 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDBLPLink 2.0 -- An Entity Linker for the DBLP Scholarly Knowledge Graph
Jul 30, 2025


In this work we present an entity linker for DBLP's 2025 version of RDF-based Knowledge Graph. Compared to the 2022 version, DBLP now considers publication venues as a new entity type called dblp:Stream. In the earlier version of DBLPLink, we trained KG-embeddings and re-rankers on a dataset to produce entity linkings. In contrast, in this work, we develop a zero-shot entity linker using LLMs using a novel method, where we re-rank candidate entities based on the log-probabilities of the "yes" token output at the penultimate layer of the LLM.
Hybrid-SQuAD: Hybrid Scholarly Question Answering Dataset
Dec 05, 2024Existing Scholarly Question Answering (QA) methods typically target homogeneous data sources, relying solely on either text or Knowledge Graphs (KGs). However, scholarly information often spans heterogeneous sources, necessitating the development of QA systems that integrate information from multiple heterogeneous data sources. To address this challenge, we introduce Hybrid-SQuAD (Hybrid Scholarly Question Answering Dataset), a novel large-scale QA dataset designed to facilitate answering questions incorporating both text and KG facts. The dataset consists of 10.5K question-answer pairs generated by a large language model, leveraging the KGs DBLP and SemOpenAlex alongside corresponding text from Wikipedia. In addition, we propose a RAG-based baseline hybrid QA model, achieving an exact match score of 69.65 on the Hybrid-SQuAD test set.
Reporting and Analysing the Environmental Impact of Language Models on the Example of Commonsense Question Answering with External Knowledge
Jul 24, 2024
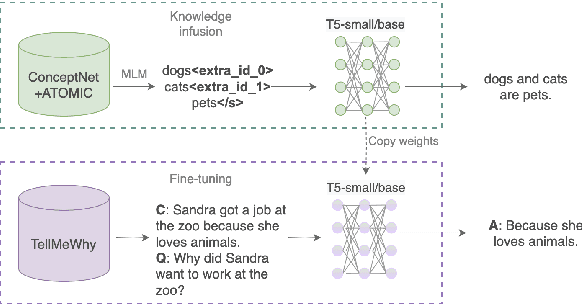
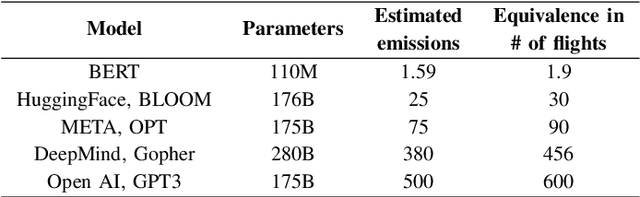
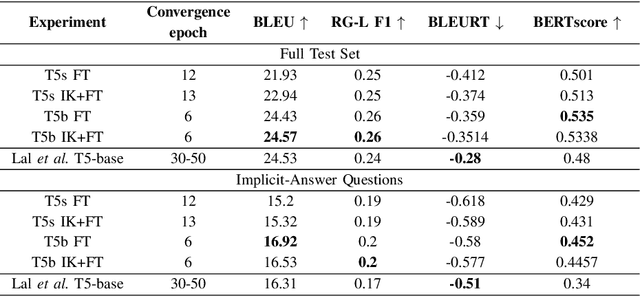
Human-produced emissions are growing at an alarming rate, causing already observable changes in the climate and environment in general. Each year global carbon dioxide emissions hit a new record, and it is reported that 0.5% of total US greenhouse gas emissions are attributed to data centres as of 2021. The release of ChatGPT in late 2022 sparked social interest in Large Language Models (LLMs), the new generation of Language Models with a large number of parameters and trained on massive amounts of data. Currently, numerous companies are releasing products featuring various LLMs, with many more models in development and awaiting release. Deep Learning research is a competitive field, with only models that reach top performance attracting attention and being utilized. Hence, achieving better accuracy and results is often the first priority, while the model's efficiency and the environmental impact of the study are neglected. However, LLMs demand substantial computational resources and are very costly to train, both financially and environmentally. It becomes essential to raise awareness and promote conscious decisions about algorithmic and hardware choices. Providing information on training time, the approximate carbon dioxide emissions and power consumption would assist future studies in making necessary adjustments and determining the compatibility of available computational resources with model requirements. In this study, we infused T5 LLM with external knowledge and fine-tuned the model for Question-Answering task. Furthermore, we calculated and reported the approximate environmental impact for both steps. The findings demonstrate that the smaller models may not always be sustainable options, and increased training does not always imply better performance. The most optimal outcome is achieved by carefully considering both performance and efficiency factors.
DBLPLink: An Entity Linker for the DBLP Scholarly Knowledge Graph
Sep 25, 2023In this work, we present a web application named DBLPLink, which performs entity linking over the DBLP scholarly knowledge graph. DBLPLink uses text-to-text pre-trained language models, such as T5, to produce entity label spans from an input text question. Entity candidates are fetched from a database based on the labels, and an entity re-ranker sorts them based on entity embeddings, such as TransE, DistMult and ComplEx. The results are displayed so that users may compare and contrast the results between T5-small, T5-base and the different KG embeddings used. The demo can be accessed at https://ltdemos.informatik.uni-hamburg.de/dblplink/.
The Role of Output Vocabulary in T2T LMs for SPARQL Semantic Parsing
May 24, 2023



