 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoMe: A Robust Metric for Evaluating Natural Language Generation
Mar 17, 2022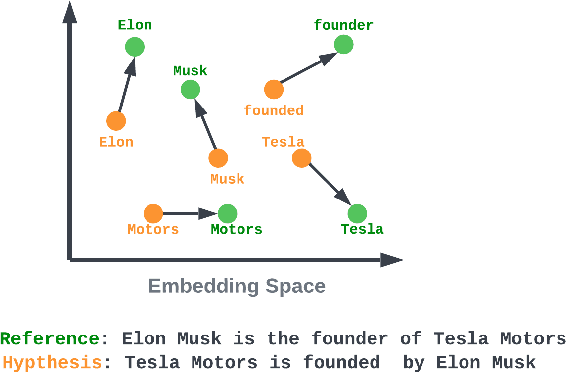
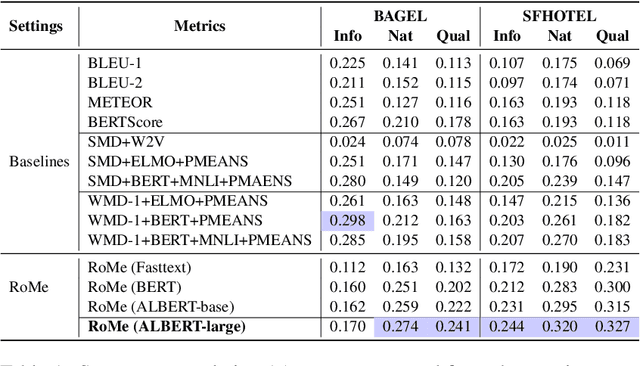
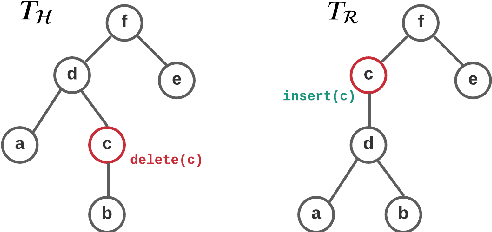

Evaluating Natural Language Generation (NLG) systems is a challenging task. Firstly, the metric should ensure that the generated hypothesis reflects the reference's semantics. Secondly, it should consider the grammatical quality of the generated sentence. Thirdly, it should be robust enough to handle various surface forms of the generated sentence. Thus, an effective evaluation metric has to be multifaceted. In this paper, we propose an automatic evaluation metric incorporating several core aspects of natural language understanding (language competence, syntactic and semantic variation). Our proposed metric, RoMe, is trained on language features such as semantic similarity combined with tree edit distance and grammatical acceptability, using a self-supervised neural network to assess the overall quality of the generated sentence. Moreover, we perform an extensive robustness analysis of the state-of-the-art methods and RoMe. Empirical results suggest that RoMe has a stronger correlation to human judgment over state-of-the-art metrics in evaluating system-generated sentences across several NLG tasks.
Grounding Dialogue Systems via Knowledge Graph Aware Decoding with Pre-trained Transformers
Mar 30, 2021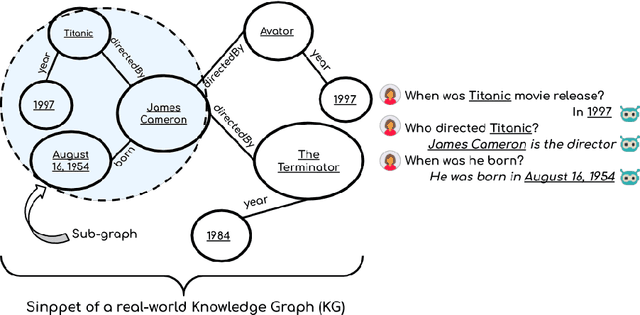
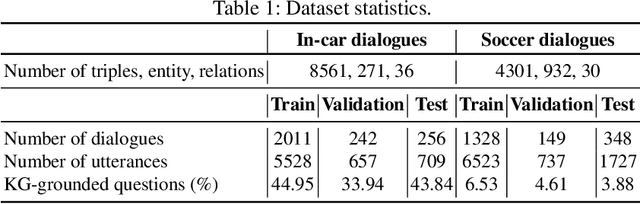
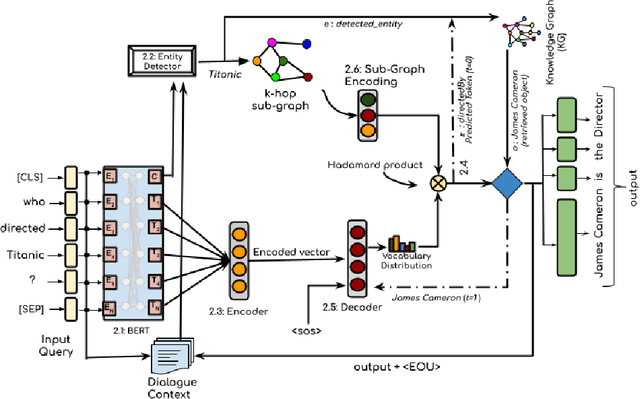
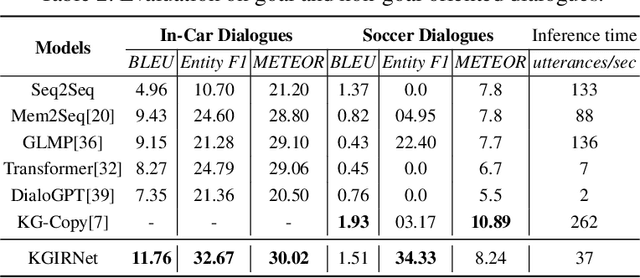
