD-X), pattern exploiting training (PET), prompting language models (like ChatGPT), and prompt-free sentence transformer fine-tuning (SetFit and Cohere Embedding API). Our evaluation in zero-shot setting shows the potential of prompting ChatGPT for news topic classification in low-resource African languages, achieving an average performance of 70 F1 points without leveraging additional supervision like MAD-X. In few-shot setting, we show that with as little as 10 examples per label, we achieved more than 90\% (i.e. 86.0 F1 points) of the performance of full supervised training (92.6 F1 points) leveraging the PET approach.