 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
UKP-Athene: Multi-Sentence Textual Entailment for Claim Verification
Sep 10, 2018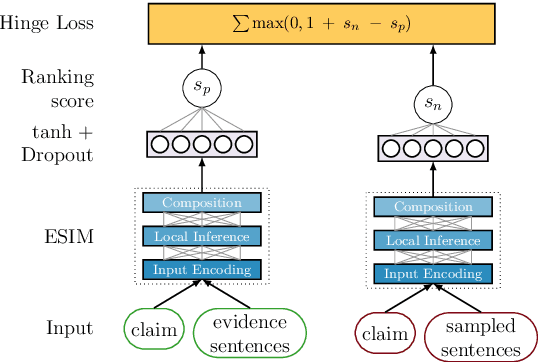

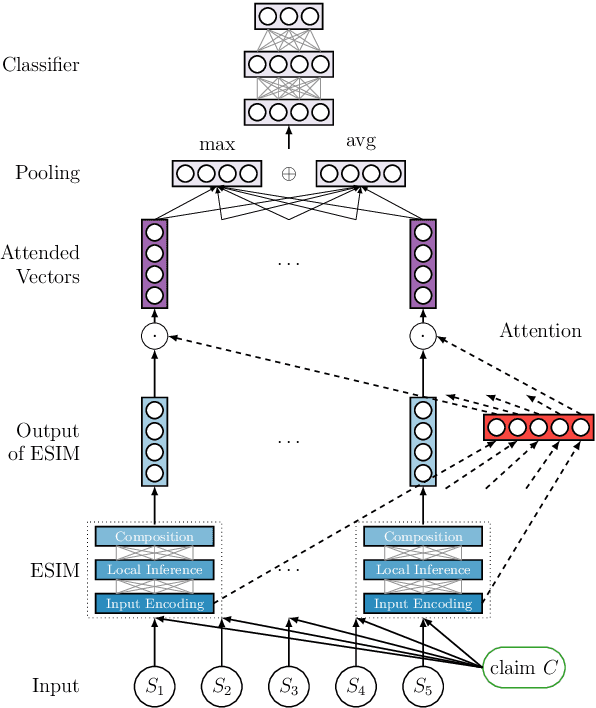
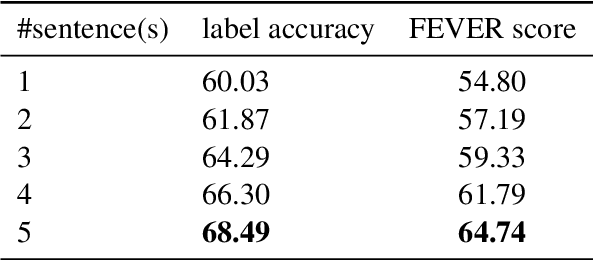
The Fact Extraction and VERification (FEVER) shared task was launched to support the development of systems able to verify claims by extracting supporting or refuting facts from raw text. The shared task organizers provide a large-scale dataset for the consecutive steps involved in claim verification, in particular, document retrieval, fact extraction, and claim classification. In this paper, we present our claim verification pipeline approach, which, according to the preliminary results, scored third in the shared task, out of 23 competing systems. For the document retrieval, we implemented a new entity linking approach. In order to be able to rank candidate facts and classify a claim on the basis of several selected facts, we introduce two extensions to the Enhanced LSTM (ESIM).
Modeling Semantics with Gated Graph Neural Networks for Knowledge Base Question Answering
Aug 13, 2018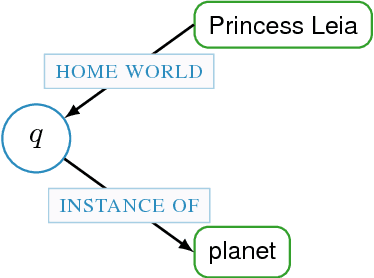
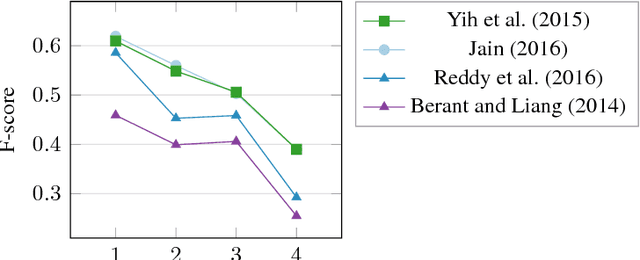
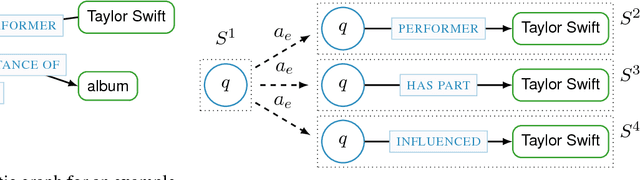
The most approaches to Knowledge Base Question Answering are based on semantic parsing. In this paper, we address the problem of learning vector representations for complex semantic parses that consist of multiple entities and relations. Previous work largely focused on selecting the correct semantic relations for a question and disregarded the structure of the semantic parse: the connections between entities and the directions of the relations. We propose to use Gated Graph Neural Networks to encode the graph structure of the semantic parse. We show on two data sets that the graph networks outperform all baseline models that do not explicitly model the structure. The error analysis confirms that our approach can successfully process complex semantic parses.
