 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Benchmarking through the Lense of Concept Learning
Oct 23, 2025Evaluating competing systems in a comparable way, i.e., benchmarking them, is an undeniable pillar of the scientific method. However, system performance is often summarized via a small number of metrics. The analysis of the evaluation details and the derivation of insights for further development or use remains a tedious manual task with often biased results. Thus, this paper argues for a new type of benchmarking, which is dubbed explainable benchmarking. The aim of explainable benchmarking approaches is to automatically generate explanations for the performance of systems in a benchmark. We provide a first instantiation of this paradigm for knowledge-graph-based question answering systems. We compute explanations by using a novel concept learning approach developed for large knowledge graphs called PruneCEL. Our evaluation shows that PruneCEL outperforms state-of-the-art concept learners on the task of explainable benchmarking by up to 0.55 points F1 measure. A task-driven user study with 41 participants shows that in 80\% of the cases, the majority of participants can accurately predict the behavior of a system based on our explanations. Our code and data are available at https://github.com/dice-group/PruneCEL/tree/K-cap2025
LOLA -- An Open-Source Massively Multilingual Large Language Model
Sep 19, 2024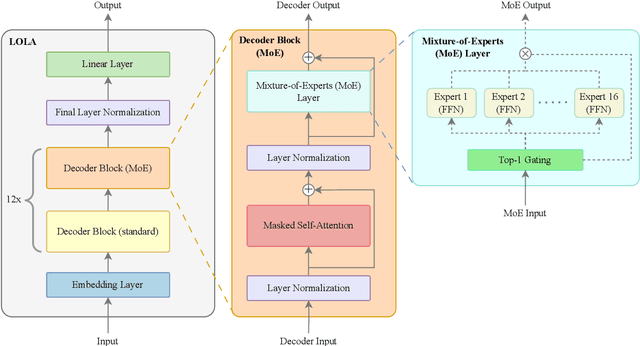
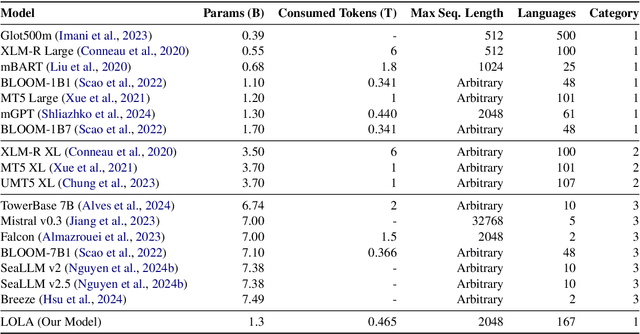
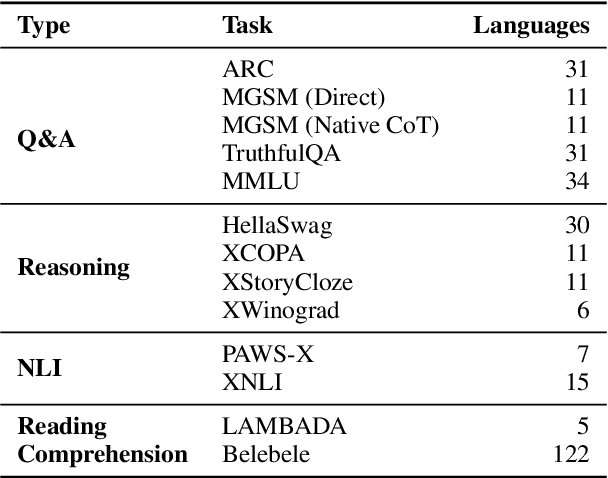
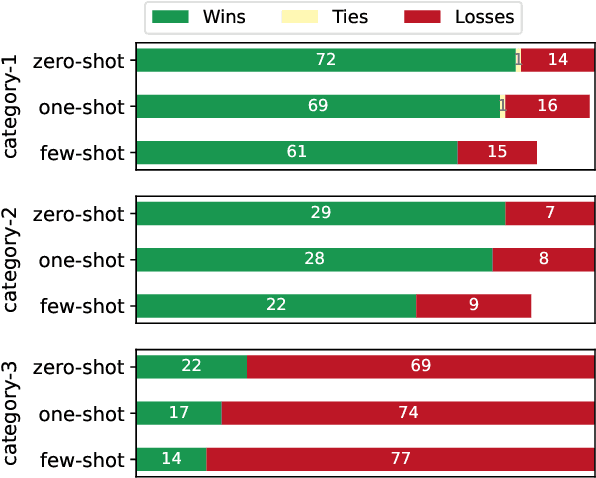
This paper presents LOLA, a massively multilingual large language model trained on more than 160 languages using a sparse Mixture-of-Experts Transformer architecture. Our architectural and implementation choices address the challenge of harnessing linguistic diversity while maintaining efficiency and avoiding the common pitfalls of multilinguality. Our analysis of the evaluation results shows competitive performance in natural language generation and understanding tasks. Additionally, we demonstrate how the learned expert-routing mechanism exploits implicit phylogenetic linguistic patterns to potentially alleviate the curse of multilinguality. We provide an in-depth look at the training process, an analysis of the datasets, and a balanced exploration of the model's strengths and limitations. As an open-source model, LOLA promotes reproducibility and serves as a robust foundation for future research. Our findings enable the development of compute-efficient multilingual models with strong, scalable performance across languages.
