 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputational Typology
Apr 22, 2025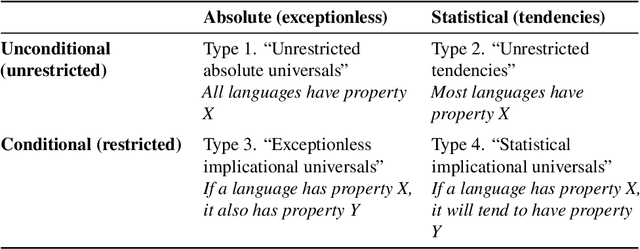
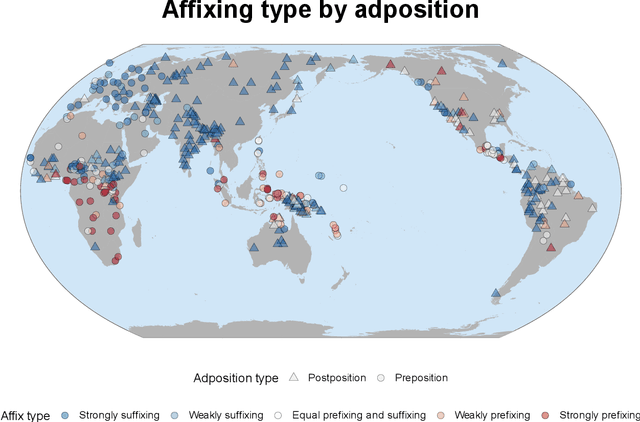

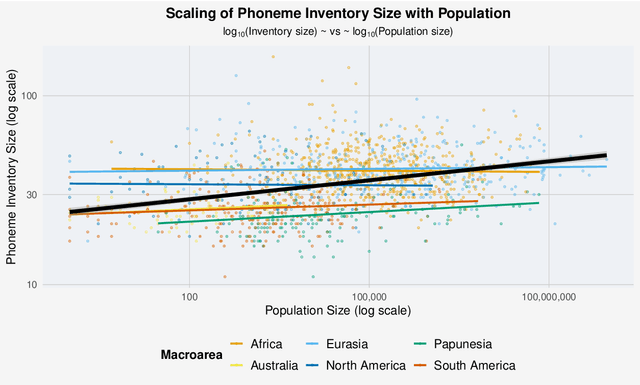
Typology is a subfield of linguistics that focuses on the study and classification of languages based on their structural features. Unlike genealogical classification, which examines the historical relationships between languages, typology seeks to understand the diversity of human languages by identifying common properties and patterns, known as universals. In recent years, computational methods have played an increasingly important role in typological research, enabling the analysis of large-scale linguistic data and the testing of hypotheses about language structure and evolution. This article provides an illustration of the benefits of computational statistical modeling in typology.
Computational Approaches for Integrating out Subjectivity in Cognate Synonym Selection
Apr 30, 2024
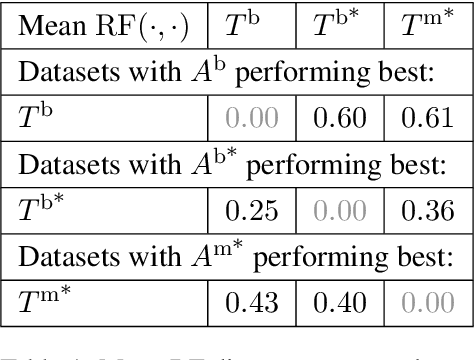
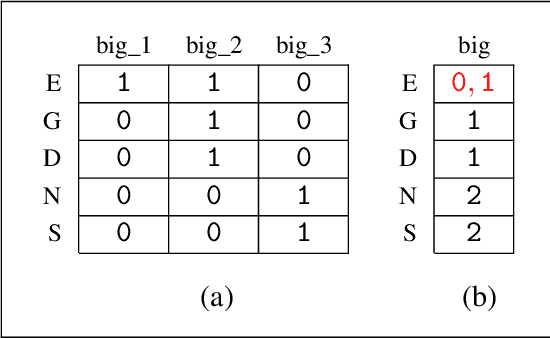
Working with cognate data involves handling synonyms, that is, multiple words that describe the same concept in a language. In the early days of language phylogenetics it was recommended to select one synonym only. However, as we show here, binary character matrices, which are used as input for computational methods, do allow for representing the entire dataset including all synonyms. Here we address the question how one can and if one should include all synonyms or whether it is preferable to select synonyms a priori. To this end, we perform maximum likelihood tree inferences with the widely used RAxML-NG tool and show that it yields plausible trees when all synonyms are used as input. Furthermore, we show that a priori synonym selection can yield topologically substantially different trees and we therefore advise against doing so. To represent cognate data including all synonyms, we introduce two types of character matrices beyond the standard binary ones: probabilistic binary and probabilistic multi-valued character matrices. We further show that it is dataset-dependent for which character matrix type the inferred RAxML-NG tree is topologically closest to the gold standard. We also make available a Python interface for generating all of the above character matrix types for cognate data provided in CLDF format.
