 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDravidian language family through Universal Dependencies lens
Jun 20, 2024



The Universal Dependencies (UD) project aims to create a cross-linguistically consistent dependency annotation for multiple languages, to facilitate multilingual NLP. It currently supports 114 languages. Dravidian languages are spoken by over 200 million people across the word, and yet there are only two languages from this family in UD. This paper examines some of the morphological and syntactic features of Dravidian languages and explores how they can be annotated in the UD framework.
Are Sounds Sound for Phylogenetic Reconstruction?
Feb 05, 2024



In traditional studies on language evolution, scholars often emphasize the importance of sound laws and sound correspondences for phylogenetic inference of language family trees. However, to date, computational approaches have typically not taken this potential into account. Most computational studies still rely on lexical cognates as major data source for phylogenetic reconstruction in linguistics, although there do exist a few studies in which authors praise the benefits of comparing words at the level of sound sequences. Building on (a) ten diverse datasets from different language families, and (b) state-of-the-art methods for automated cognate and sound correspondence detection, we test, for the first time, the performance of sound-based versus cognate-based approaches to phylogenetic reconstruction. Our results show that phylogenies reconstructed from lexical cognates are topologically closer, by approximately one third with respect to the generalized quartet distance on average, to the gold standard phylogenies than phylogenies reconstructed from sound correspondences.
What do complexity measures measure? Correlating and validating corpus-based measures of morphological complexity
Apr 11, 2022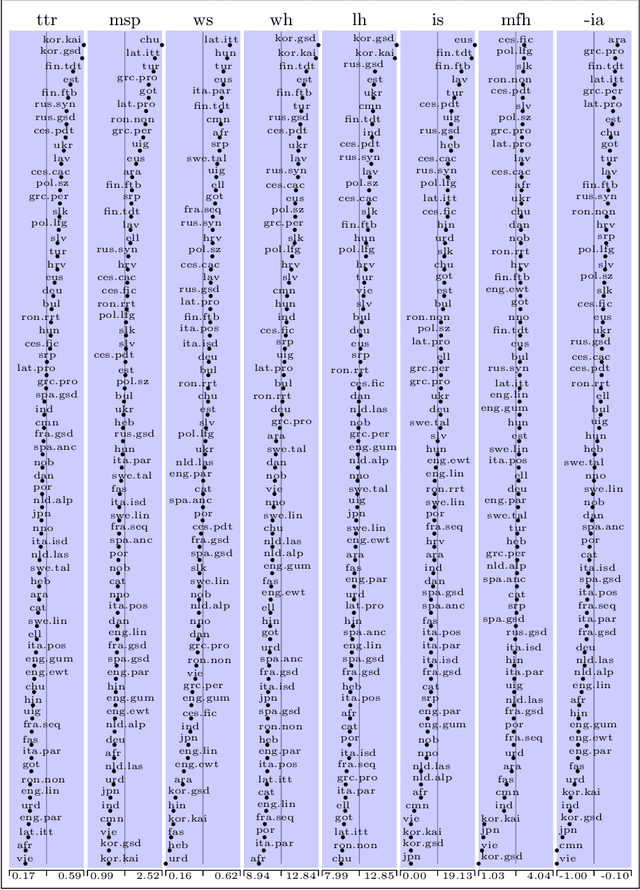
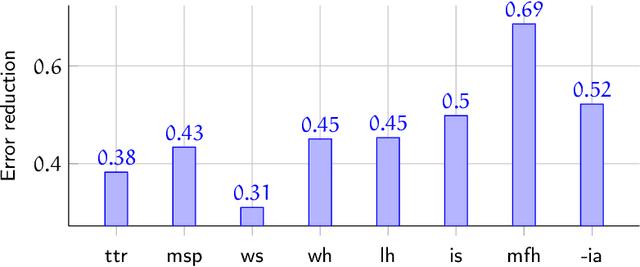
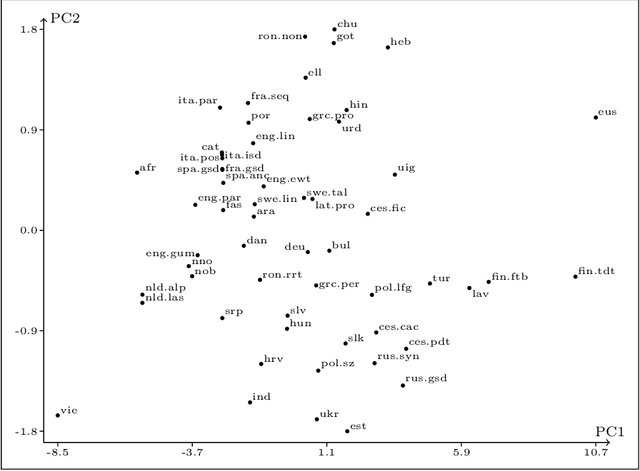
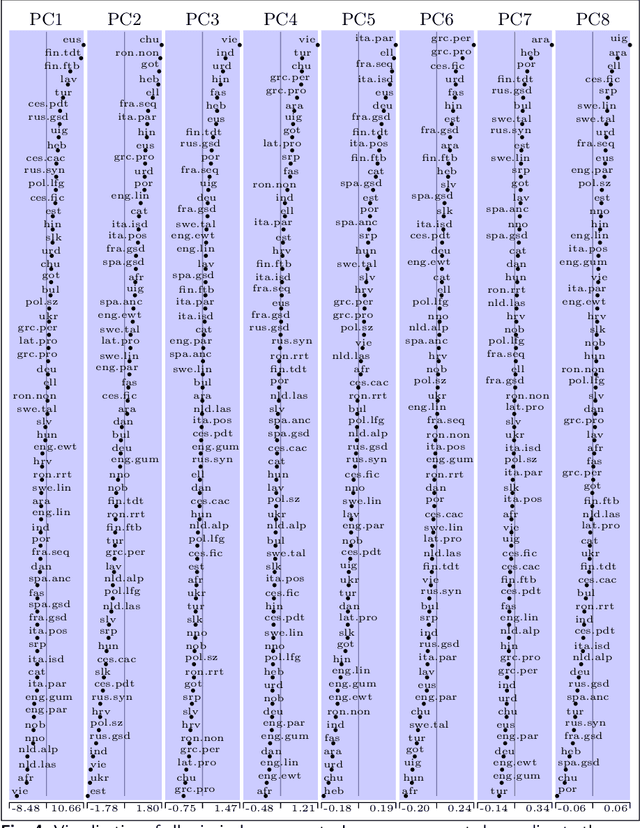
We present an analysis of eight measures used for quantifying morphological complexity of natural languages. The measures we study are corpus-based measures of morphological complexity with varying requirements for corpus annotation. We present similarities and differences between these measures visually and through correlation analyses, as well as their relation to the relevant typological variables. Our analysis focuses on whether these `measures' are measures of the same underlying variable, or whether they measure more than one dimension of morphological complexity. The principal component analysis indicates that the first principal component explains 92.62 % of the variation in eight measures, indicating a strong linear dependence between the complexity measures studied.
Are pre-trained text representations useful for multilingual and multi-dimensional language proficiency modeling?
