 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Structures in the Semantic Vector Space: A Framework for Decomposing Word Embeddings
Dec 17, 2019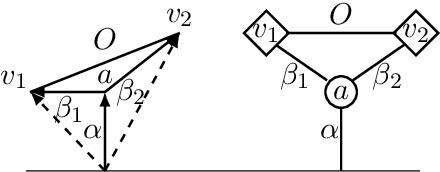
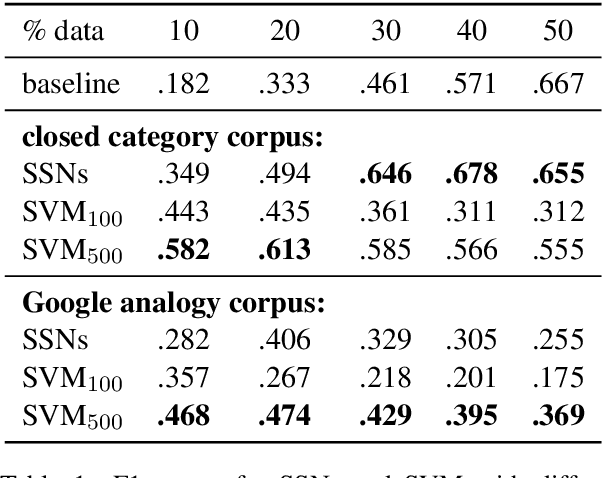
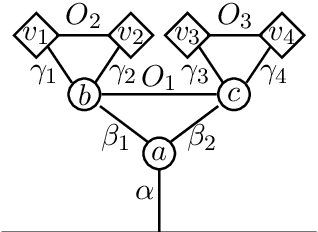
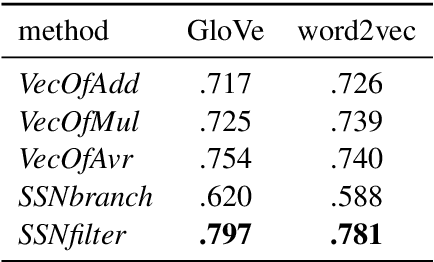
Word embeddings are rich word representations, which in combination with deep neural networks, lead to large performance gains for many NLP tasks. However, word embeddings are represented by dense, real-valued vectors and they are therefore not directly interpretable. Thus, computational operations based on them are also not well understood. In this paper, we present an approach for analyzing structures in the semantic vector space to get a better understanding of the underlying semantic encoding principles. We present a framework for decomposing word embeddings into smaller meaningful units which we call sub-vectors. The framework opens up a wide range of possibilities analyzing phenomena in vector space semantics, as well as solving concrete NLP problems: We introduce the category completion task and show that a sub-vector based approach is superior to supervised techniques; We present a sub-vector based method for solving the word analogy task, which substantially outperforms different variants of the traditional vector-offset method.