Are Sounds Sound for Phylogenetic Reconstruction?
Feb 05, 2024



In traditional studies on language evolution, scholars often emphasize the importance of sound laws and sound correspondences for phylogenetic inference of language family trees. However, to date, computational approaches have typically not taken this potential into account. Most computational studies still rely on lexical cognates as major data source for phylogenetic reconstruction in linguistics, although there do exist a few studies in which authors praise the benefits of comparing words at the level of sound sequences. Building on (a) ten diverse datasets from different language families, and (b) state-of-the-art methods for automated cognate and sound correspondence detection, we test, for the first time, the performance of sound-based versus cognate-based approaches to phylogenetic reconstruction. Our results show that phylogenies reconstructed from lexical cognates are topologically closer, by approximately one third with respect to the generalized quartet distance on average, to the gold standard phylogenies than phylogenies reconstructed from sound correspondences.
Phylogenetic typology
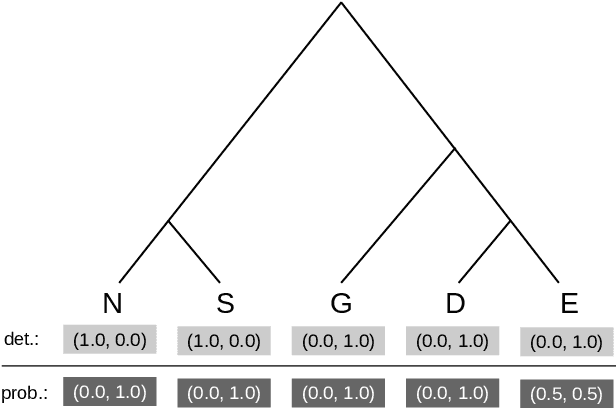
Mar 19, 2021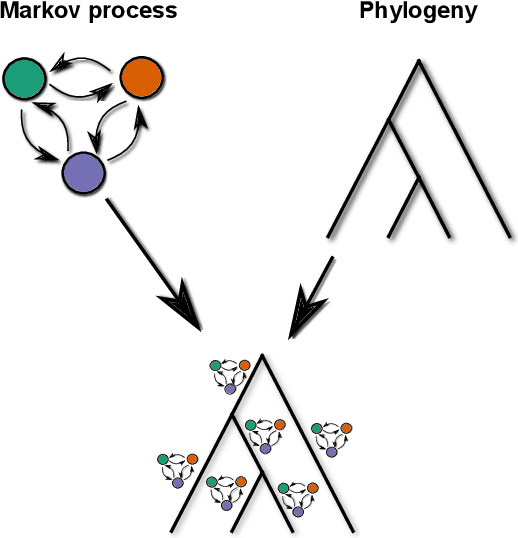
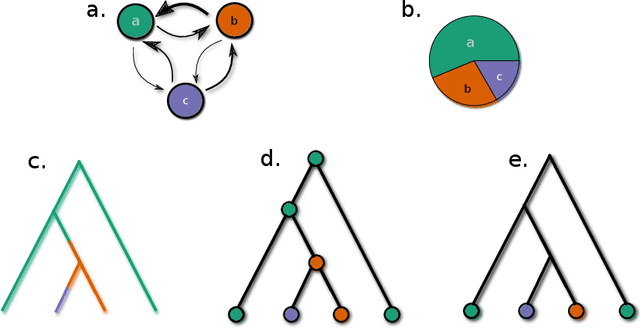
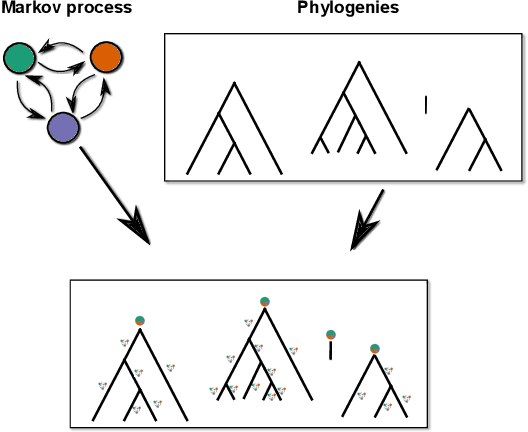
