 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Postconditions: Can Large Language Models infer Formal Contracts for Automatic Software Verification?
Oct 14, 2025
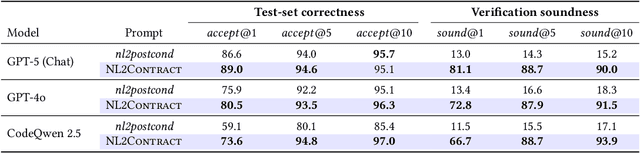
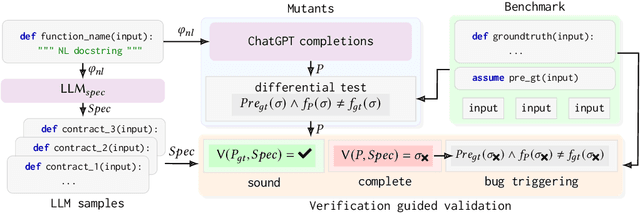
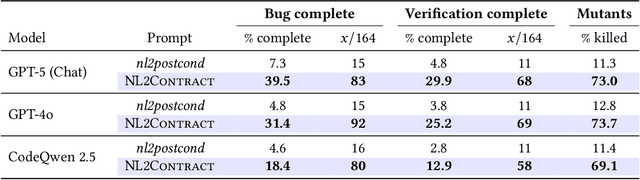
Automatic software verifiers have become increasingly effective at the task of checking software against (formal) specifications. Yet, their adoption in practice has been hampered by the lack of such specifications in real world code. Large Language Models (LLMs) have shown promise in inferring formal postconditions from natural language hints embedded in code such as function names, comments or documentation. Using the generated postconditions as specifications in a subsequent verification, however, often leads verifiers to suggest invalid inputs, hinting at potential issues that ultimately turn out to be false alarms. To address this, we revisit the problem of specification inference from natural language in the context of automatic software verification. In the process, we introduce NL2Contract, the task of employing LLMs to translate informal natural language into formal functional contracts, consisting of postconditions as well as preconditions. We introduce metrics to validate and compare different NL2Contract approaches, using soundness, bug discriminative power of the generated contracts and their usability in the context of automatic software verification as key metrics. We evaluate NL2Contract with different LLMs and compare it to the task of postcondition generation nl2postcond. Our evaluation shows that (1) LLMs are generally effective at generating functional contracts sound for all possible inputs, (2) the generated contracts are sufficiently expressive for discriminating buggy from correct behavior, and (3) verifiers supplied with LLM inferred functional contracts produce fewer false alarms than when provided with postconditions alone. Further investigations show that LLM inferred preconditions generally align well with developers intentions which allows us to use automatic software verifiers to catch real-world bugs.
Can ChatGPT support software verification?
Nov 04, 2023Large language models have become increasingly effective in software engineering tasks such as code generation, debugging and repair. Language models like ChatGPT can not only generate code, but also explain its inner workings and in particular its correctness. This raises the question whether we can utilize ChatGPT to support formal software verification. In this paper, we take some first steps towards answering this question. More specifically, we investigate whether ChatGPT can generate loop invariants. Loop invariant generation is a core task in software verification, and the generation of valid and useful invariants would likely help formal verifiers. To provide some first evidence on this hypothesis, we ask ChatGPT to annotate 106 C programs with loop invariants. We check validity and usefulness of the generated invariants by passing them to two verifiers, Frama-C and CPAchecker. Our evaluation shows that ChatGPT is able to produce valid and useful invariants allowing Frama-C to verify tasks that it could not solve before. Based on our initial insights, we propose ways of combining ChatGPT (or large language models in general) and software verifiers, and discuss current limitations and open issues.
Can we learn from developer mistakes? Learning to localize and repair real bugs from real bug fixes
Jul 01, 2022



