 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoFire: Bayesian Optimization Framework Intended for Real Experiments
Aug 09, 2024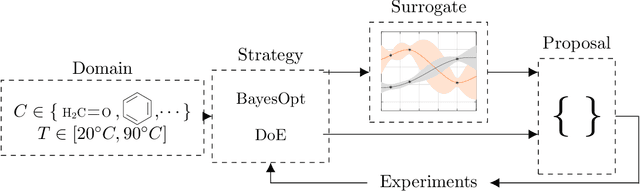
Our open-source Python package BoFire combines Bayesian Optimization (BO) with other design of experiments (DoE) strategies focusing on developing and optimizing new chemistry. Previous BO implementations, for example as they exist in the literature or software, require substantial adaptation for effective real-world deployment in chemical industry. BoFire provides a rich feature-set with extensive configurability and realizes our vision of fast-tracking research contributions into industrial use via maintainable open-source software. Owing to quality-of-life features like JSON-serializability of problem formulations, BoFire enables seamless integration of BO into RESTful APIs, a common architecture component for both self-driving laboratories and human-in-the-loop setups. This paper discusses the differences between BoFire and other BO implementations and outlines ways that BO research needs to be adapted for real-world use in a chemistry setting.
Crowdsourcing on Sensitive Data with Privacy-Preserving Text Rewriting
Mar 06, 2023



Most tasks in NLP require labeled data. Data labeling is often done on crowdsourcing platforms due to scalability reasons. However, publishing data on public platforms can only be done if no privacy-relevant information is included. Textual data often contains sensitive information like person names or locations. In this work, we investigate how removing personally identifiable information (PII) as well as applying differential privacy (DP) rewriting can enable text with privacy-relevant information to be used for crowdsourcing. We find that DP-rewriting before crowdsourcing can preserve privacy while still leading to good label quality for certain tasks and data. PII-removal led to good label quality in all examined tasks, however, there are no privacy guarantees given.
On the Effect of Sample and Topic Sizes for Argument Mining Datasets
May 23, 2022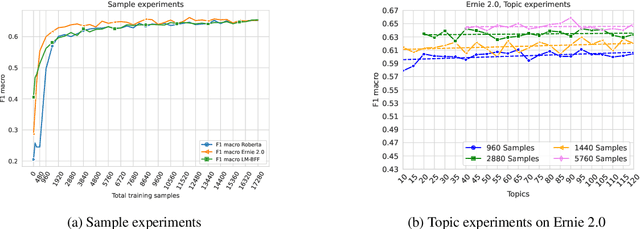
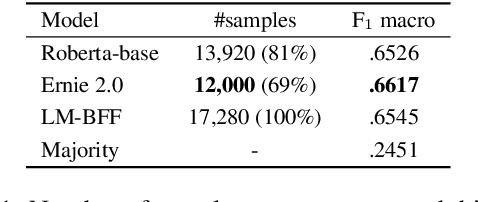
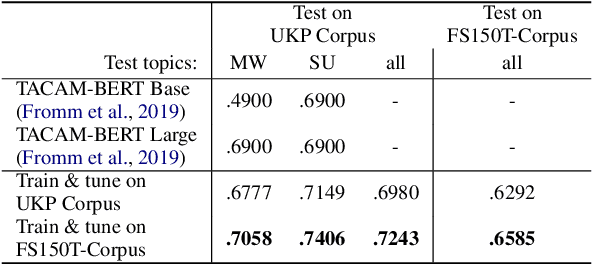
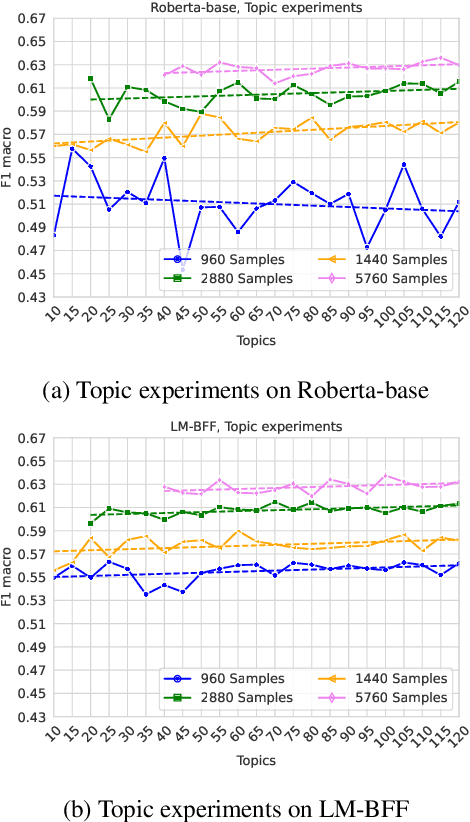
The task of Argument Mining, that is extracting argumentative sentences for a specific topic from large document sources, is an inherently difficult task for machine learning models and humans alike, as large datasets are rare and recognition of argumentative sentences requires expert knowledge. The task becomes even more difficult when it also involves stance detection of retrieved arguments. Recent datasets for the task tend to grow evermore large and hence more costly. In this work, we inquire whether it is necessary for acceptable performance of argument mining to have datasets growing in size or, if not, how smaller datasets have to be composed for optimal performance. We also publish a newly created dataset for future benchmarking.