In this work, we analyse the role of output vocabulary for text-to-text (T2T) models on the task of SPARQL semantic parsing. We perform experiments within the the context of knowledge graph question answering (KGQA), where the task is to convert questions in natural language to the SPARQL query language. We observe that the query vocabulary is distinct from human vocabulary. Language Models (LMs) are pre-dominantly trained for human language tasks, and hence, if the query vocabulary is replaced with a vocabulary more attuned to the LM tokenizer, the performance of models may improve. We carry out carefully selected vocabulary substitutions on the queries and find absolute gains in the range of 17% on the GrailQA dataset.
DBLP-QuAD: A Question Answering Dataset over the DBLP Scholarly Knowledge Graph
Mar 29, 2023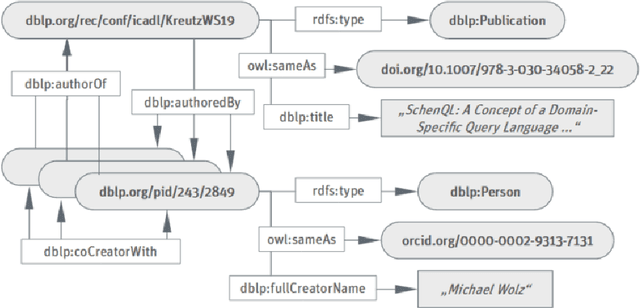
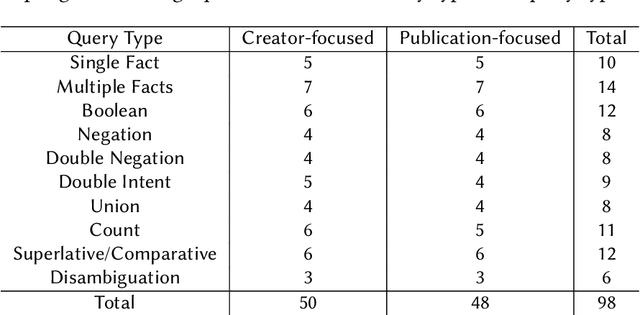
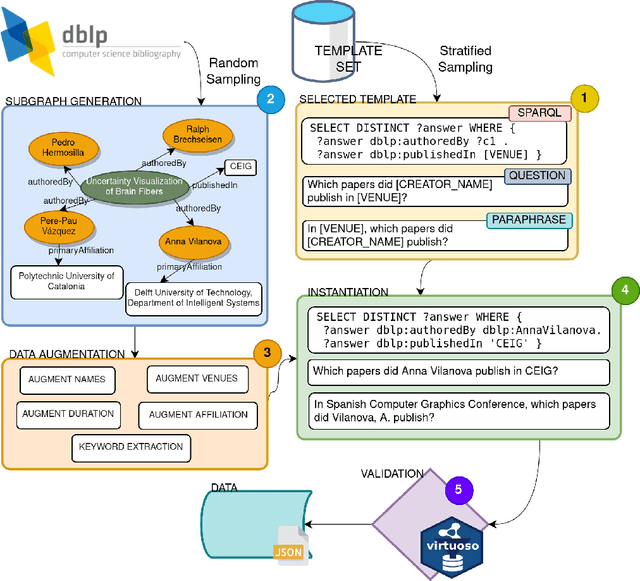
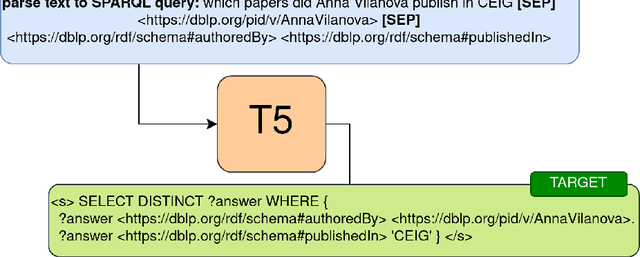
In this work we create a question answering dataset over the DBLP scholarly knowledge graph (KG). DBLP is an on-line reference for bibliographic information on major computer science publications that indexes over 4.4 million publications published by more than 2.2 million authors. Our dataset consists of 10,000 question answer pairs with the corresponding SPARQL queries which can be executed over the DBLP KG to fetch the correct answer. DBLP-QuAD is the largest scholarly question answering dataset.
GETT-QA: Graph Embedding based T2T Transformer for Knowledge Graph Question Answering
Mar 28, 2023



In this work, we present an end-to-end Knowledge Graph Question Answering (KGQA) system named GETT-QA. GETT-QA uses T5, a popular text-to-text pre-trained language model. The model takes a question in natural language as input and produces a simpler form of the intended SPARQL query. In the simpler form, the model does not directly produce entity and relation IDs. Instead, it produces corresponding entity and relation labels. The labels are grounded to KG entity and relation IDs in a subsequent step. To further improve the results, we instruct the model to produce a truncated version of the KG embedding for each entity. The truncated KG embedding enables a finer search for disambiguation purposes. We find that T5 is able to learn the truncated KG embeddings without any change of loss function, improving KGQA performance. As a result, we report strong results for LC-QuAD 2.0 and SimpleQuestions-Wikidata datasets on end-to-end KGQA over Wikidata.
A System for Human-AI collaboration for Online Customer Support
Feb 07, 2023