MST5 -- Multilingual Question Answering over Knowledge Graphs
Jul 08, 2024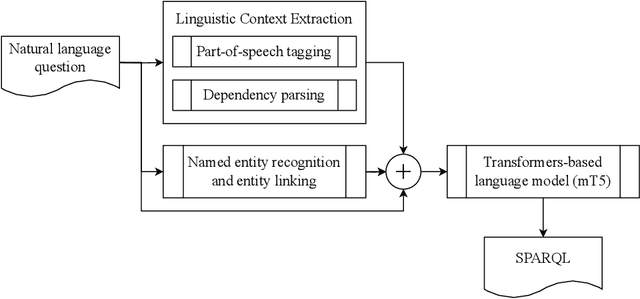
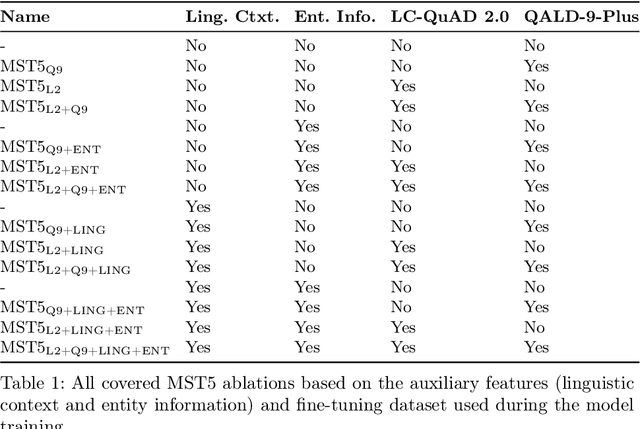

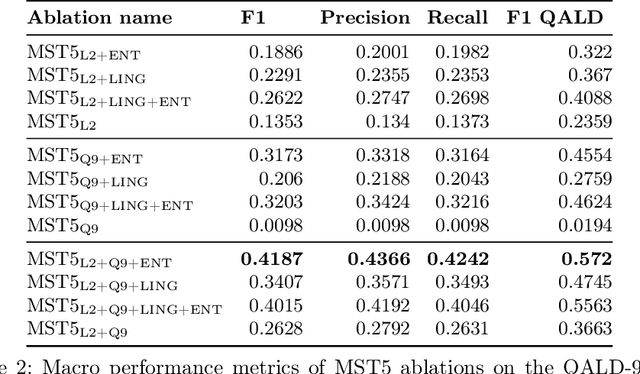
Knowledge Graph Question Answering (KGQA) simplifies querying vast amounts of knowledge stored in a graph-based model using natural language. However, the research has largely concentrated on English, putting non-English speakers at a disadvantage. Meanwhile, existing multilingual KGQA systems face challenges in achieving performance comparable to English systems, highlighting the difficulty of generating SPARQL queries from diverse languages. In this research, we propose a simplified approach to enhance multilingual KGQA systems by incorporating linguistic context and entity information directly into the processing pipeline of a language model. Unlike existing methods that rely on separate encoders for integrating auxiliary information, our strategy leverages a single, pretrained multilingual transformer-based language model to manage both the primary input and the auxiliary data. Our methodology significantly improves the language model's ability to accurately convert a natural language query into a relevant SPARQL query. It demonstrates promising results on the most recent QALD datasets, namely QALD-9-Plus and QALD-10. Furthermore, we introduce and evaluate our approach on Chinese and Japanese, thereby expanding the language diversity of the existing datasets.