Focusing Knowledge-based Graph Argument Mining via Topic Modeling
Feb 03, 2021
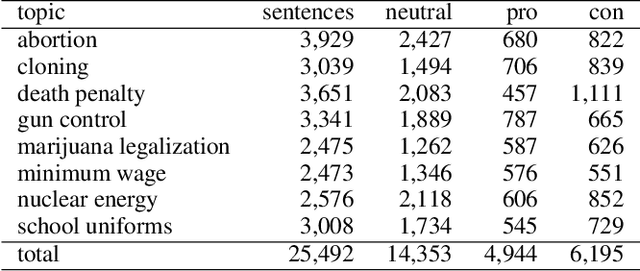
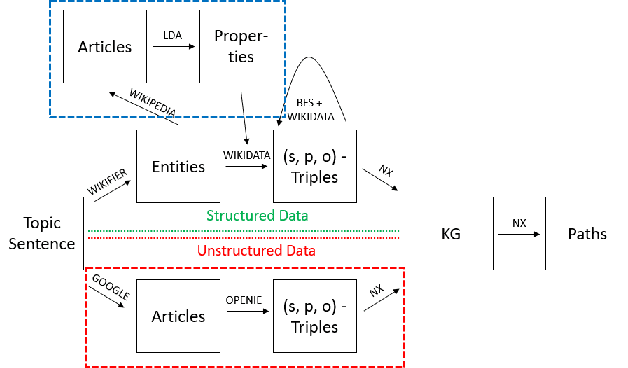

Decision-making usually takes five steps: identifying the problem, collecting data, extracting evidence, identifying pro and con arguments, and making decisions. Focusing on extracting evidence, this paper presents a hybrid model that combines latent Dirichlet allocation and word embeddings to obtain external knowledge from structured and unstructured data. We study the task of sentence-level argument mining, as arguments mostly require some degree of world knowledge to be identified and understood. Given a topic and a sentence, the goal is to classify whether a sentence represents an argument in regard to the topic. We use a topic model to extract topic- and sentence-specific evidence from the structured knowledge base Wikidata, building a graph based on the cosine similarity between the entity word vectors of Wikidata and the vector of the given sentence. Also, we build a second graph based on topic-specific articles found via Google to tackle the general incompleteness of structured knowledge bases. Combining these graphs, we obtain a graph-based model which, as our evaluation shows, successfully capitalizes on both structured and unstructured data.
Aspect-Controlled Neural Argument Generation
Apr 30, 2020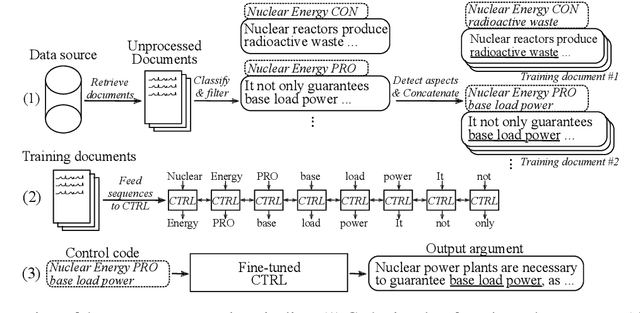
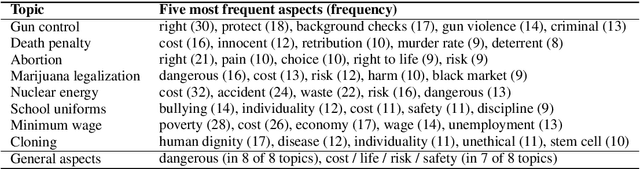

We rely on arguments in our daily lives to deliver our opinions and base them on evidence, making them more convincing in turn. However, finding and formulating arguments can be challenging. In this work, we train a language model for argument generation that can be controlled on a fine-grained level to generate sentence-level arguments for a given topic, stance, and aspect. We define argument aspect detection as a necessary method to allow this fine-granular control and crowdsource a dataset with 5,032 arguments annotated with aspects. Our evaluation shows that our generation model is able to generate high-quality, aspect-specific arguments. Moreover, these arguments can be used to improve the performance of stance detection models via data augmentation and to generate counter-arguments. We publish all datasets and code to fine-tune the language model.