Generating knowledge grounded responses in both goal and non-goal oriented dialogue systems is an important research challenge. Knowledge Graphs (KG) can be viewed as an abstraction of the real world, which can potentially facilitate a dialogue system to produce knowledge grounded responses. However, integrating KGs into the dialogue generation process in an end-to-end manner is a non-trivial task. This paper proposes a novel architecture for integrating KGs into the response generation process by training a BERT model that learns to answer using the elements of the KG (entities and relations) in a multi-task, end-to-end setting. The k-hop subgraph of the KG is incorporated into the model during training and inference using Graph Laplacian. Empirical evaluation suggests that the model achieves better knowledge groundedness (measured via Entity F1 score) compared to other state-of-the-art models for both goal and non-goal oriented dialogues.
PNEL: Pointer Network based End-To-End Entity Linking over Knowledge Graphs
Aug 31, 2020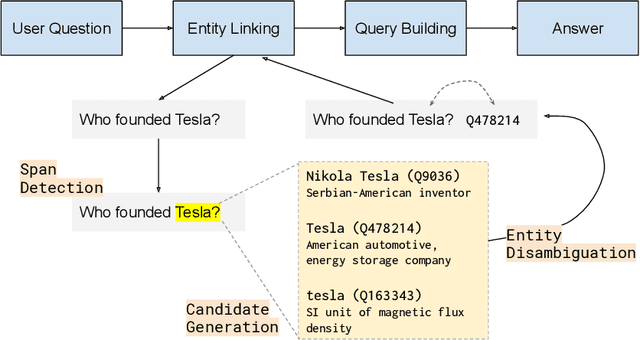


Question Answering systems are generally modelled as a pipeline consisting of a sequence of steps. In such a pipeline, Entity Linking (EL) is often the first step. Several EL models first perform span detection and then entity disambiguation. In such models errors from the span detection phase cascade to later steps and result in a drop of overall accuracy. Moreover, lack of gold entity spans in training data is a limiting factor for span detector training. Hence the movement towards end-to-end EL models began where no separate span detection step is involved. In this work we present a novel approach to end-to-end EL by applying the popular Pointer Network model, which achieves competitive performance. We demonstrate this in our evaluation over three datasets on the Wikidata Knowledge Graph.
