 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Retrospective Analysis of the Fake News Challenge Stance Detection Task
Jun 13, 2018
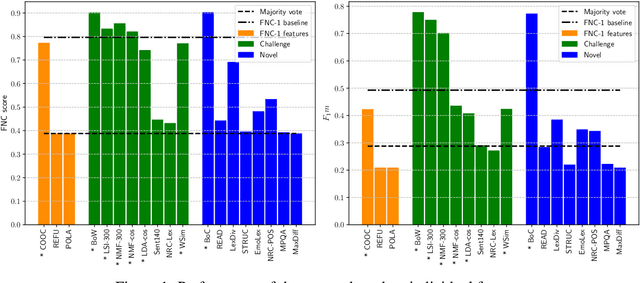

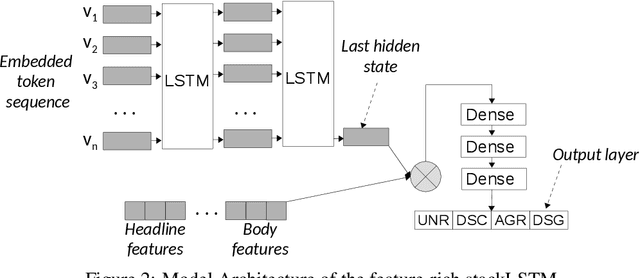
The 2017 Fake News Challenge Stage 1 (FNC-1) shared task addressed a stance classification task as a crucial first step towards detecting fake news. To date, there is no in-depth analysis paper to critically discuss FNC-1's experimental setup, reproduce the results, and draw conclusions for next-generation stance classification methods. In this paper, we provide such an in-depth analysis for the three top-performing systems. We first find that FNC-1's proposed evaluation metric favors the majority class, which can be easily classified, and thus overestimates the true discriminative power of the methods. Therefore, we propose a new F1-based metric yielding a changed system ranking. Next, we compare the features and architectures used, which leads to a novel feature-rich stacked LSTM model that performs on par with the best systems, but is superior in predicting minority classes. To understand the methods' ability to generalize, we derive a new dataset and perform both in-domain and cross-domain experiments. Our qualitative and quantitative study helps interpreting the original FNC-1 scores and understand which features help improving performance and why. Our new dataset and all source code used during the reproduction study are publicly available for future research.
Does Syntactic Knowledge help English-Hindi SMT?
Jan 20, 2014


In this paper we explore various parameter settings of the state-of-art Statistical Machine Translation system to improve the quality of the translation for a `distant' language pair like English-Hindi. We proposed new techniques for efficient reordering. A slight improvement over the baseline is reported using these techniques. We also show that a simple pre-processing step can improve the quality of the translation significantly.