In this article we propose a novel method to estimate the frequency distribution of linguistic variables while controlling for statistical non-independence due to shared ancestry. Unlike previous approaches, our technique uses all available data, from language families large and small as well as from isolates, while controlling for different degrees of relatedness on a continuous scale estimated from the data. Our approach involves three steps: First, distributions of phylogenies are inferred from lexical data. Second, these phylogenies are used as part of a statistical model to statistically estimate transition rates between parameter states. Finally, the long-term equilibrium of the resulting Markov process is computed. As a case study, we investigate a series of potential word-order correlations across the languages of the world.
Computational Historical Linguistics
May 21, 2018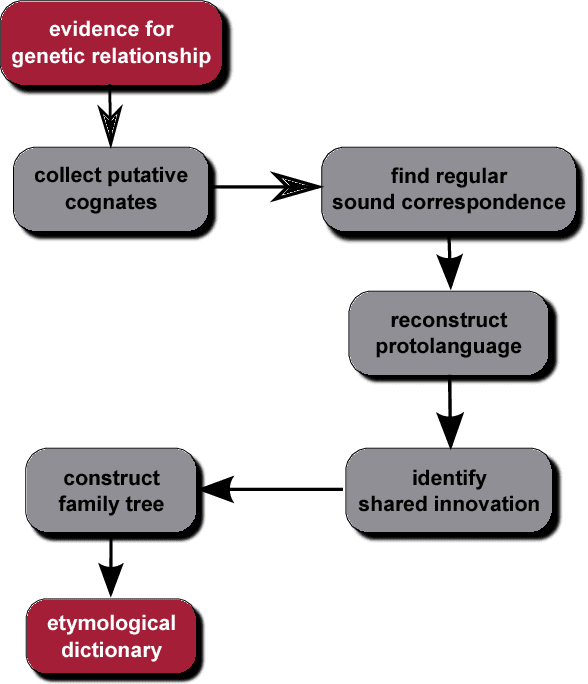
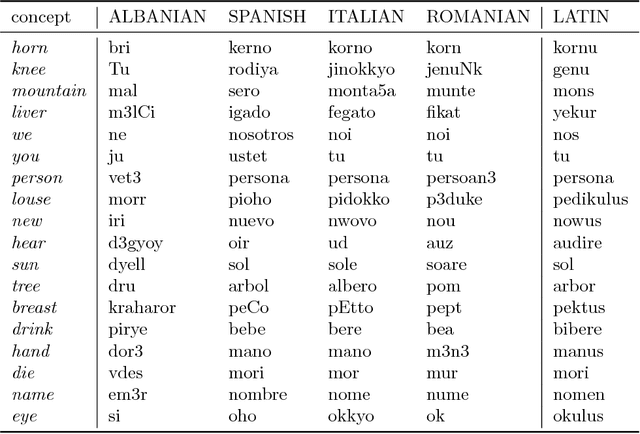

Computational approaches to historical linguistics have been proposed since half a century. Within the last decade, this line of research has received a major boost, owing both to the transfer of ideas and software from computational biology and to the release of several large electronic data resources suitable for systematic comparative work. In this article, some of the central research topic of this new wave of computational historical linguistics are introduced and discussed. These are automatic assessment of genetic relatedness, automatic cognate detection, phylogenetic inference and ancestral state reconstruction. They will be demonstrated by means of a case study of automatically reconstructing a Proto-Romance word list from lexical data of 50 modern Romance languages and dialects.