End-to-End Entity Linking and Disambiguation leveraging Word and Knowledge Graph Embeddings
Feb 25, 2020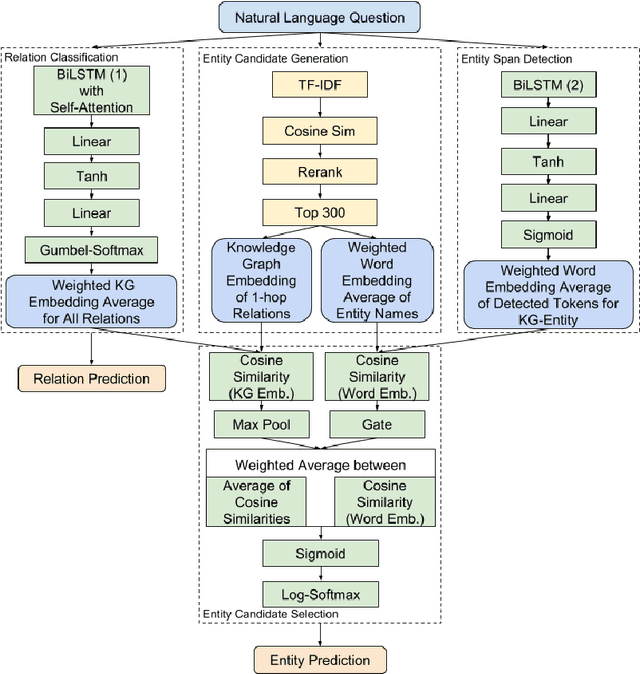
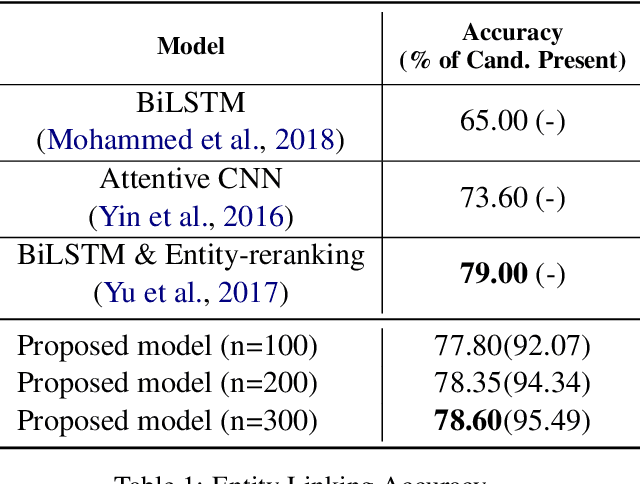
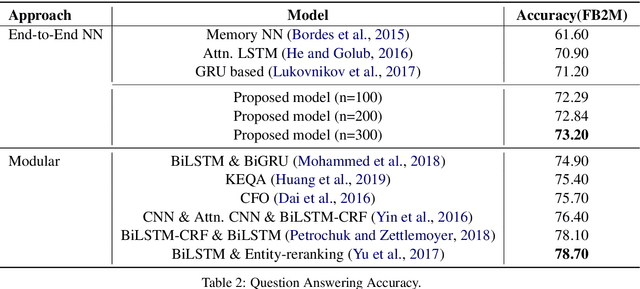

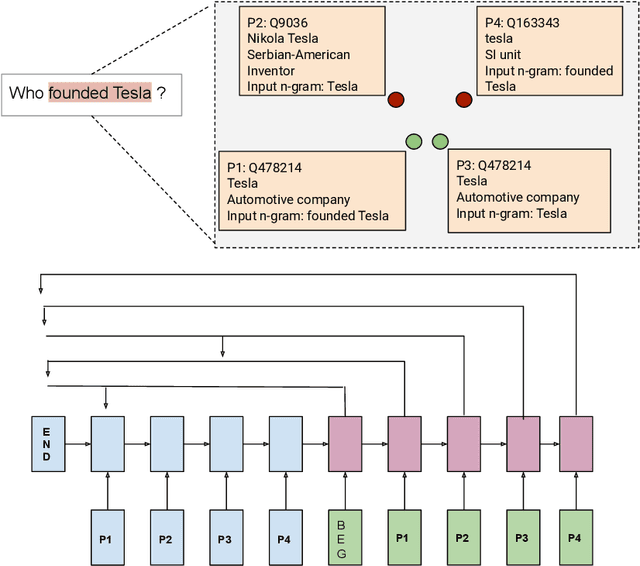
Entity linking - connecting entity mentions in a natural language utterance to knowledge graph (KG) entities is a crucial step for question answering over KGs. It is often based on measuring the string similarity between the entity label and its mention in the question. The relation referred to in the question can help to disambiguate between entities with the same label. This can be misleading if an incorrect relation has been identified in the relation linking step. However, an incorrect relation may still be semantically similar to the relation in which the correct entity forms a triple within the KG; which could be captured by the similarity of their KG embeddings. Based on this idea, we propose the first end-to-end neural network approach that employs KG as well as word embeddings to perform joint relation and entity classification of simple questions while implicitly performing entity disambiguation with the help of a novel gating mechanism. An empirical evaluation shows that the proposed approach achieves a performance comparable to state-of-the-art entity linking while requiring less post-processing.