Real bug fixes found in open source repositories seem to be the perfect source for learning to localize and repair real bugs. However, the absence of large scale bug fix collections has made it difficult to effectively exploit real bug fixes in the training of larger neural models in the past. In contrast, artificial bugs -- produced by mutating existing source code -- can be easily obtained at a sufficient scale and are therefore often preferred in the training of existing approaches. Still, localization and repair models that are trained on artificial bugs usually underperform when faced with real bugs. This raises the question whether bug localization and repair models trained on real bug fixes are more effective in localizing and repairing real bugs. We address this question by introducing RealiT, a pre-train-and-fine-tune approach for effectively learning to localize and repair real bugs from real bug fixes. RealiT is first pre-trained on a large number of artificial bugs produced by traditional mutation operators and then fine-tuned on a smaller set of real bug fixes. Fine-tuning does not require any modifications of the learning algorithm and hence can be easily adopted in various training scenarios for bug localization or repair (even when real training data is scarce). In addition, we found that training on real bug fixes with RealiT is empirically powerful by nearly doubling the localization performance of an existing model on real bugs while maintaining or even improving the repair performance.
DeepMutants: Training neural bug detectors with contextual mutations
Jul 14, 2021



Learning-based bug detectors promise to find bugs in large code bases by exploiting natural hints such as names of variables and functions or comments. Still, existing techniques tend to underperform when presented with realistic bugs. We believe bug detector learning to currently suffer from a lack of realistic defective training examples. In fact, real world bugs are scarce which has driven existing methods to train on artificially created and mostly unrealistic mutants. In this work, we propose a novel contextual mutation operator which incorporates knowledge about the mutation context to dynamically inject natural and more realistic faults into code. Our approach employs a masked language model to produce a context-dependent distribution over feasible token replacements. The evaluation shows that sampling from a language model does not only produce mutants which more accurately represent real bugs but also lead to better performing bug detectors, both on artificial benchmarks and on real world source code.
Testing Monotonicity of Machine Learning Models
Feb 27, 2020

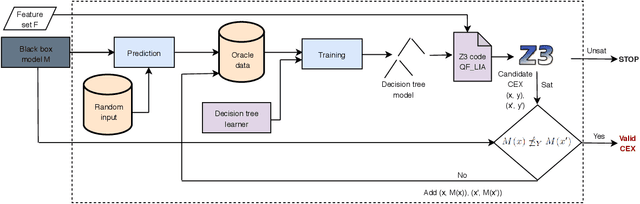

Today, machine learning (ML) models are increasingly applied in decision making. This induces an urgent need for quality assurance of ML models with respect to (often domain-dependent) requirements. Monotonicity is one such requirement. It specifies a software as 'learned' by an ML algorithm to give an increasing prediction with the increase of some attribute values. While there exist multiple ML algorithms for ensuring monotonicity of the generated model, approaches for checking monotonicity, in particular of black-box models, are largely lacking. In this work, we propose verification-based testing of monotonicity, i.e., the formal computation of test inputs on a white-box model via verification technology, and the automatic inference of this approximating white-box model from the black-box model under test. On the white-box model, the space of test inputs can be systematically explored by a directed computation of test cases. The empirical evaluation on 90 black-box models shows verification-based testing can outperform adaptive random testing as well as property-based techniques with respect to effectiveness and efficiency.
Predicting Rankings of Software Verification Competitions
Mar 02, 2017


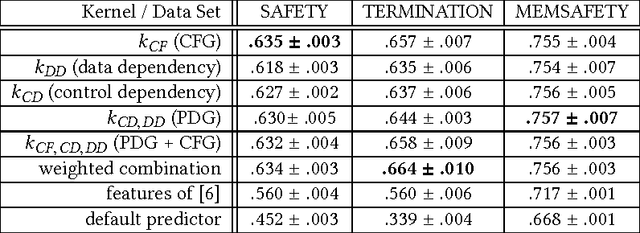
Software verification competitions, such as the annual SV-COMP, evaluate software verification tools with respect to their effectivity and efficiency. Typically, the outcome of a competition is a (possibly category-specific) ranking of the tools. For many applications, such as building portfolio solvers, it would be desirable to have an idea of the (relative) performance of verification tools on a given verification task beforehand, i.e., prior to actually running all tools on the task. In this paper, we present a machine learning approach to predicting rankings of tools on verification tasks. The method builds upon so-called label ranking algorithms, which we complement with appropriate kernels providing a similarity measure for verification tasks. Our kernels employ a graph representation for software source code that mixes elements of control flow and program dependence graphs with abstract syntax trees. Using data sets from SV-COMP, we demonstrate our rank prediction technique to generalize well and achieve a rather high predictive accuracy. In particular, our method outperforms a recently proposed feature-based approach of Demyanova et al. (when applied to rank predictions).