Are Automatic Methods for Cognate Detection Good Enough for Phylogenetic Reconstruction in Historical Linguistics?
Apr 15, 2018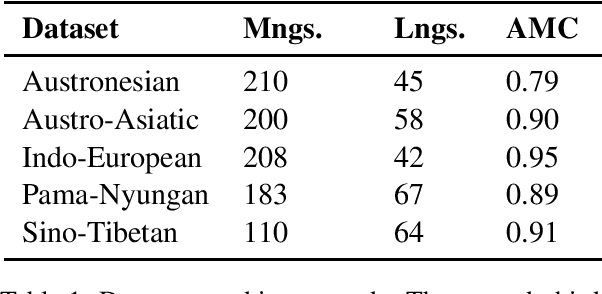
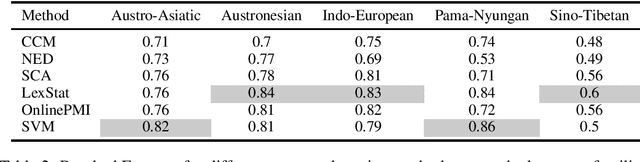
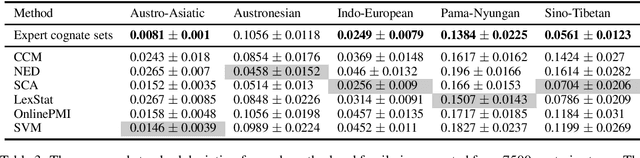
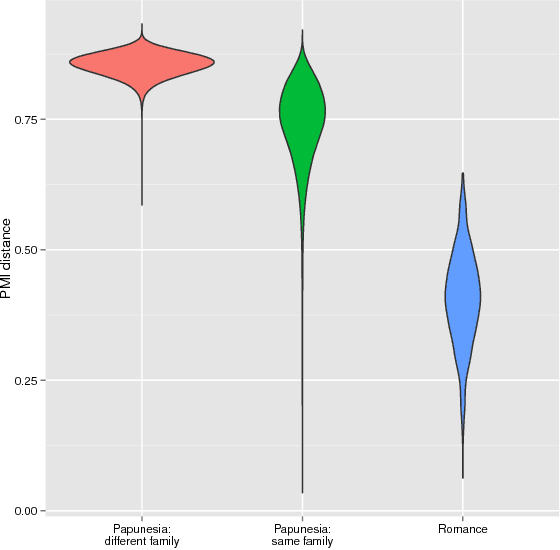
We evaluate the performance of state-of-the-art algorithms for automatic cognate detection by comparing how useful automatically inferred cognates are for the task of phylogenetic inference compared to classical manually annotated cognate sets. Our findings suggest that phylogenies inferred from automated cognate sets come close to phylogenies inferred from expert-annotated ones, although on average, the latter are still superior. We conclude that future work on phylogenetic reconstruction can profit much from automatic cognate detection. Especially where scholars are merely interested in exploring the bigger picture of a language family's phylogeny, algorithms for automatic cognate detection are a useful complement for current research on language phylogenies.