Incorporating Joint Embeddings into Goal-Oriented Dialogues with Multi-Task Learning
Jan 28, 2020
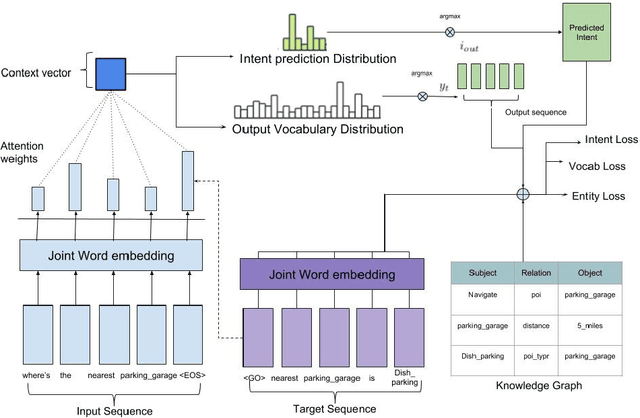
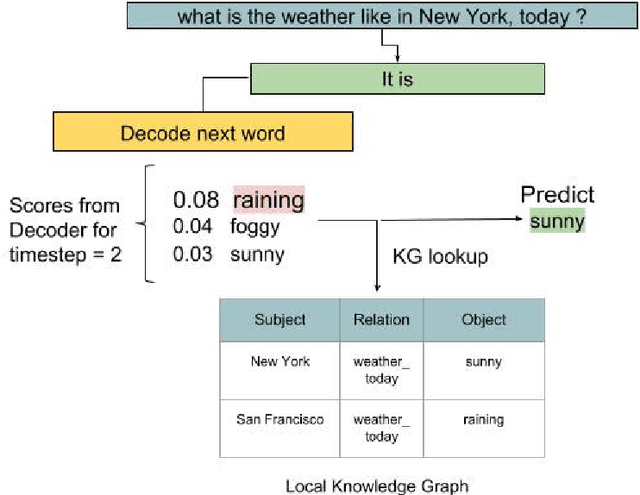

Attention-based encoder-decoder neural network models have recently shown promising results in goal-oriented dialogue systems. However, these models struggle to reason over and incorporate state-full knowledge while preserving their end-to-end text generation functionality. Since such models can greatly benefit from user intent and knowledge graph integration, in this paper we propose an RNN-based end-to-end encoder-decoder architecture which is trained with joint embeddings of the knowledge graph and the corpus as input. The model provides an additional integration of user intent along with text generation, trained with a multi-task learning paradigm along with an additional regularization technique to penalize generating the wrong entity as output. The model further incorporates a Knowledge Graph entity lookup during inference to guarantee the generated output is state-full based on the local knowledge graph provided. We finally evaluated the model using the BLEU score, empirical evaluation depicts that our proposed architecture can aid in the betterment of task-oriented dialogue system`s performance.
Using a KG-Copy Network for Non-Goal Oriented Dialogues
Oct 17, 2019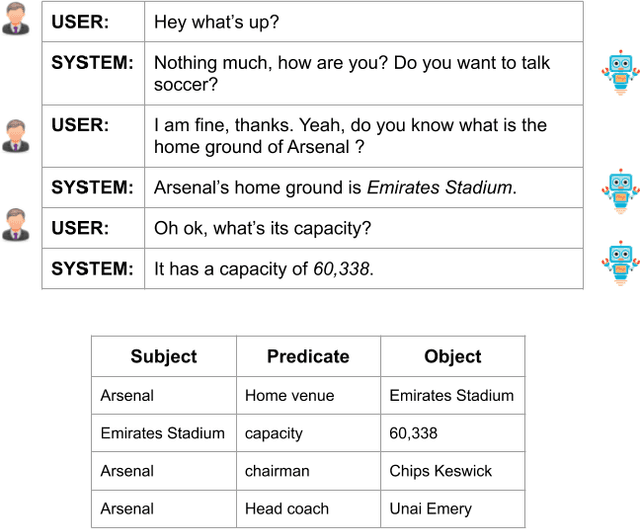
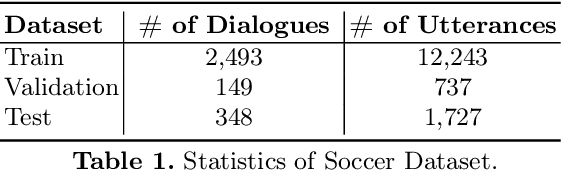
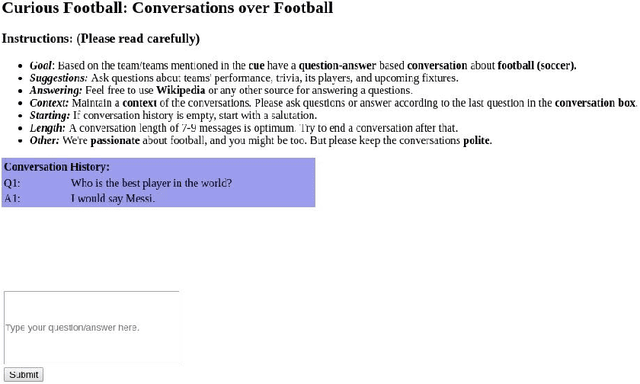
Non-goal oriented, generative dialogue systems lack the ability to generate answers with grounded facts. A knowledge graph can be considered an abstraction of the real world consisting of well-grounded facts. This paper addresses the problem of generating well grounded responses by