 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Retrieve with Weakened Labels: Robust Training under Label Noise
Dec 15, 2025


Neural Encoders are frequently used in the NLP domain to perform dense retrieval tasks, for instance, to generate the candidate documents for a given query in question-answering tasks. However, sparse annotation and label noise in the training data make it challenging to train or fine-tune such retrieval models. Although existing works have attempted to mitigate these problems by incorporating modified loss functions or data cleaning, these approaches either require some hyperparameters to tune during training or add substantial complexity to the training setup. In this work, we consider a label weakening approach to generate robust retrieval models in the presence of label noise. Instead of enforcing a single, potentially erroneous label for each query document pair, we allow for a set of plausible labels derived from both the observed supervision and the model's confidence scores. We perform an extensive evaluation considering two retrieval models, one re-ranking model, considering four diverse ranking datasets. To this end, we also consider a realistic noisy setting by using a semantic-aware noise generation technique to generate different ratios of noise. Our initial results show that label weakening can improve the performance of the retrieval tasks in comparison to 10 different state-of-the-art loss functions.
Diving Deep: Forecasting Sea Surface Temperatures and Anomalies
Jan 10, 2025This overview paper details the findings from the Diving Deep: Forecasting Sea Surface Temperatures and Anomalies Challenge at the European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD) 2024. The challenge focused on the data-driven predictability of global sea surface temperatures (SSTs), a key factor in climate forecasting, ecosystem management, fisheries management, and climate change monitoring. The challenge involved forecasting SST anomalies (SSTAs) three months in advance using historical data and included a special task of predicting SSTAs nine months ahead for the Baltic Sea. Participants utilized various machine learning approaches to tackle the task, leveraging data from ERA5. This paper discusses the methodologies employed, the results obtained, and the lessons learned, offering insights into the future of climate-related predictive modeling.
Resilience in Knowledge Graph Embeddings
Oct 28, 2024In recent years, knowledge graphs have gained interest and witnessed widespread applications in various domains, such as information retrieval, question-answering, recommendation systems, amongst others. Large-scale knowledge graphs to this end have demonstrated their utility in effectively representing structured knowledge. To further facilitate the application of machine learning techniques, knowledge graph embedding (KGE) models have been developed. Such models can transform entities and relationships within knowledge graphs into vectors. However, these embedding models often face challenges related to noise, missing information, distribution shift, adversarial attacks, etc. This can lead to sub-optimal embeddings and incorrect inferences, thereby negatively impacting downstream applications. While the existing literature has focused so far on adversarial attacks on KGE models, the challenges related to the other critical aspects remain unexplored. In this paper, we, first of all, give a unified definition of resilience, encompassing several factors such as generalisation, performance consistency, distribution adaption, and robustness. After formalizing these concepts for machine learning in general, we define them in the context of knowledge graphs. To find the gap in the existing works on resilience in the context of knowledge graphs, we perform a systematic survey, taking into account all these aspects mentioned previously. Our survey results show that most of the existing works focus on a specific aspect of resilience, namely robustness. After categorizing such works based on their respective aspects of resilience, we discuss the challenges and future research directions.
Inference over Unseen Entities, Relations and Literals on Knowledge Graphs
Oct 09, 2024
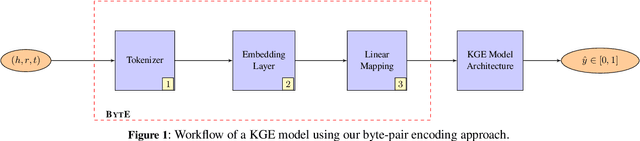

In recent years, knowledge graph embedding models have been successfully applied in the transductive setting to tackle various challenging tasks including link prediction, and query answering. Yet, the transductive setting does not allow for reasoning over unseen entities, relations, let alone numerical or non-numerical literals. Although increasing efforts are put into exploring inductive scenarios, inference over unseen entities, relations, and literals has yet to come. This limitation prohibits the existing methods from handling real-world dynamic knowledge graphs involving heterogeneous information about the world. Here, we propose a remedy to this limitation. We propose the attentive byte-pair encoding layer (BytE) to construct a triple embedding from a sequence of byte-pair encoded subword units of entities and relations. Compared to the conventional setting, BytE leads to massive feature reuse via weight tying, since it forces a knowledge graph embedding model to learn embeddings for subword units instead of entities and relations directly. Consequently, the size of the embedding matrices are not anymore bound to the unique number of entities and relations of a knowledge graph. Experimental results show that BytE improves the link prediction performance of 4 knowledge graph embedding models on datasets where the syntactic representations of triples are semantically meaningful. However, benefits of training a knowledge graph embedding model with BytE dissipate on knowledge graphs where entities and relations are represented with plain numbers or URIs. We provide an open source implementation of BytE to foster reproducible research.
Performance Evaluation of Knowledge Graph Embedding Approaches under Non-adversarial Attacks
Jul 09, 2024



