 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Cognate Data Bottleneck in Language Phylogenetics
Jul 01, 2025To fully exploit the potential of computational phylogenetic methods for cognate data one needs to leverage specific (complex) models an machine learning-based techniques. However, both approaches require datasets that are substantially larger than the manually collected cognate data currently available. To the best of our knowledge, there exists no feasible approach to automatically generate larger cognate datasets. We substantiate this claim by automatically extracting datasets from BabelNet, a large multilingual encyclopedic dictionary. We demonstrate that phylogenetic inferences on the respective character matrices yield trees that are largely inconsistent with the established gold standard ground truth trees. We also discuss why we consider it as being unlikely to be able to extract more suitable character matrices from other multilingual resources. Phylogenetic data analysis approaches that require larger datasets can therefore not be applied to cognate data. Thus, it remains an open question how, and if these computational approaches can be applied in historical linguistics.
Computational Approaches for Integrating out Subjectivity in Cognate Synonym Selection
Apr 30, 2024
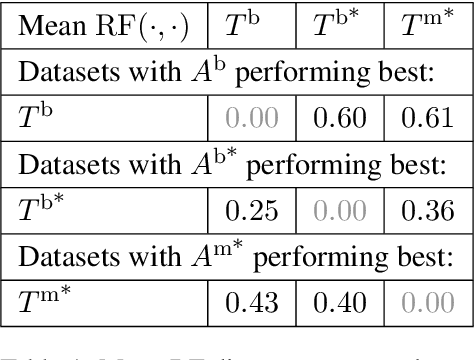
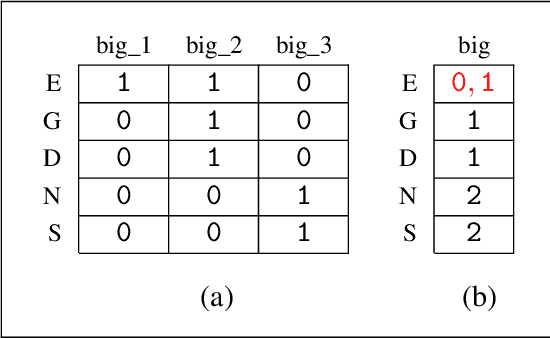
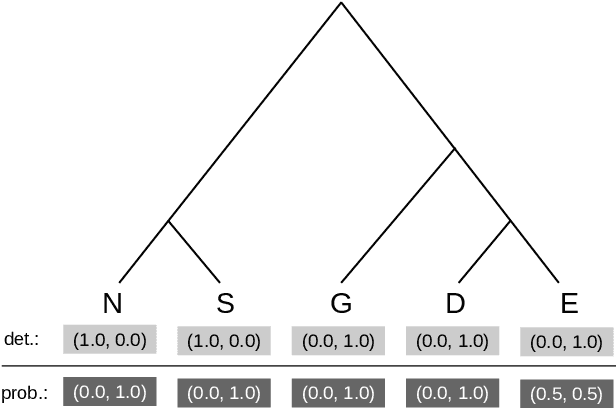
Working with cognate data involves handling synonyms, that is, multiple words that describe the same concept in a language. In the early days of language phylogenetics it was recommended to select one synonym only. However, as we show here, binary character matrices, which are used as input for computational methods, do allow for representing the entire dataset including all synonyms. Here we address the question how one can and if one should include all synonyms or whether it is preferable to select synonyms a priori. To this end, we perform maximum likelihood tree inferences with the widely used RAxML-NG tool and show that it yields plausible trees when all synonyms are used as input. Furthermore, we show that a priori synonym selection can yield topologically substantially different trees and we therefore advise against doing so. To represent cognate data including all synonyms, we introduce two types of character matrices beyond the standard binary ones: probabilistic binary and probabilistic multi-valued character matrices. We further show that it is dataset-dependent for which character matrix type the inferred RAxML-NG tree is topologically closest to the gold standard. We also make available a Python interface for generating all of the above character matrix types for cognate data provided in CLDF format.
Are Sounds Sound for Phylogenetic Reconstruction?
Feb 05, 2024



In traditional studies on language evolution, scholars often emphasize the importance of sound laws and sound correspondences for phylogenetic inference of language family trees. However, to date, computational approaches have typically not taken this potential into account. Most computational studies still rely on lexical cognates as major data source for phylogenetic reconstruction in linguistics, although there do exist a few studies in which authors praise the benefits of comparing words at the level of sound sequences. Building on (a) ten diverse datasets from different language families, and (b) state-of-the-art methods for automated cognate and sound correspondence detection, we test, for the first time, the performance of sound-based versus cognate-based approaches to phylogenetic reconstruction. Our results show that phylogenies reconstructed from lexical cognates are topologically closer, by approximately one third with respect to the generalized quartet distance on average, to the gold standard phylogenies than phylogenies reconstructed from sound correspondences.