AI enabled chat bots have recently been put to use to answer customer service queries, however it is a common feedback of users that bots lack a personal touch and are often unable to understand the real intent of the user's question. To this end, it is desirable to have human involvement in the customer servicing process. In this work, we present a system where a human support agent collaborates in real-time with an AI agent to satisfactorily answer customer queries. We describe the user interaction elements of the solution, along with the machine learning techniques involved in the AI agent.
ARDIAS: AI-Enhanced Research Management, Discovery, and Advisory System
Jan 25, 2023



In this work, we present ARDIAS, a web-based application that aims to provide researchers with a full suite of discovery and collaboration tools. ARDIAS currently allows searching for authors and articles by name and gaining insights into the research topics of a particular researcher. With the aid of AI-based tools, ARDIAS aims to recommend potential collaborators and topics to researchers. In the near future, we aim to add tools that allow researchers to communicate with each other and start new projects.
Modern Baselines for SPARQL Semantic Parsing
Apr 27, 2022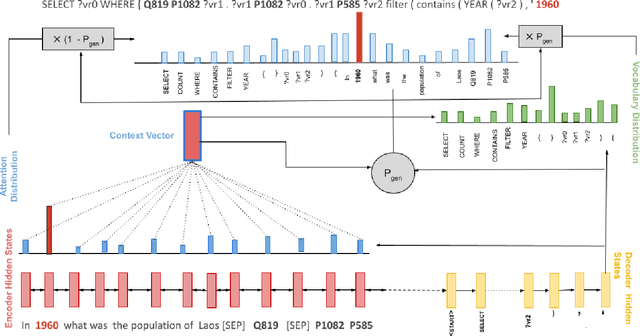
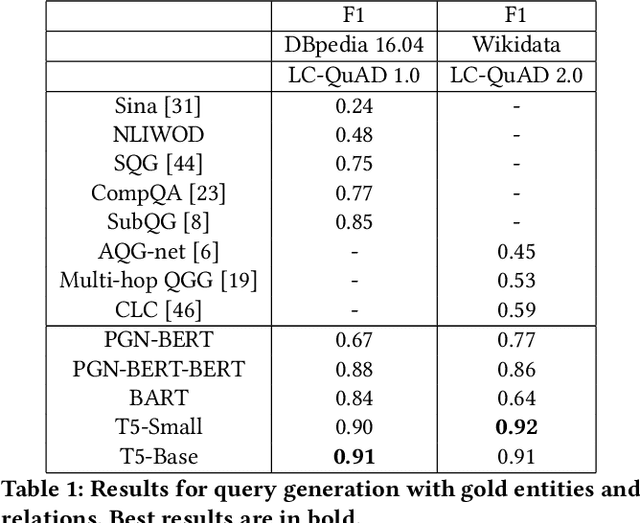
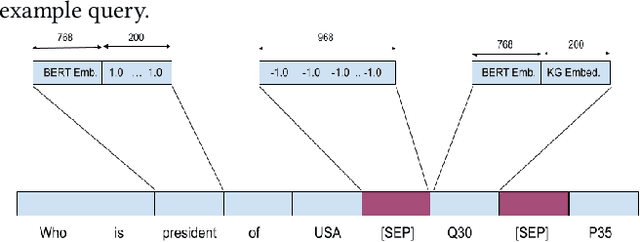
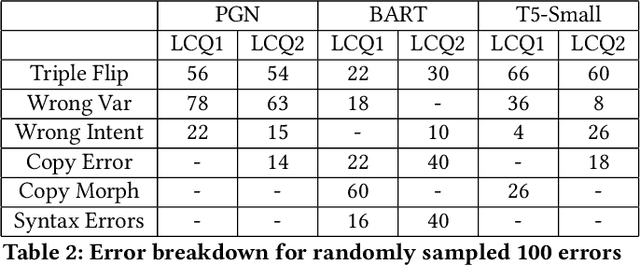
In this work, we focus on the task of generating SPARQL queries from natural language questions, which can then be executed on Knowledge Graphs (KGs). We assume that gold entity and relations have been provided, and the remaining task is to arrange them in the right order along with SPARQL vocabulary, and input tokens to produce the correct SPARQL query. Pre-trained Language Models (PLMs) have not been explored in depth on this task so far, so we experiment with BART, T5 and PGNs (Pointer Generator Networks) with BERT embeddings, looking for new baselines in the PLM era for this task, on DBpedia and Wikidata KGs. We show that T5 requires special input tokenisation, but produces state of the art performance on LC-QuAD 1.0 and LC-QuAD 2.0 datasets, and outperforms task-specific models from previous works. Moreover, the methods enable semantic parsing for questions where a part of the input needs to be copied to the output query, thus enabling a new paradigm in KG semantic parsing.