integrating knowledge graphs into the dialogue systems response generation process, in an end-to-end manner. A dataset for nongoal oriented dialogues is proposed in this paper in the domain of soccer, conversing on different clubs and national teams along with a knowledge graph for each of these teams. A novel neural network architecture is also proposed as a baseline on this dataset, which can integrate knowledge graphs into the response generation process, producing well articulated, knowledge grounded responses. Empirical evidence suggests that the proposed model performs better than other state-of-the-art models for knowledge graph integrated dialogue systems.
Improving Response Selection in Multi-Turn Dialogue Systems by Incorporating Domain Knowledge
Nov 05, 2018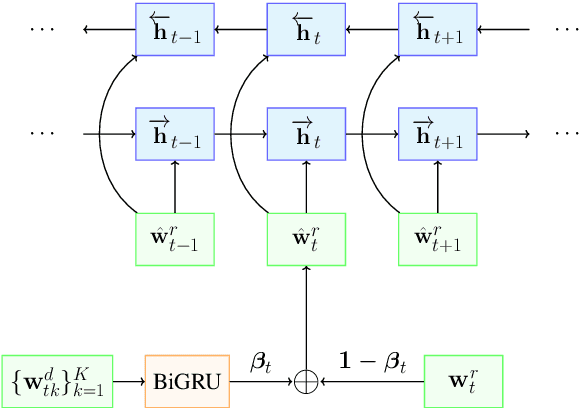



Building systems that can communicate with humans is a core problem in Artificial Intelligence. This work proposes a novel neural network architecture for response selection in an end-to-end multi-turn conversational dialogue setting. The architecture applies context level attention and incorporates additional external knowledge provided by descriptions of domain-specific words. It uses a bi-directional Gated Recurrent Unit (GRU) for encoding context and responses and learns to attend over the context words given the latent response representation and vice versa.In addition, it incorporates external domain specific information using another GRU for encoding the domain keyword descriptions. This allows better representation of domain-specific keywords in responses and hence improves the overall performance. Experimental results show that our model outperforms all other state-of-the-art methods for response selection in multi-turn conversations.