Feb 25, 2021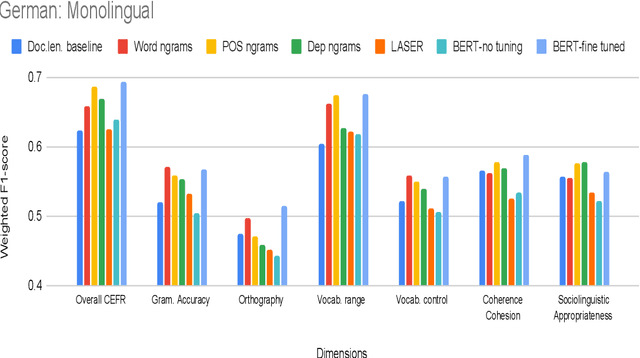
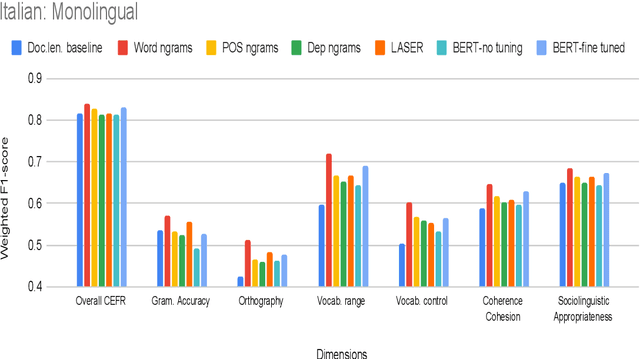
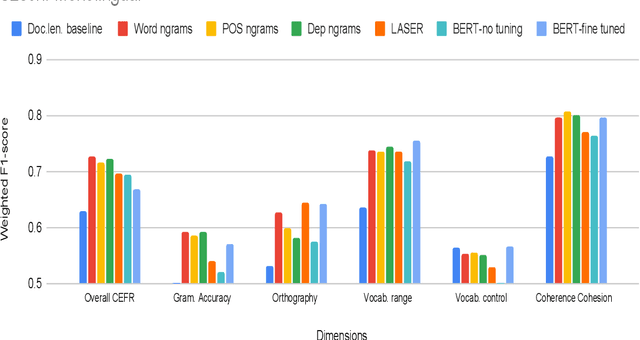
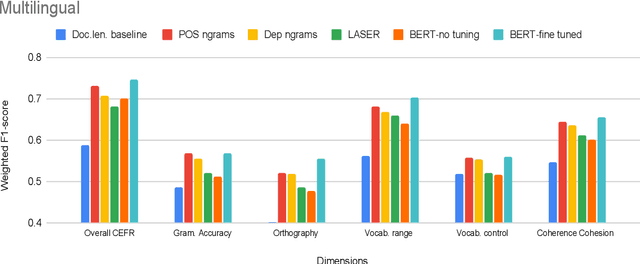
Development of language proficiency models for non-native learners has been an active area of interest in NLP research for the past few years. Although language proficiency is multidimensional in nature, existing research typically considers a single "overall proficiency" while building models. Further, existing approaches also considers only one language at a time. This paper describes our experiments and observations about the role of pre-trained and fine-tuned multilingual embeddings in performing multi-dimensional, multilingual language proficiency classification. We report experiments with three languages -- German, Italian, and Czech -- and model seven dimensions of proficiency ranging from vocabulary control to sociolinguistic appropriateness. Our results indicate that while fine-tuned embeddings are useful for multilingual proficiency modeling, none of the features achieve consistently best performance for all dimensions of language proficiency. All code, data and related supplementary material can be found at: https://github.com/nishkalavallabhi/MultidimCEFRScoring.
Probing Multilingual BERT for Genetic and Typological Signals
Nov 04, 2020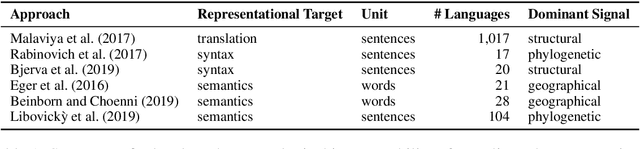
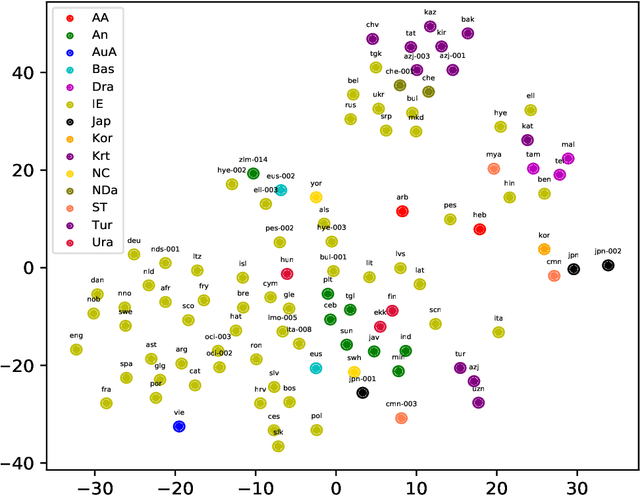
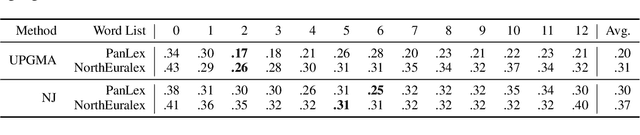
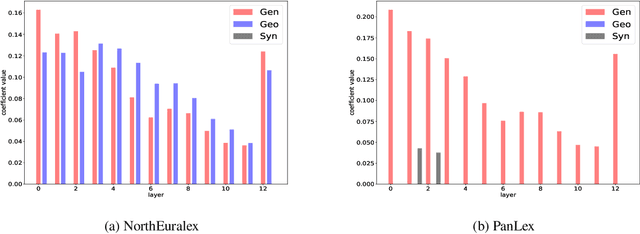
