 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Rankings of Software Verification Competitions
Mar 02, 2017


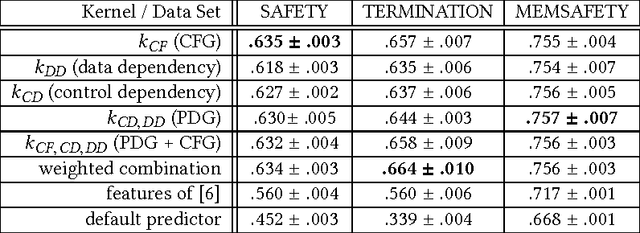
Software verification competitions, such as the annual SV-COMP, evaluate software verification tools with respect to their effectivity and efficiency. Typically, the outcome of a competition is a (possibly category-specific) ranking of the tools. For many applications, such as building portfolio solvers, it would be desirable to have an idea of the (relative) performance of verification tools on a given verification task beforehand, i.e., prior to actually running all tools on the task. In this paper, we present a machine learning approach to predicting rankings of tools on verification tasks. The method builds upon so-called label ranking algorithms, which we complement with appropriate kernels providing a similarity measure for verification tasks. Our kernels employ a graph representation for software source code that mixes elements of control flow and program dependence graphs with abstract syntax trees. Using data sets from SV-COMP, we demonstrate our rank prediction technique to generalize well and achieve a rather high predictive accuracy. In particular, our method outperforms a recently proposed feature-based approach of Demyanova et al. (when applied to rank predictions).