Stance Detection Benchmark: How Robust Is Your Stance Detection?
Jan 06, 2020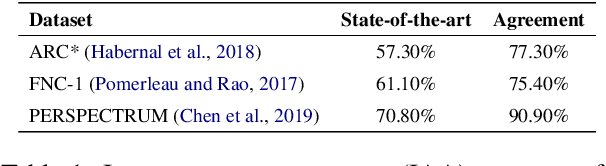
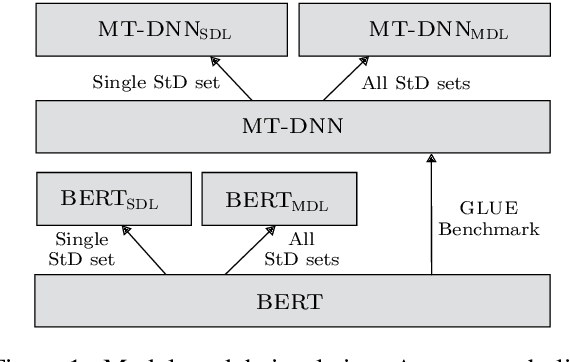
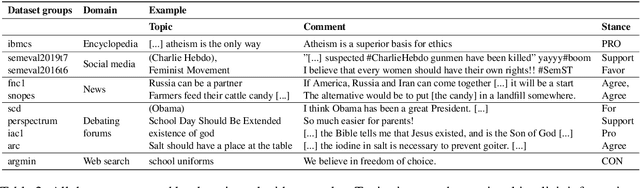
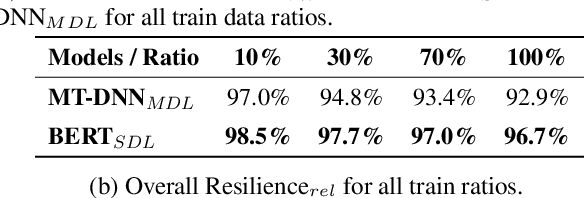
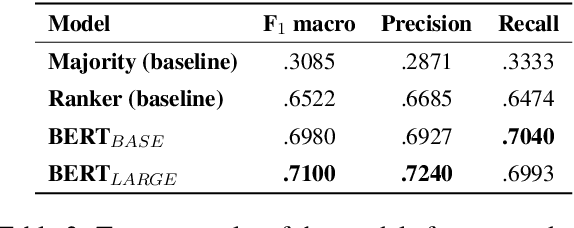
Stance Detection (StD) aims to detect an author's stance towards a certain topic or claim and has become a key component in applications like fake news detection, claim validation, and argument search. However, while stance is easily detected by humans, machine learning models are clearly falling short of this task. Given the major differences in dataset sizes and framing of StD (e.g. number of classes and inputs), we introduce a StD benchmark that learns from ten StD datasets of various domains in a multi-dataset learning (MDL) setting, as well as from related tasks via transfer learning. Within this benchmark setup, we are able to present new state-of-the-art results on five of the datasets. Yet, the models still perform well below human capabilities and even simple adversarial attacks severely hurt the performance of MDL models. Deeper investigation into this phenomenon suggests the existence of biases inherited from multiple datasets by design. Our analysis emphasizes the need of focus on robustness and de-biasing strategies in multi-task learning approaches. The benchmark dataset and code is made available.
