 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnytime Pretraining: Horizon-Free Learning-Rate Schedules with Weight Averaging
Feb 03, 2026Large language models are increasingly trained in continual or open-ended settings, where the total training horizon is not known in advance. Despite this, most existing pretraining recipes are not anytime: they rely on horizon-dependent learning rate schedules and extensive tuning under a fixed compute budget. In this work, we provide a theoretical analysis demonstrating the existence of anytime learning schedules for overparameterized linear regression, and we highlight the central role of weight averaging - also known as model merging - in achieving the minimax convergence rates of stochastic gradient descent. We show that these anytime schedules polynomially decay with time, with the decay rate determined by the source and capacity conditions of the problem. Empirically, we evaluate 150M and 300M parameter language models trained at 1-32x Chinchilla scale, comparing constant learning rates with weight averaging and $1/\sqrt{t}$ schedules with weight averaging against a well-tuned cosine schedule. Across the full training range, the anytime schedules achieve comparable final loss to cosine decay. Taken together, our results suggest that weight averaging combined with simple, horizon-free step sizes offers a practical and effective anytime alternative to cosine learning rate schedules for large language model pretraining.
CDQuant: Accurate Post-training Weight Quantization of Large Pre-trained Models using Greedy Coordinate Descent
Jun 26, 2024



Large language models (LLMs) have recently demonstrated remarkable performance across diverse language tasks. But their deployment is often constrained by their substantial computational and storage requirements. Quantization has emerged as a key technique for addressing this challenge, enabling the compression of large models with minimal impact on performance. The recent GPTQ algorithm, a post-training quantization (PTQ) method, has proven highly effective for compressing LLMs, sparking a wave of research that leverages GPTQ as a core component. Recognizing the pivotal role of GPTQ in the PTQ landscape, we introduce CDQuant, a simple and scalable alternative to GPTQ with improved performance. CDQuant uses coordinate descent to minimize the layer-wise reconstruction loss to achieve high-quality quantized weights. Our algorithm is easy to implement and scales efficiently to models with hundreds of billions of parameters. Through extensive evaluation on the PaLM2 model family, we demonstrate that CDQuant consistently outperforms GPTQ across diverse model sizes and quantization levels. In particular, for INT2 quantization of PaLM2-Otter, CDQuant achieves a 10% reduction in perplexity compared to GPTQ.
Tandem Transformers for Inference Efficient LLMs
Feb 13, 2024



The autoregressive nature of conventional large language models (LLMs) inherently limits inference speed, as tokens are generated sequentially. While speculative and parallel decoding techniques attempt to mitigate this, they face limitations: either relying on less accurate smaller models for generation or failing to fully leverage the base LLM's representations. We introduce a novel architecture, Tandem transformers, to address these issues. This architecture uniquely combines (1) a small autoregressive model and (2) a large model operating in block mode (processing multiple tokens simultaneously). The small model's predictive accuracy is substantially enhanced by granting it attention to the large model's richer representations. On the PaLM2 pretraining dataset, a tandem of PaLM2-Bison and PaLM2-Gecko demonstrates a 3.3% improvement in next-token prediction accuracy over a standalone PaLM2-Gecko, offering a 1.16x speedup compared to a PaLM2-Otter model with comparable downstream performance. We further incorporate the tandem model within the speculative decoding (SPEED) framework where the large model validates tokens from the small model. This ensures that the Tandem of PaLM2-Bison and PaLM2-Gecko achieves substantial speedup (around 1.14x faster than using vanilla PaLM2-Gecko in SPEED) while maintaining identical downstream task accuracy.
Domain Aligned Prefix Averaging for Domain Generalization in Abstractive Summarization
May 29, 2023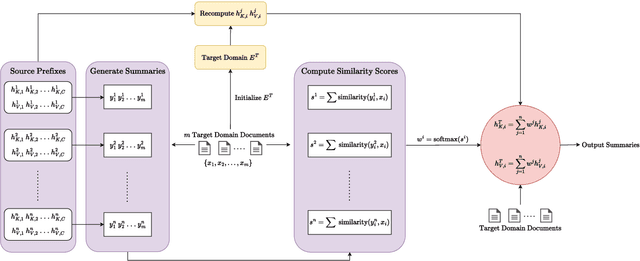
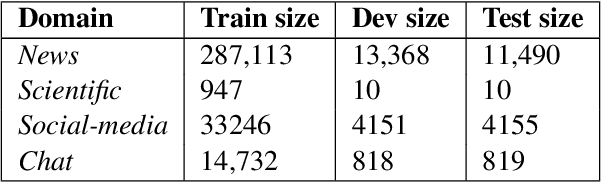

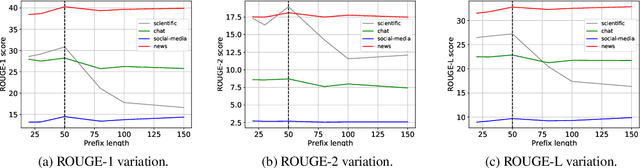
Domain generalization is hitherto an underexplored area applied in abstractive summarization. Moreover, most existing works on domain generalization have sophisticated training algorithms. In this paper, we propose a lightweight, weight averaging based, Domain Aligned Prefix Averaging approach to domain generalization for abstractive summarization. Given a number of source domains, our method first trains a prefix for each one of them. These source prefixes generate summaries for a small number of target domain documents. The similarity of the generated summaries to their corresponding documents is used for calculating weights required to average source prefixes. In DAPA, prefix tuning allows for lightweight finetuning, and weight averaging allows for the computationally efficient addition of new source domains. When evaluated on four diverse summarization domains, DAPA shows comparable or better performance against the baselines, demonstrating the effectiveness of its prefix averaging scheme.
The Role of Output Vocabulary in T2T LMs for SPARQL Semantic Parsing
May 24, 2023