Knowledge Graph Embedding (KGE) transforms a discrete Knowledge Graph (KG) into a continuous vector space facilitating its use in various AI-driven applications like Semantic Search, Question Answering, or Recommenders. While KGE approaches are effective in these applications, most existing approaches assume that all information in the given KG is correct. This enables attackers to influence the output of these approaches, e.g., by perturbing the input. Consequently, the robustness of such KGE approaches has to be addressed. Recent work focused on adversarial attacks. However, non-adversarial attacks on all attack surfaces of these approaches have not been thoroughly examined. We close this gap by evaluating the impact of non-adversarial attacks on the performance of 5 state-of-the-art KGE algorithms on 5 datasets with respect to attacks on 3 attack surfaces-graph, parameter, and label perturbation. Our evaluation results suggest that label perturbation has a strong effect on the KGE performance, followed by parameter perturbation with a moderate and graph with a low effect.
Adaptive Stochastic Weight Averaging
Jun 27, 2024



Ensemble models often improve generalization performances in challenging tasks. Yet, traditional techniques based on prediction averaging incur three well-known disadvantages: the computational overhead of training multiple models, increased latency, and memory requirements at test time. To address these issues, the Stochastic Weight Averaging (SWA) technique maintains a running average of model parameters from a specific epoch onward. Despite its potential benefits, maintaining a running average of parameters can hinder generalization, as an underlying running model begins to overfit. Conversely, an inadequately chosen starting point can render SWA more susceptible to underfitting compared to an underlying running model. In this work, we propose Adaptive Stochastic Weight Averaging (ASWA) technique that updates a running average of model parameters, only when generalization performance is improved on the validation dataset. Hence, ASWA can be seen as a combination of SWA with the early stopping technique, where the former accepts all updates on a parameter ensemble model and the latter rejects any update on an underlying running model. We conducted extensive experiments ranging from image classification to multi-hop reasoning over knowledge graphs. Our experiments over 11 benchmark datasets with 7 baseline models suggest that ASWA leads to a statistically better generalization across models and datasets
EGNN-C+: Interpretable Evolving Granular Neural Network and Application in Classification of Weakly-Supervised EEG Data Streams
Feb 26, 2024



We introduce a modified incremental learning algorithm for evolving Granular Neural Network Classifiers (eGNN-C+). We use double-boundary hyper-boxes to represent granules, and customize the adaptation procedures to enhance the robustness of outer boxes for data coverage and noise suppression, while ensuring that inner boxes remain flexible to capture drifts. The classifier evolves from scratch, incorporates new classes on the fly, and performs local incremental feature weighting. As an application, we focus on the classification of emotion-related patterns within electroencephalogram (EEG) signals. Emotion recognition is crucial for enhancing the realism and interactivity of computer systems. We extract features from the Fourier spectrum of EEG signals obtained from 28 individuals engaged in playing computer games -- a public dataset. Each game elicits a different predominant emotion: boredom, calmness, horror, or joy. We analyze individual electrodes, time window lengths, and frequency bands to assess the accuracy and interpretability of resulting user-independent neural models. The findings indicate that both brain hemispheres assist classification, especially electrodes on the temporal (T8) and parietal (P7) areas, alongside contributions from frontal and occipital electrodes. While patterns may manifest in any band, the Alpha (8-13Hz), Delta (1-4Hz), and Theta (4-8Hz) bands, in this order, exhibited higher correspondence with the emotion classes. The eGNN-C+ demonstrates effectiveness in learning EEG data. It achieves an accuracy of 81.7% and a 0.0029 II interpretability using 10-second time windows, even in face of a highly-stochastic time-varying 4-class classification problem.
Testing Monotonicity of Machine Learning Models
Feb 27, 2020

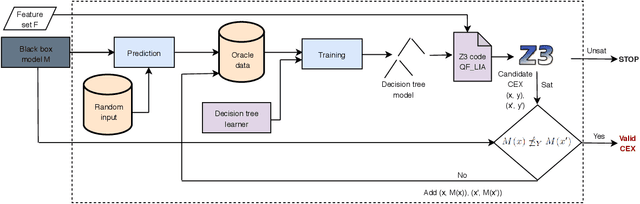

Today, machine learning (ML) models are increasingly applied in decision making. This induces an urgent need for quality assurance of ML models with respect to (often domain-dependent) requirements. Monotonicity is one such requirement. It specifies a software as 'learned' by an ML algorithm to give an increasing prediction with the increase of some attribute values. While there exist multiple ML algorithms for ensuring monotonicity of the generated model, approaches for checking monotonicity, in particular of black-box models, are largely lacking. In this work, we propose verification-based testing of monotonicity, i.e., the formal computation of test inputs on a white-box model via verification technology, and the automatic inference of this approximating white-box model from the black-box model under test. On the white-box model, the space of test inputs can be systematically explored by a directed computation of test cases. The empirical evaluation on 90 black-box models shows verification-based testing can outperform adaptive random testing as well as property-based techniques with respect to effectiveness and efficiency.