 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal-scale phylogenetic linguistic inference from lexical resources
Paper and Code
Feb 17, 2018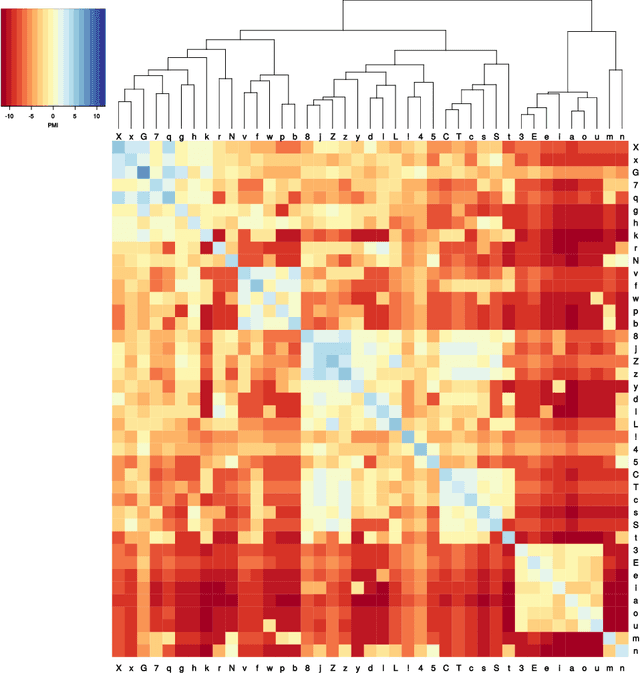
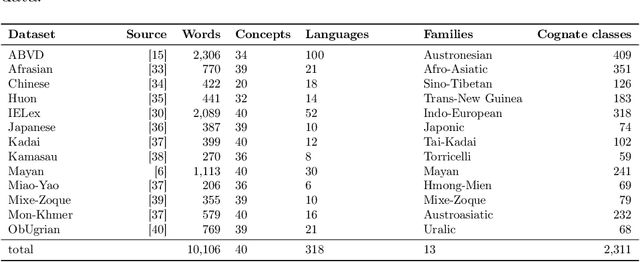
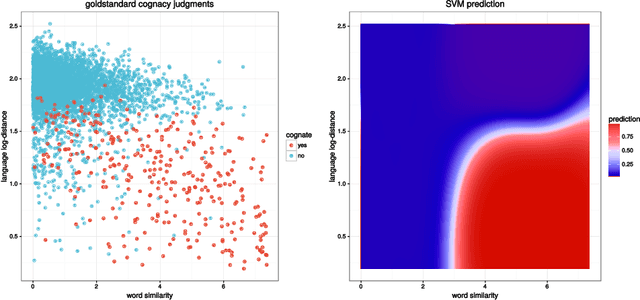
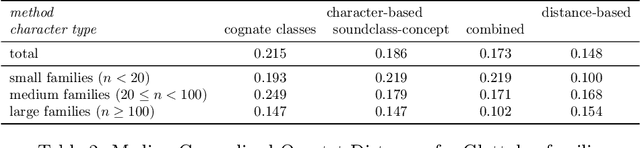
Automatic phylogenetic inference plays an increasingly important role in computational historical linguistics. Most pertinent work is currently based on expert cognate judgments. This limits the scope of this approach to a small number of well-studied language families. We used machine learning techniques to compile data suitable for phylogenetic inference from the ASJP database, a collection of almost 7,000 phonetically transcribed word lists over 40 concepts, covering two third of the extant world-wide linguistic diversity. First, we estimated Pointwise Mutual Information scores between sound classes using weighted sequence alignment and general-purpose optimization. From this we computed a dissimilarity matrix over all ASJP word lists. This matrix is suitable for distance-based phylogenetic inference. Second, we applied cognate clustering to the ASJP data, using supervised training of an SVM classifier on expert cognacy judgments. Third, we defined two types of binary characters, based on automatically inferred cognate classes and on sound-class occurrences. Several tests are reported demonstrating the suitability of these characters for character-based phylogenetic inference.