A Richly Annotated Corpus for Different Tasks in Automated Fact-Checking
Oct 29, 2019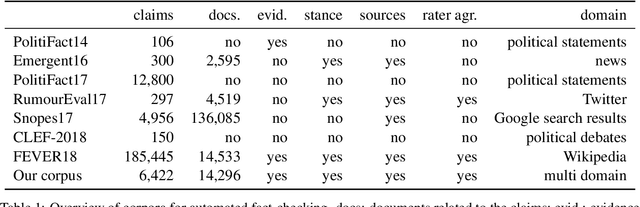
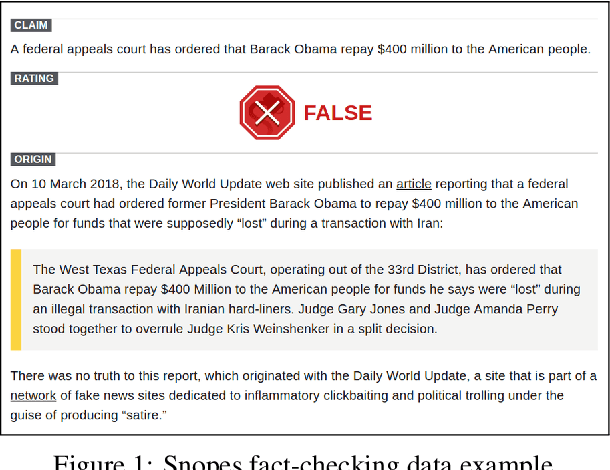
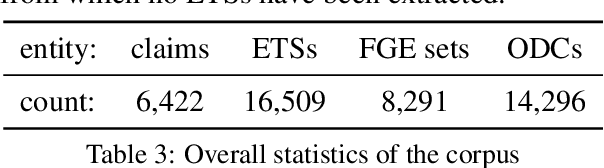
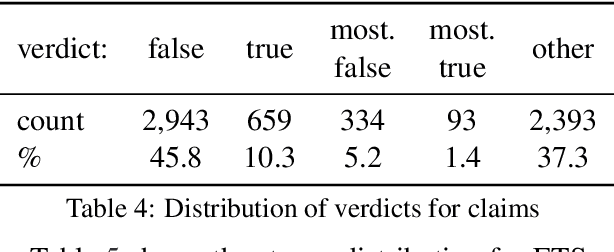
Automated fact-checking based on machine learning is a promising approach to identify false information distributed on the web. In order to achieve satisfactory performance, machine learning methods require a large corpus with reliable annotations for the different tasks in the fact-checking process. Having analyzed existing fact-checking corpora, we found that none of them meets these criteria in full. They are either too small in size, do not provide detailed annotations, or are limited to a single domain. Motivated by this gap, we present a new substantially sized mixed-domain corpus with annotations of good quality for the core fact-checking tasks: document retrieval, evidence extraction, stance detection, and claim validation. To aid future corpus construction, we describe our methodology for corpus creation and annotation, and demonstrate that it results in substantial inter-annotator agreement. As baselines for future research, we perform experiments on our corpus with a number of model architectures that reach high performance in similar problem settings. Finally, to support the development of future models, we provide a detailed error analysis for each of the tasks. Our results show that the realistic, multi-domain setting defined by our data poses new challenges for the existing models, providing opportunities for considerable improvement by future systems.
UKP-Athene: Multi-Sentence Textual Entailment for Claim Verification
Sep 10, 2018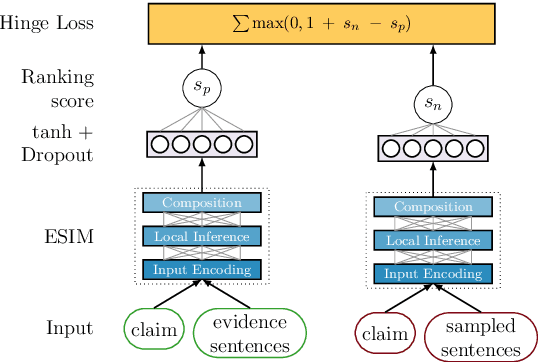

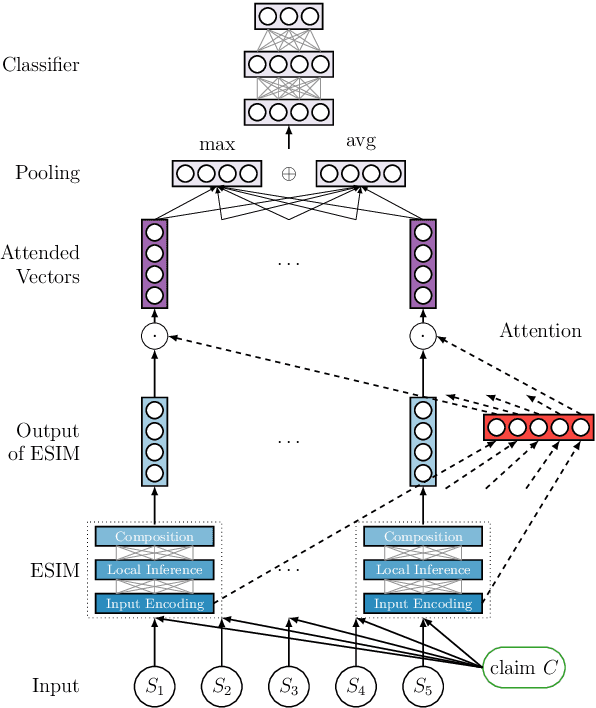
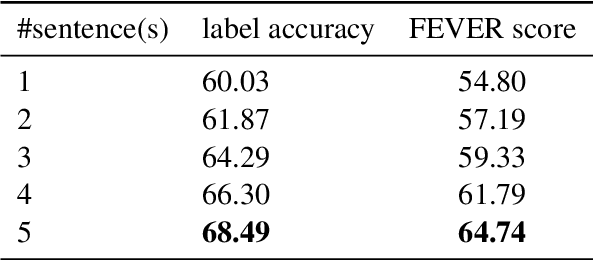