EARL: Joint Entity and Relation Linking for Question Answering over Knowledge Graphs
Jun 25, 2018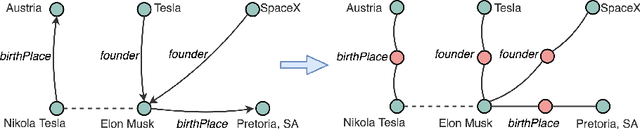
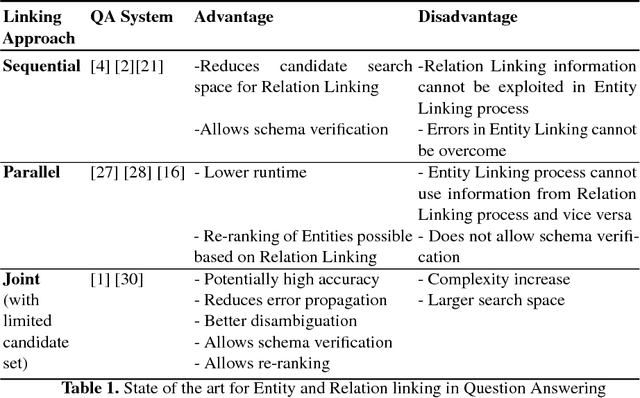
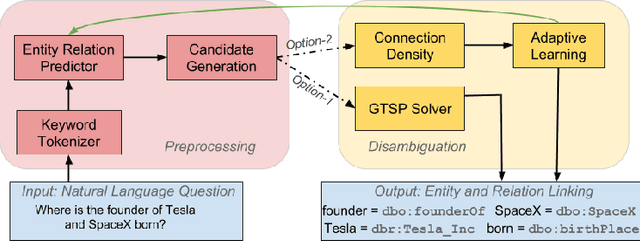
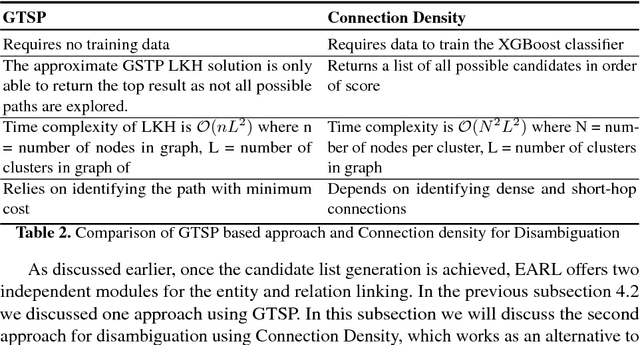
Many question answering systems over knowledge graphs rely on entity and relation linking components in order to connect the natural language input to the underlying knowledge graph. Traditionally, entity linking and relation linking have been performed either as dependent sequential tasks or as independent parallel tasks. In this paper, we propose a framework called EARL, which performs entity linking and relation linking as a joint task. EARL implements two different solution strategies for which we provide a comparative analysis in this paper: The first strategy is a formalisation of the joint entity and relation linking tasks as an instance of the Generalised Travelling Salesman Problem (GTSP). In order to be computationally feasible, we employ approximate GTSP solvers. The second strategy uses machine learning in order to exploit the connection density between nodes in the knowledge graph. It relies on three base features and re-ranking steps in order to predict entities and relations. We compare the strategies and evaluate them on a dataset with 5000 questions. Both strategies significantly outperform the current state-of-the-art approaches for entity and relation linking.
A Retrospective Analysis of the Fake News Challenge Stance Detection Task
Jun 13, 2018
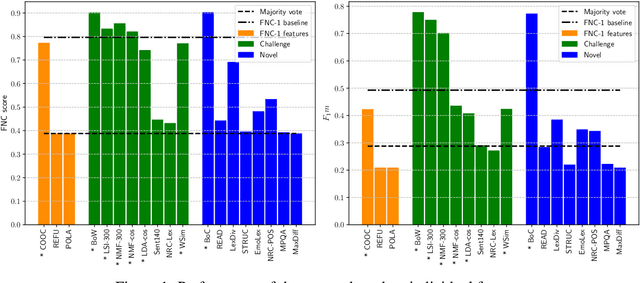

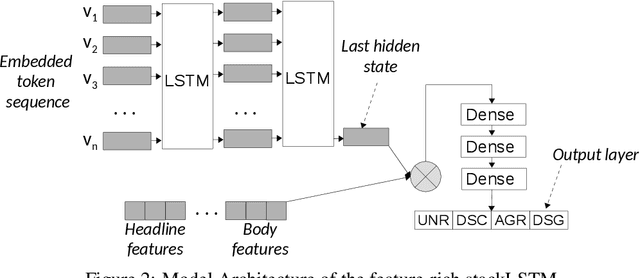
The 2017 Fake News Challenge Stage 1 (FNC-1) shared task addressed a stance classification task as a crucial first step towards detecting fake news. To date, there is no in-depth analysis paper to critically discuss FNC-1's experimental setup, reproduce the results, and draw conclusions for next-generation stance classification methods. In this paper, we provide such an in-depth analysis for the three top-performing systems. We first find that FNC-1's proposed evaluation metric favors the majority class, which can be easily classified, and thus overestimates the true discriminative power of the methods. Therefore, we propose a new F1-based metric yielding a changed system ranking. Next, we compare the features and architectures used, which leads to a novel feature-rich stacked LSTM model that performs on par with the best systems, but is superior in predicting minority classes. To understand the methods' ability to generalize, we derive a new dataset and perform both in-domain and cross-domain experiments. Our qualitative and quantitative study helps interpreting the original FNC-1 scores and understand which features help improving performance and why. Our new dataset and all source code used during the reproduction study are publicly available for future research.