 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReporting and Analysing the Environmental Impact of Language Models on the Example of Commonsense Question Answering with External Knowledge
Paper and Code
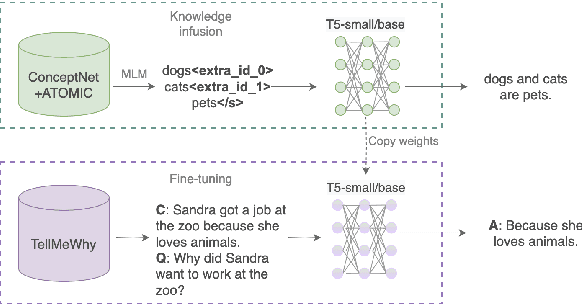
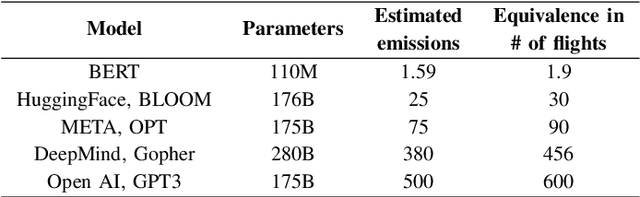
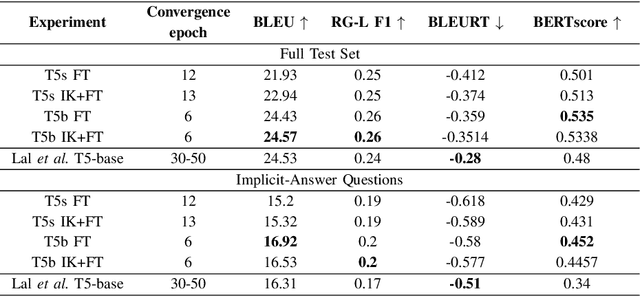
Human-produced emissions are growing at an alarming rate, causing already observable changes in the climate and environment in general. Each year global carbon dioxide emissions hit a new record, and it is reported that 0.5% of total US greenhouse gas emissions are attributed to data centres as of 2021. The release of ChatGPT in late 2022 sparked social interest in Large Language Models (LLMs), the new generation of Language Models with a large number of parameters and trained on massive amounts of data. Currently, numerous companies are releasing products featuring various LLMs, with many more models in development and awaiting release. Deep Learning research is a competitive field, with only models that reach top performance attracting attention and being utilized. Hence, achieving better accuracy and results is often the first priority, while the model's efficiency and the environmental impact of the study are neglected. However, LLMs demand substantial computational resources and are very costly to train, both financially and environmentally. It becomes essential to raise awareness and promote conscious decisions about algorithmic and hardware choices. Providing information on training time, the approximate carbon dioxide emissions and power consumption would assist future studies in making necessary adjustments and determining the compatibility of available computational resources with model requirements. In this study, we infused T5 LLM with external knowledge and fine-tuned the model for Question-Answering task. Furthermore, we calculated and reported the approximate environmental impact for both steps. The findings demonstrate that the smaller models may not always be sustainable options, and increased training does not always imply better performance. The most optimal outcome is achieved by carefully considering both performance and efficiency factors.