In this work, we analyse the role of output vocabulary for text-to-text (T2T) models on the task of SPARQL semantic parsing. We perform experiments within the the context of knowledge graph question answering (KGQA), where the task is to convert questions in natural language to the SPARQL query language. We observe that the query vocabulary is distinct from human vocabulary. Language Models (LMs) are pre-dominantly trained for human language tasks, and hence, if the query vocabulary is replaced with a vocabulary more attuned to the LM tokenizer, the performance of models may improve. We carry out carefully selected vocabulary substitutions on the queries and find absolute gains in the range of 17% on the GrailQA dataset.
GETT-QA: Graph Embedding based T2T Transformer for Knowledge Graph Question Answering
Mar 28, 2023



In this work, we present an end-to-end Knowledge Graph Question Answering (KGQA) system named GETT-QA. GETT-QA uses T5, a popular text-to-text pre-trained language model. The model takes a question in natural language as input and produces a simpler form of the intended SPARQL query. In the simpler form, the model does not directly produce entity and relation IDs. Instead, it produces corresponding entity and relation labels. The labels are grounded to KG entity and relation IDs in a subsequent step. To further improve the results, we instruct the model to produce a truncated version of the KG embedding for each entity. The truncated KG embedding enables a finer search for disambiguation purposes. We find that T5 is able to learn the truncated KG embeddings without any change of loss function, improving KGQA performance. As a result, we report strong results for LC-QuAD 2.0 and SimpleQuestions-Wikidata datasets on end-to-end KGQA over Wikidata.
Modern Baselines for SPARQL Semantic Parsing
Apr 27, 2022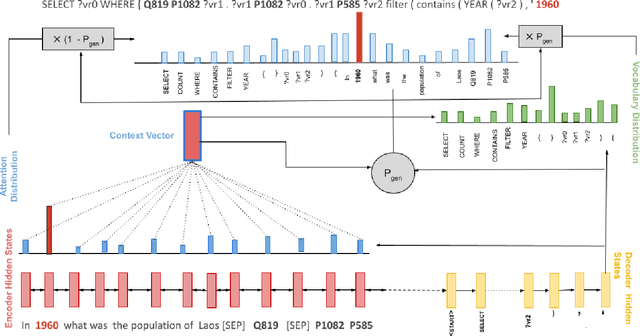
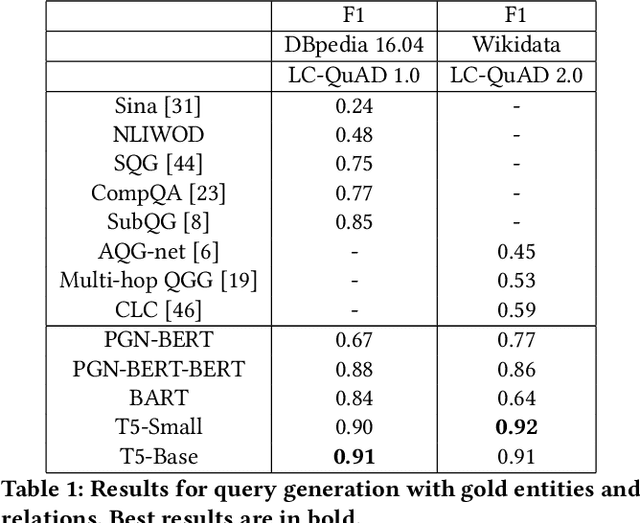
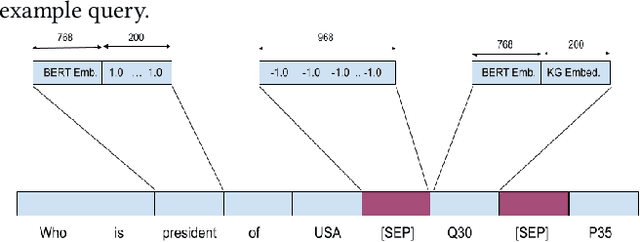
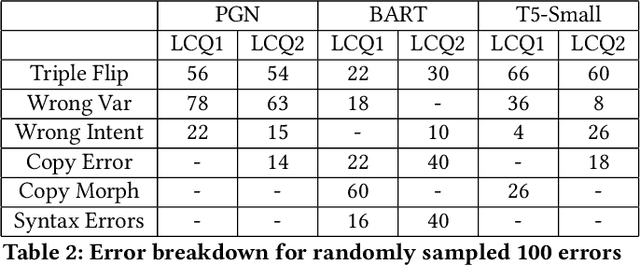
In this work, we focus on the task of generating SPARQL queries from natural language questions, which can then be executed on Knowledge Graphs (KGs). We assume that gold entity and relations have been provided, and the remaining task is to arrange them in the right order along with SPARQL vocabulary, and input tokens to produce the correct SPARQL query. Pre-trained Language Models (PLMs) have not been explored in depth on this task so far, so we experiment with BART, T5 and PGNs (Pointer Generator Networks) with BERT embeddings, looking for new baselines in the PLM era for this task, on DBpedia and Wikidata KGs. We show that T5 requires special input tokenisation, but produces state of the art performance on LC-QuAD 1.0 and LC-QuAD 2.0 datasets, and outperforms task-specific models from previous works. Moreover, the methods enable semantic parsing for questions where a part of the input needs to be copied to the output query, thus enabling a new paradigm in KG semantic parsing.