We probe the layers in multilingual BERT (mBERT) for phylogenetic and geographic language signals across 100 languages and compute language distances based on the mBERT representations. We 1) employ the language distances to infer and evaluate language trees, finding that they are close to the reference family tree in terms of quartet tree distance, 2) perform distance matrix regression analysis, finding that the language distances can be best explained by phylogenetic and worst by structural factors and 3) present a novel measure for measuring diachronic meaning stability (based on cross-lingual representation variability) which correlates significantly with published ranked lists based on linguistic approaches. Our results contribute to the nascent field of typological interpretability of cross-lingual text representations.
Tübingen-Oslo system: Linear regression works the best at Predicting Current and Future Psychological Health from Childhood Essays in the CLPsych 2018 Shared Task
Sep 13, 2018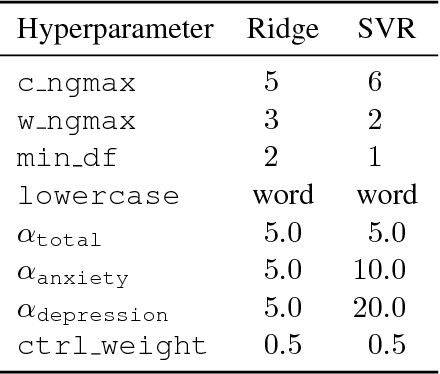
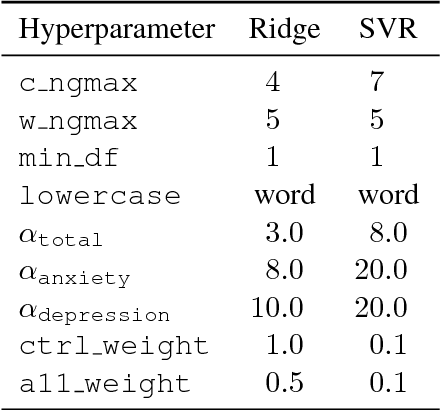
This paper describes our efforts in predicting current and future psychological health from childhood essays within the scope of the CLPsych-2018 Shared Task. We experimented with a number of different models, including recurrent and convolutional networks, Poisson regression, support vector regression, and L1 and L2 regularized linear regression. We obtained the best results on the training/development data with L2 regularized linear regression (ridge regression) which also got the best scores on main metrics in the official testing for task A (predicting psychological health from essays written at the age of 11 years) and task B (predicting later psychological health from essays written at the age of 11).
