 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputational Historical Linguistics
Paper and Code
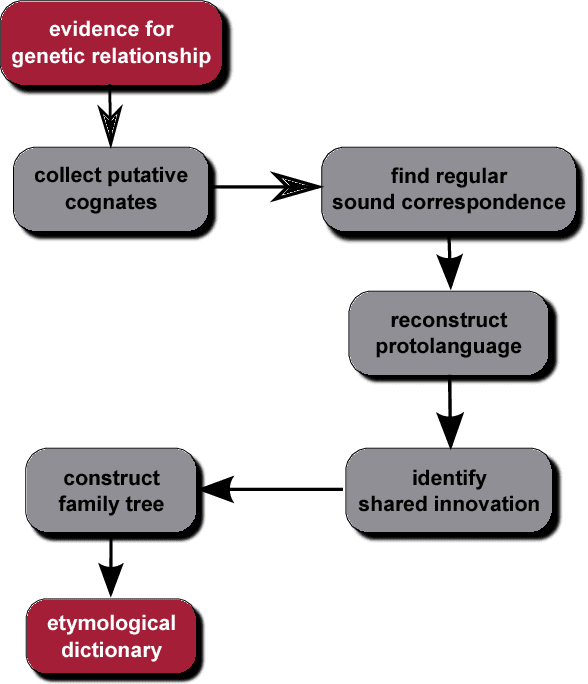
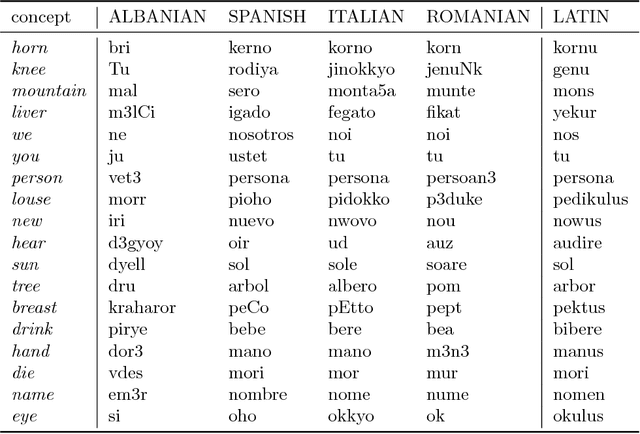
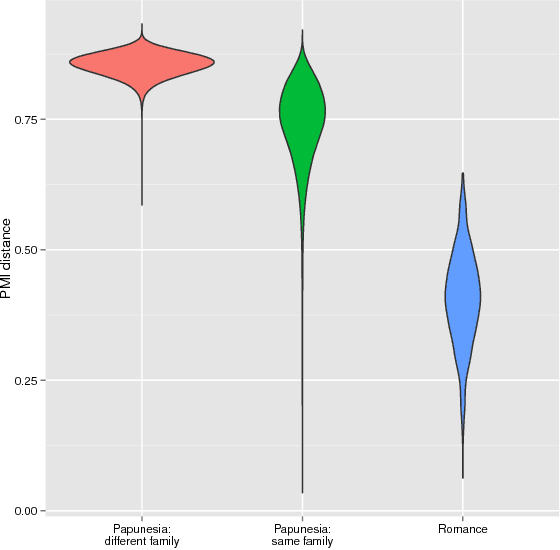

Computational approaches to historical linguistics have been proposed since half a century. Within the last decade, this line of research has received a major boost, owing both to the transfer of ideas and software from computational biology and to the release of several large electronic data resources suitable for systematic comparative work. In this article, some of the central research topic of this new wave of computational historical linguistics are introduced and discussed. These are automatic assessment of genetic relatedness, automatic cognate detection, phylogenetic inference and ancestral state reconstruction. They will be demonstrated by means of a case study of automatically reconstructing a Proto-Romance word list from lexical data of 50 modern Romance languages and dialects.