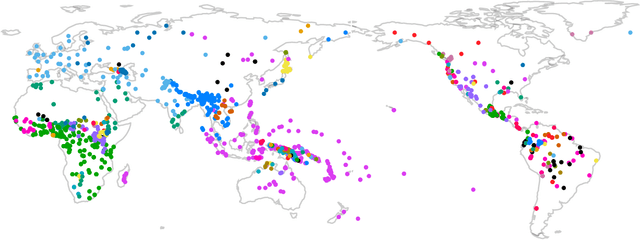
Global-scale phylogenetic linguistic inference from lexical resources
Feb 17, 2018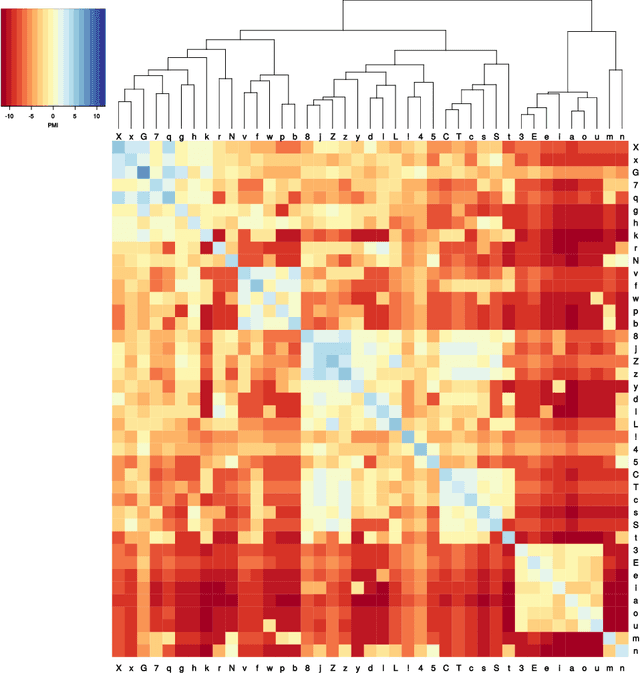
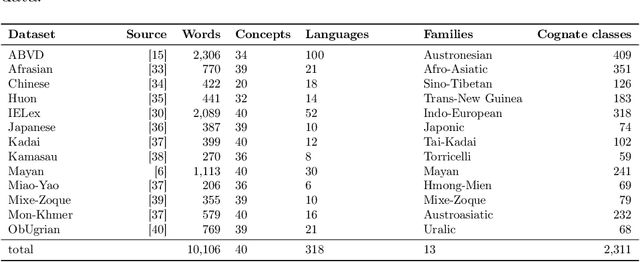
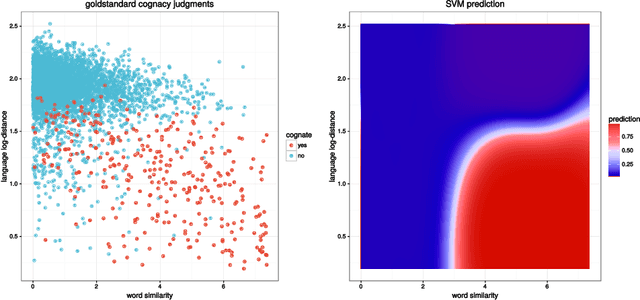
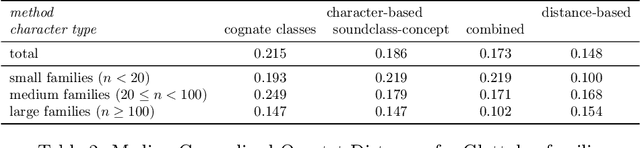
Automatic phylogenetic inference plays an increasingly important role in computational historical linguistics. Most pertinent work is currently based on expert cognate judgments. This limits the scope of this approach to a small number of well-studied language families. We used machine learning techniques to compile data suitable for phylogenetic inference from the ASJP database, a collection of almost 7,000 phonetically transcribed word lists over 40 concepts, covering two third of the extant world-wide linguistic diversity. First, we estimated Pointwise Mutual Information scores between sound classes using weighted sequence alignment and general-purpose optimization. From this we computed a dissimilarity matrix over all ASJP word lists. This matrix is suitable for distance-based phylogenetic inference. Second, we applied cognate clustering to the ASJP data, using supervised training of an SVM classifier on expert cognacy judgments. Third, we defined two types of binary characters, based on automatically inferred cognate classes and on sound-class occurrences. Several tests are reported demonstrating the suitability of these characters for character-based phylogenetic inference.