Three tree priors and five datasets: A study of the effect of tree priors in Indo-European phylogenetics
May 09, 2018
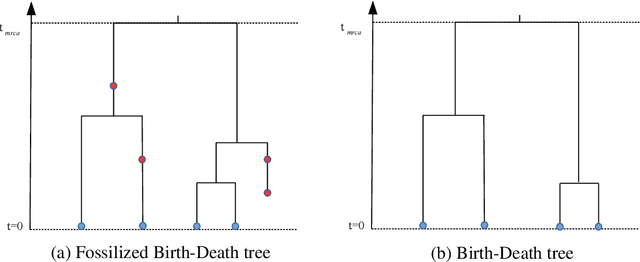
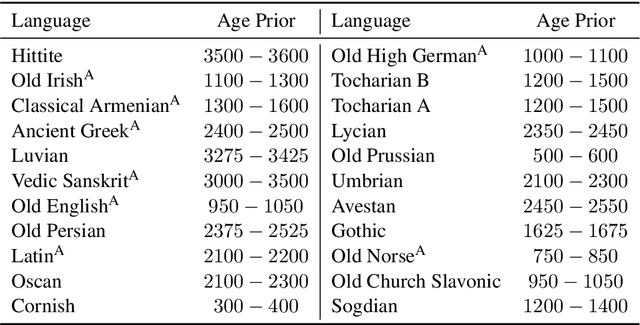

The age of the root of the Indo-European language family has received much attention since the application of Bayesian phylogenetic methods by Gray and Atkinson(2003). The root age of the Indo-European family has tended to decrease from an age that supported the Anatolian origin hypothesis to an age that supports the Steppe origin hypothesis with the application of new models (Chang et al., 2015). However, none of the published work in the Indo-European phylogenetics studied the effect of tree priors on phylogenetic analyses of the Indo-European family. In this paper, I intend to fill this gap by exploring the effect of tree priors on different aspects of the Indo-European family's phylogenetic inference. I apply three tree priors---Uniform, Fossilized Birth-Death (FBD), and Coalescent---to five publicly available datasets of the Indo-European language family. I evaluate the posterior distribution of the trees from the Bayesian analysis using Bayes Factor, and find that there is support for the Steppe origin hypothesis in the case of two tree priors. I report the median and 95% highest posterior density (HPD) interval of the root ages for all the three tree priors. A model comparison suggested that either Uniform prior or FBD prior is more suitable than the Coalescent prior to the datasets belonging to the Indo-European language family.
Experiments with Universal CEFR Classification
Apr 18, 2018


The Common European Framework of Reference (CEFR) guidelines describe language proficiency of learners on a scale of 6 levels. While the description of CEFR guidelines is generic across languages, the development of automated proficiency classification systems for different languages follow different approaches. In this paper, we explore universal CEFR classification using domain-specific and domain-agnostic, theory-guided as well as data-driven features. We report the results of our preliminary experiments in monolingual, cross-lingual, and multilingual classification with three languages: German, Czech, and Italian. Our results show that both monolingual and multilingual models achieve similar performance, and cross-lingual classification yields lower, but comparable results to monolingual classification.
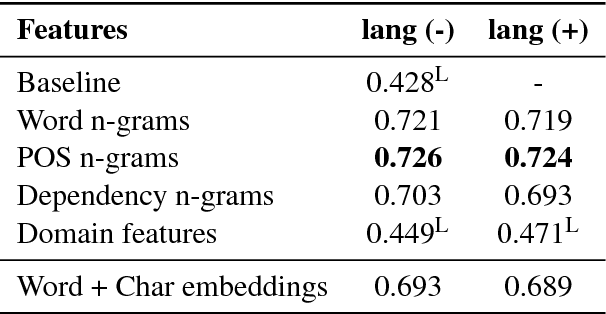
Are Automatic Methods for Cognate Detection Good Enough for Phylogenetic Reconstruction in Historical Linguistics?
Apr 15, 2018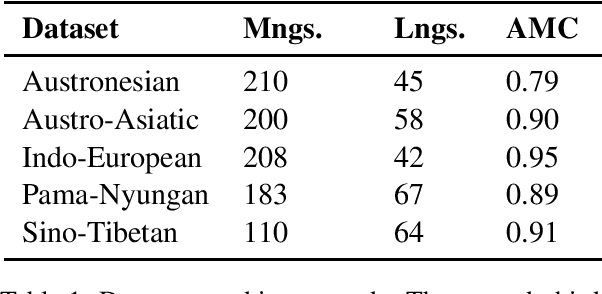
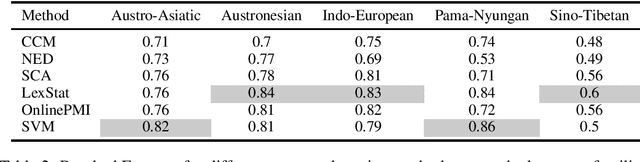
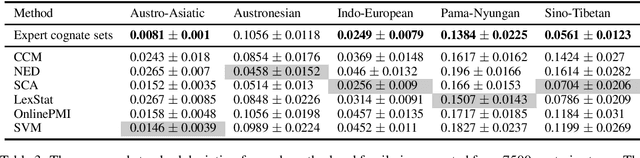
We evaluate the performance of state-of-the-art algorithms for automatic cognate detection by comparing how useful automatically inferred cognates are for the task of phylogenetic inference compared to classical manually annotated cognate sets. Our findings suggest that phylogenies inferred from automated cognate sets come close to phylogenies inferred from expert-annotated ones, although on average, the latter are still superior. We conclude that future work on phylogenetic reconstruction can profit much from automatic cognate detection. Especially where scholars are merely interested in exploring the bigger picture of a language family's phylogeny, algorithms for automatic cognate detection are a useful complement for current research on language phylogenies.