Classification and Clustering of Arguments with Contextualized Word Embeddings
Jun 24, 2019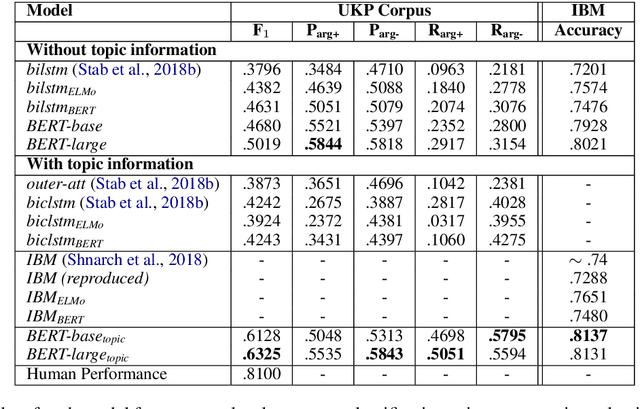
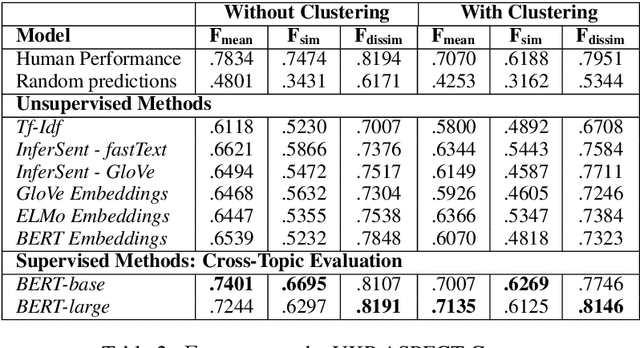
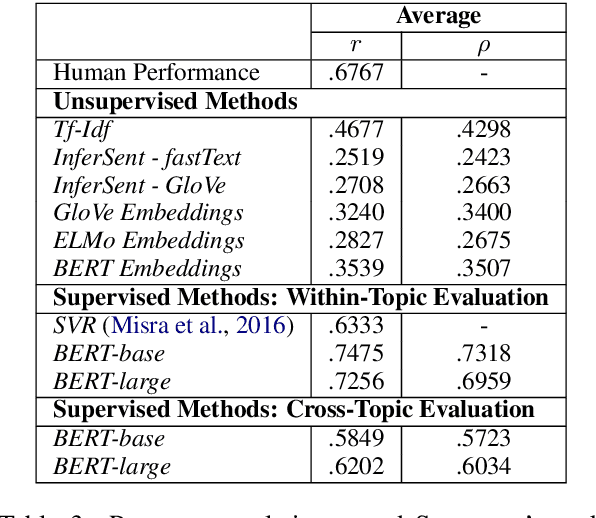
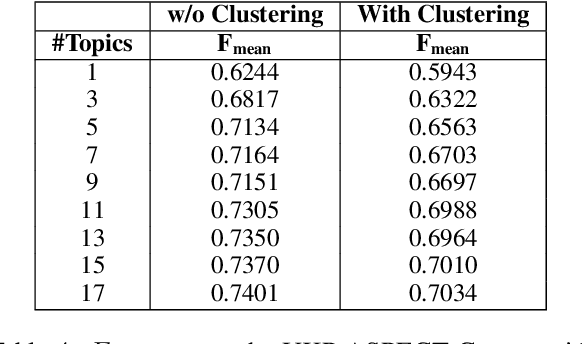
We experiment with two recent contextualized word embedding methods (ELMo and BERT) in the context of open-domain argument search. For the first time, we show how to leverage the power of contextualized word embeddings to classify and cluster topic-dependent arguments, achieving impressive results on both tasks and across multiple datasets. For argument classification, we improve the state-of-the-art for the UKP Sentential Argument Mining Corpus by 20.8 percentage points and for the IBM Debater - Evidence Sentences dataset by 7.4 percentage points. For the understudied task of argument clustering, we propose a pre-training step which improves by 7.8 percentage points over strong baselines on a novel dataset, and by 12.3 percentage points for the Argument Facet Similarity (AFS) Corpus.
