 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference over Unseen Entities, Relations and Literals on Knowledge Graphs
Paper and Code

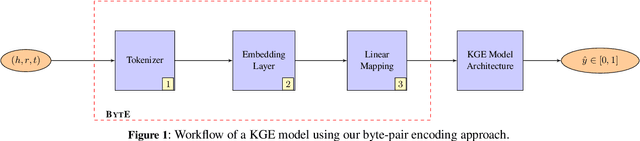

In recent years, knowledge graph embedding models have been successfully applied in the transductive setting to tackle various challenging tasks including link prediction, and query answering. Yet, the transductive setting does not allow for reasoning over unseen entities, relations, let alone numerical or non-numerical literals. Although increasing efforts are put into exploring inductive scenarios, inference over unseen entities, relations, and literals has yet to come. This limitation prohibits the existing methods from handling real-world dynamic knowledge graphs involving heterogeneous information about the world. Here, we propose a remedy to this limitation. We propose the attentive byte-pair encoding layer (BytE) to construct a triple embedding from a sequence of byte-pair encoded subword units of entities and relations. Compared to the conventional setting, BytE leads to massive feature reuse via weight tying, since it forces a knowledge graph embedding model to learn embeddings for subword units instead of entities and relations directly. Consequently, the size of the embedding matrices are not anymore bound to the unique number of entities and relations of a knowledge graph. Experimental results show that BytE improves the link prediction performance of 4 knowledge graph embedding models on datasets where the syntactic representations of triples are semantically meaningful. However, benefits of training a knowledge graph embedding model with BytE dissipate on knowledge graphs where entities and relations are represented with plain numbers or URIs. We provide an open source implementation of BytE to foster reproducible research.