Fast and unsupervised methods for multilingual cognate clustering
Feb 16, 2017
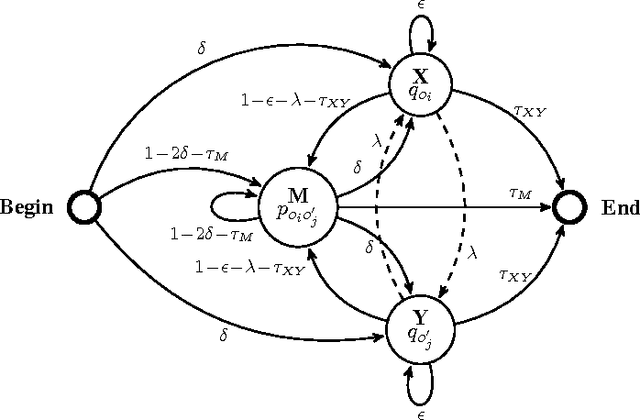
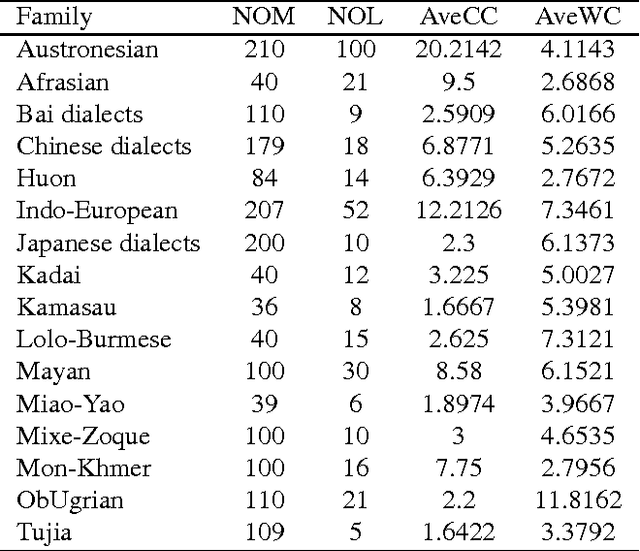
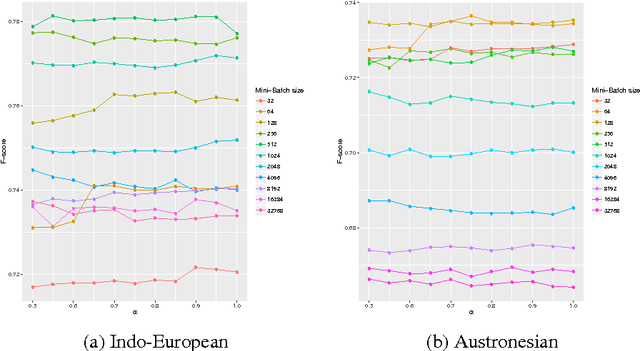
In this paper we explore the use of unsupervised methods for detecting cognates in multilingual word lists. We use online EM to train sound segment similarity weights for computing similarity between two words. We tested our online systems on geographically spread sixteen different language groups of the world and show that the Online PMI system (Pointwise Mutual Information) outperforms a HMM based system and two linguistically motivated systems: LexStat and ALINE. Our results suggest that a PMI system trained in an online fashion can be used by historical linguists for fast and accurate identification of cognates in not so well-studied language families.