The Fact Extraction and VERification (FEVER) shared task was launched to support the development of systems able to verify claims by extracting supporting or refuting facts from raw text. The shared task organizers provide a large-scale dataset for the consecutive steps involved in claim verification, in particular, document retrieval, fact extraction, and claim classification. In this paper, we present our claim verification pipeline approach, which, according to the preliminary results, scored third in the shared task, out of 23 competing systems. For the document retrieval, we implemented a new entity linking approach. In order to be able to rank candidate facts and classify a claim on the basis of several selected facts, we introduce two extensions to the Enhanced LSTM (ESIM).
A Retrospective Analysis of the Fake News Challenge Stance Detection Task
Jun 13, 2018
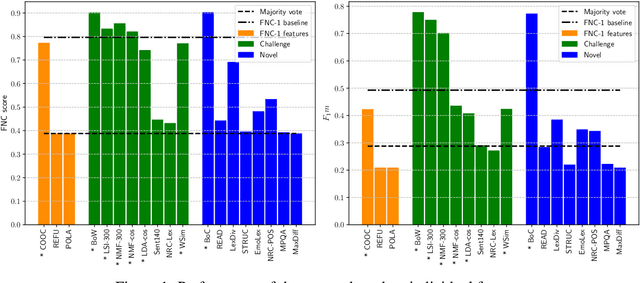

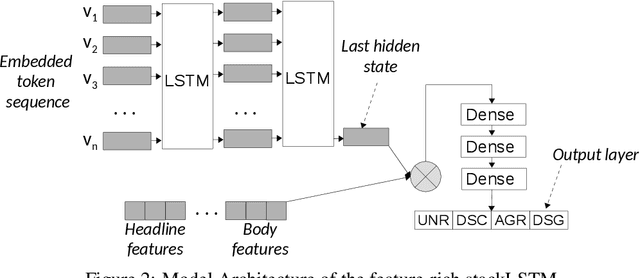
The 2017 Fake News Challenge Stage 1 (FNC-1) shared task addressed a stance classification task as a crucial first step towards detecting fake news. To date, there is no in-depth analysis paper to critically discuss FNC-1's experimental setup, reproduce the results, and draw conclusions for next-generation stance classification methods. In this paper, we provide such an in-depth analysis for the three top-performing systems. We first find that FNC-1's proposed evaluation metric favors the majority class, which can be easily classified, and thus overestimates the true discriminative power of the methods. Therefore, we propose a new F1-based metric yielding a changed system ranking. Next, we compare the features and architectures used, which leads to a novel feature-rich stacked LSTM model that performs on par with the best systems, but is superior in predicting minority classes. To understand the methods' ability to generalize, we derive a new dataset and perform both in-domain and cross-domain experiments. Our qualitative and quantitative study helps interpreting the original FNC-1 scores and understand which features help improving performance and why. Our new dataset and all source code used during the reproduction study are publicly available for future research.