 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMST5 -- Multilingual Question Answering over Knowledge Graphs
Jul 08, 2024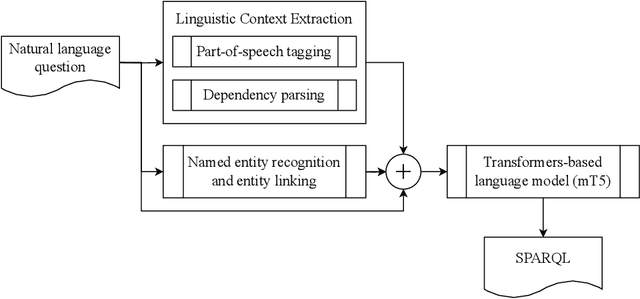
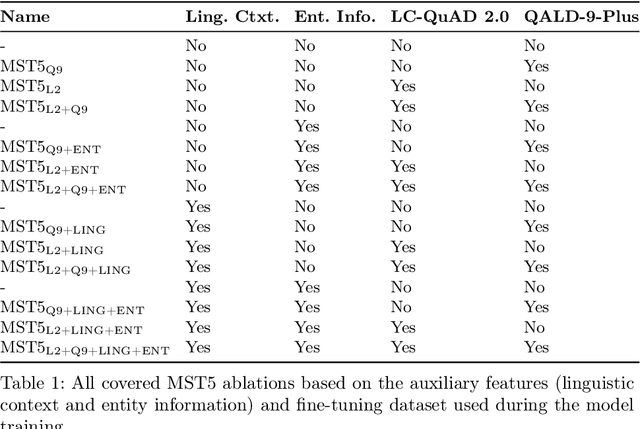

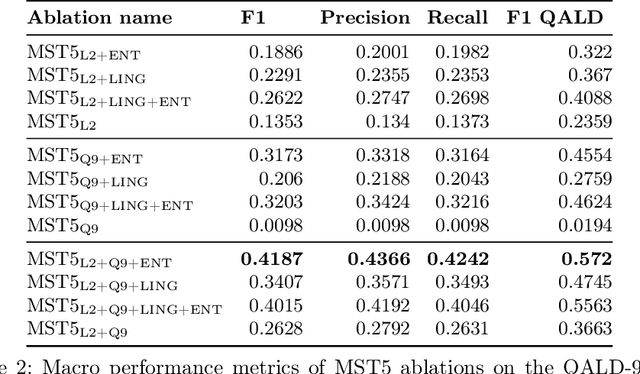
Knowledge Graph Question Answering (KGQA) simplifies querying vast amounts of knowledge stored in a graph-based model using natural language. However, the research has largely concentrated on English, putting non-English speakers at a disadvantage. Meanwhile, existing multilingual KGQA systems face challenges in achieving performance comparable to English systems, highlighting the difficulty of generating SPARQL queries from diverse languages. In this research, we propose a simplified approach to enhance multilingual KGQA systems by incorporating linguistic context and entity information directly into the processing pipeline of a language model. Unlike existing methods that rely on separate encoders for integrating auxiliary information, our strategy leverages a single, pretrained multilingual transformer-based language model to manage both the primary input and the auxiliary data. Our methodology significantly improves the language model's ability to accurately convert a natural language query into a relevant SPARQL query. It demonstrates promising results on the most recent QALD datasets, namely QALD-9-Plus and QALD-10. Furthermore, we introduce and evaluate our approach on Chinese and Japanese, thereby expanding the language diversity of the existing datasets.
Knowledge Graph Question Answering using Graph-Pattern Isomorphism
Mar 11, 2021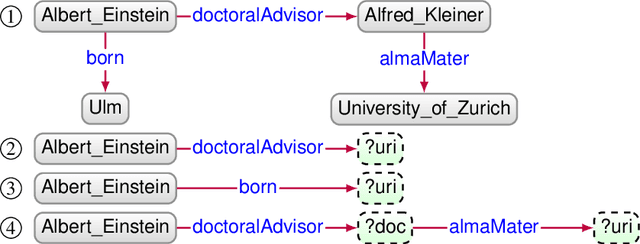

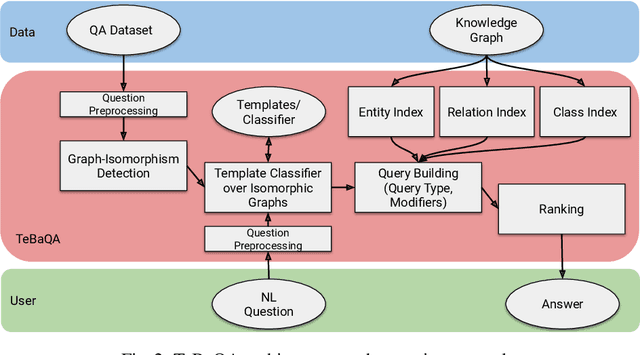

Knowledge Graph Question Answering (KGQA) systems are based on machine learning algorithms, requiring thousands of question-answer pairs as training examples or natural language processing pipelines that need module fine-tuning. In this paper, we present a novel QA approach, dubbed TeBaQA. Our approach learns to answer questions based on graph isomorphisms from basic graph patterns of SPARQL queries. Learning basic graph patterns is efficient due to the small number of possible patterns. This novel paradigm reduces the amount of training data necessary to achieve state-of-the-art performance. TeBaQA also speeds up the domain adaption process by transforming the QA system development task into a much smaller and easier data compilation task. In our evaluation, TeBaQA achieves state-of-the-art performance on QALD-8 and delivers comparable results on QALD-9 and LC-QuAD v1. Additionally, we performed a fine-grained evaluation on complex queries that deal with aggregation and superlative questions as well as an ablation study, highlighting future research challenges.