Fast and unsupervised methods for multilingual cognate clustering
Feb 16, 2017
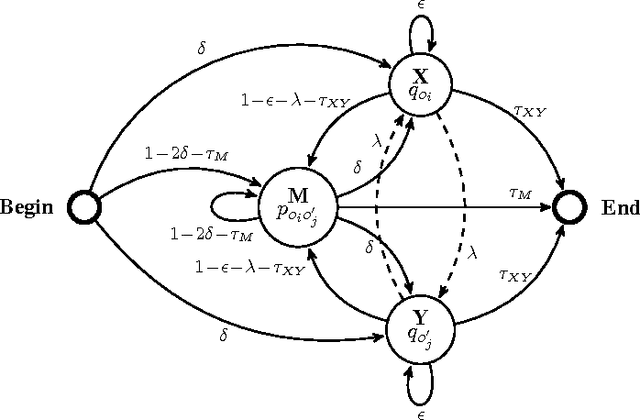
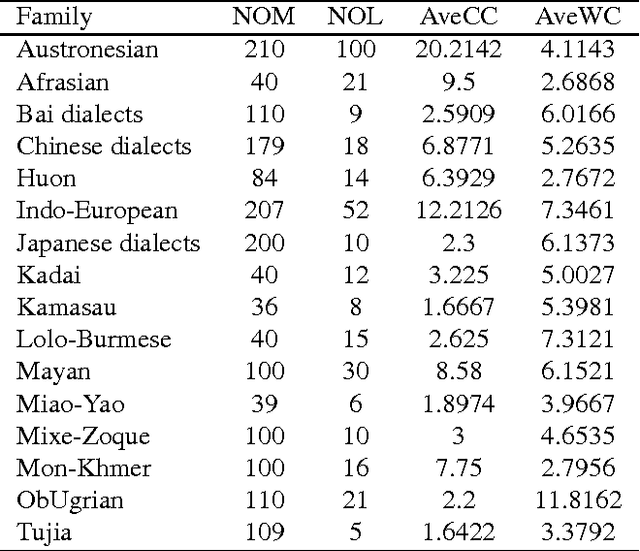
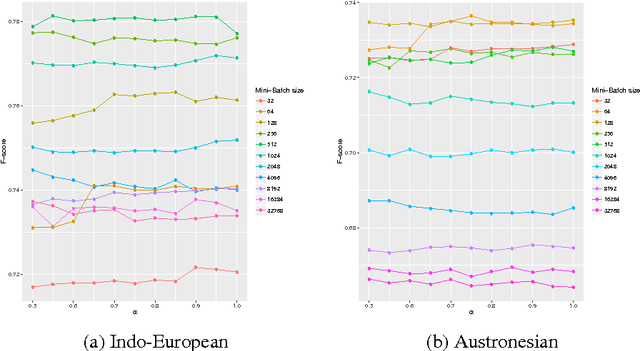
In this paper we explore the use of unsupervised methods for detecting cognates in multilingual word lists. We use online EM to train sound segment similarity weights for computing similarity between two words. We tested our online systems on geographically spread sixteen different language groups of the world and show that the Online PMI system (Pointwise Mutual Information) outperforms a HMM based system and two linguistically motivated systems: LexStat and ALINE. Our results suggest that a PMI system trained in an online fashion can be used by historical linguists for fast and accurate identification of cognates in not so well-studied language families.