Mixing Context Granularities for Improved Entity Linking on Question Answering Data across Entity Categories
Apr 23, 2018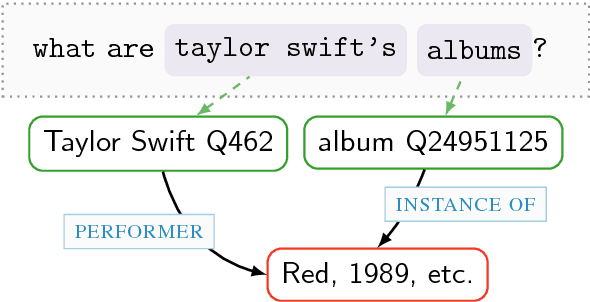
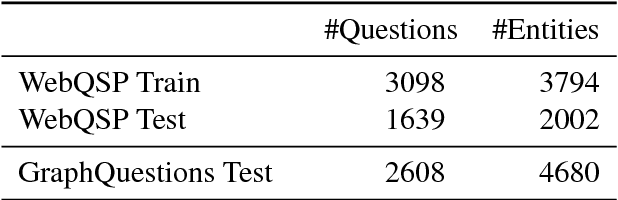
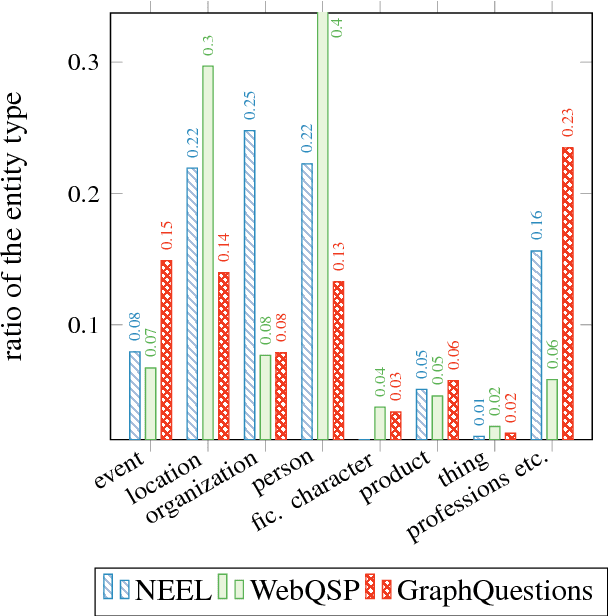
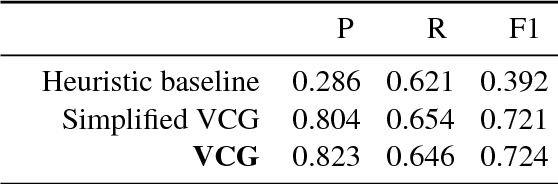
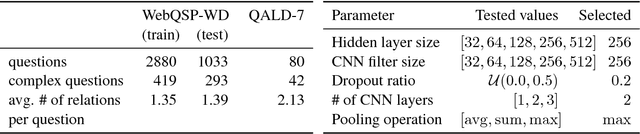
The first stage of every knowledge base question answering approach is to link entities in the input question. We investigate entity linking in the context of a question answering task and present a jointly optimized neural architecture for entity mention detection and entity disambiguation that models the surrounding context on different levels of granularity. We use the Wikidata knowledge base and available question answering datasets to create benchmarks for entity linking on question answering data. Our approach outperforms the previous state-of-the-art system on this data, resulting in an average 8% improvement of the final score. We further demonstrate that our model delivers a strong performance across different entity categories.