UKP-Athene: Multi-Sentence Textual Entailment for Claim Verification
Sep 10, 2018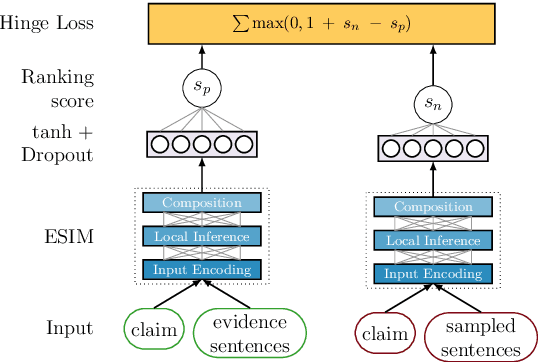

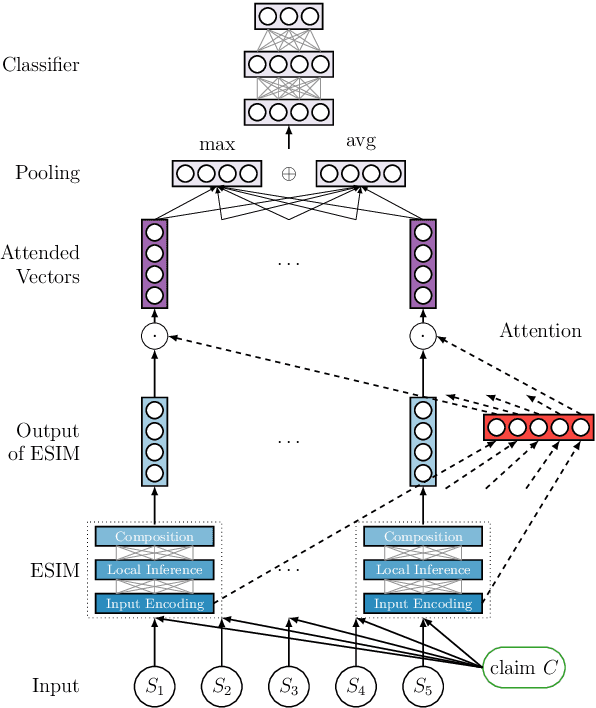
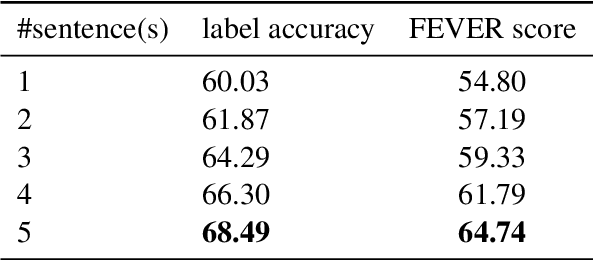
The Fact Extraction and VERification (FEVER) shared task was launched to support the development of systems able to verify claims by extracting supporting or refuting facts from raw text. The shared task organizers provide a large-scale dataset for the consecutive steps involved in claim verification, in particular, document retrieval, fact extraction, and claim classification. In this paper, we present our claim verification pipeline approach, which, according to the preliminary results, scored third in the shared task, out of 23 competing systems. For the document retrieval, we implemented a new entity linking approach. In order to be able to rank candidate facts and classify a claim on the basis of several selected facts, we introduce two extensions to the Enhanced LSTM (ESIM).
A Retrospective Analysis of the Fake News Challenge Stance Detection Task
Jun 13, 2018
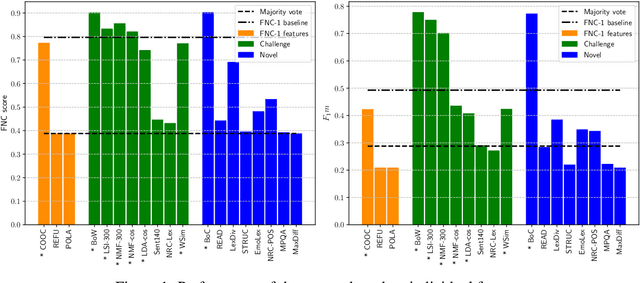

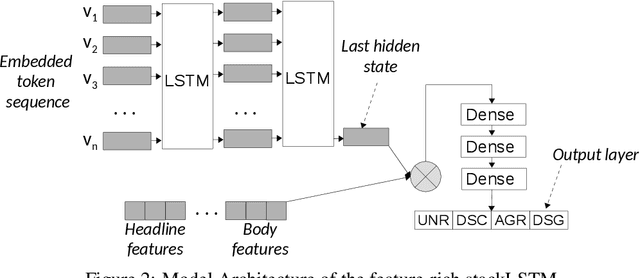
The 2017 Fake News Challenge Stage 1 (FNC-1) shared task addressed a stance classification task as a crucial first step towards detecting fake news. To date, there is no in-depth analysis paper to critically discuss FNC-1's experimental setup, reproduce the results, and draw conclusions for next-generation stance classification methods. In this paper, we provide such an in-depth analysis for the three top-performing systems. We first find that FNC-1's proposed evaluation metric favors the majority class, which can be easily classified, and thus overestimates the true discriminative power of the methods. Therefore, we propose a new F1-based metric yielding a changed system ranking. Next, we compare the features and architectures used, which leads to a novel feature-rich stacked LSTM model that performs on par with the best systems, but is superior in predicting minority classes. To understand the methods' ability to generalize, we derive a new dataset and perform both in-domain and cross-domain experiments. Our qualitative and quantitative study helps interpreting the original FNC-1 scores and understand which features help improving performance and why. Our new dataset and all source code used during the reproduction study are publicly available for future research.