 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputational Approaches for Integrating out Subjectivity in Cognate Synonym Selection
Paper and Code

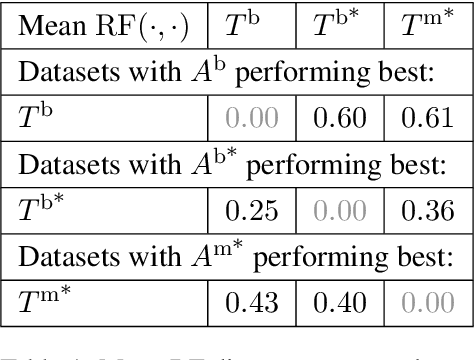
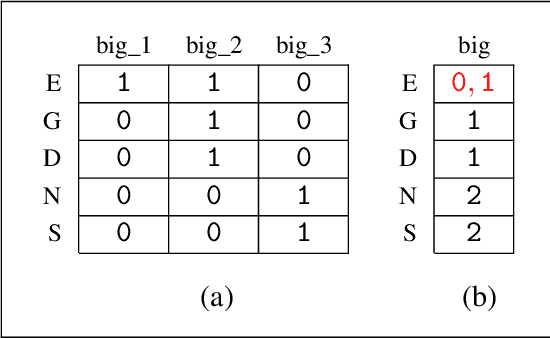
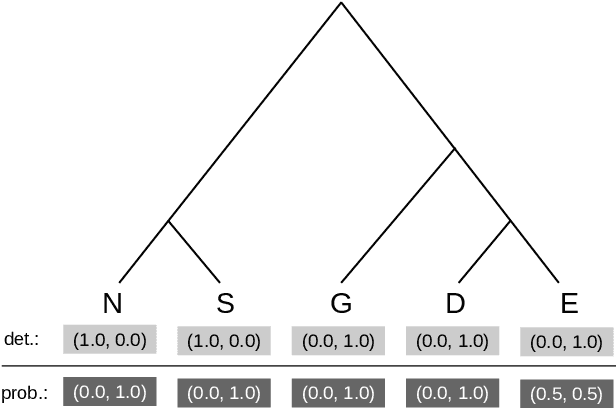
Working with cognate data involves handling synonyms, that is, multiple words that describe the same concept in a language. In the early days of language phylogenetics it was recommended to select one synonym only. However, as we show here, binary character matrices, which are used as input for computational methods, do allow for representing the entire dataset including all synonyms. Here we address the question how one can and if one should include all synonyms or whether it is preferable to select synonyms a priori. To this end, we perform maximum likelihood tree inferences with the widely used RAxML-NG tool and show that it yields plausible trees when all synonyms are used as input. Furthermore, we show that a priori synonym selection can yield topologically substantially different trees and we therefore advise against doing so. To represent cognate data including all synonyms, we introduce two types of character matrices beyond the standard binary ones: probabilistic binary and probabilistic multi-valued character matrices. We further show that it is dataset-dependent for which character matrix type the inferred RAxML-NG tree is topologically closest to the gold standard. We also make available a Python interface for generating all of the above character matrix types for cognate data provided in CLDF format.