 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproaching Peak Ground Truth
Dec 31, 2022

Machine learning models are typically evaluated by computing similarity with reference annotations and trained by maximizing similarity with such. Especially in the bio-medical domain, annotations are subjective and suffer from low inter- and intra-rater reliability. Since annotations only reflect the annotation entity's interpretation of the real world, this can lead to sub-optimal predictions even though the model achieves high similarity scores. Here, the theoretical concept of Peak Ground Truth (PGT) is introduced. PGT marks the point beyond which an increase in similarity with the reference annotation stops translating to better Real World Model Performance (RWMP). Additionally, a quantitative technique to approximate PGT by computing inter- and intra-rater reliability is proposed. Finally, three categories of PGT-aware strategies to evaluate and improve model performance are reviewed.
Phylogenetic typology
Mar 19, 2021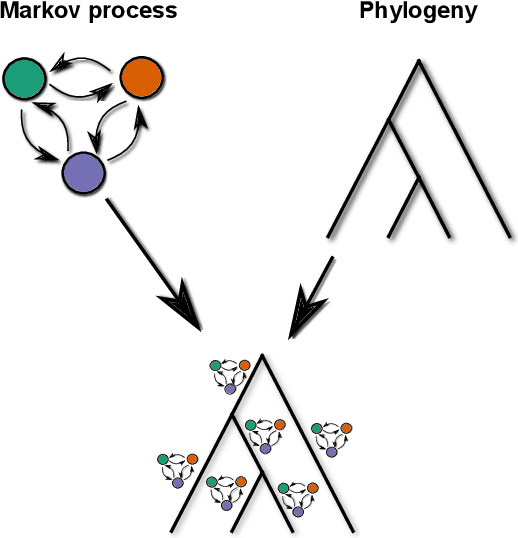
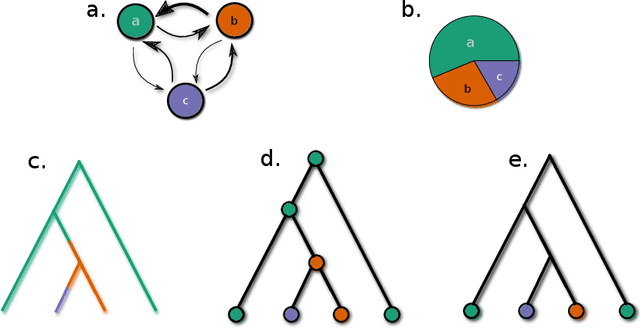
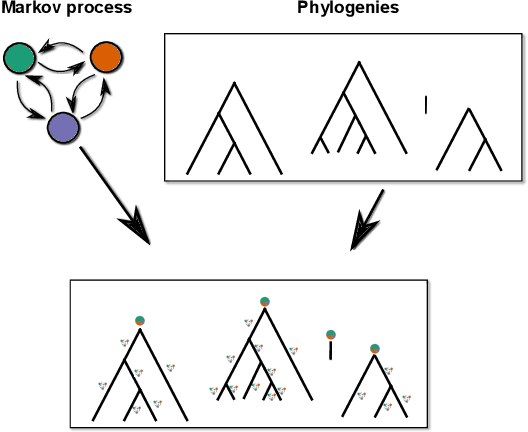
In this article we propose a novel method to estimate the frequency distribution of linguistic variables while controlling for statistical non-independence due to shared ancestry. Unlike previous approaches, our technique uses all available data, from language families large and small as well as from isolates, while controlling for different degrees of relatedness on a continuous scale estimated from the data. Our approach involves three steps: First, distributions of phylogenies are inferred from lexical data. Second, these phylogenies are used as part of a statistical model to statistically estimate transition rates between parameter states. Finally, the long-term equilibrium of the resulting Markov process is computed. As a case study, we investigate a series of potential word-order correlations across the languages of the world.
Are Automatic Methods for Cognate Detection Good Enough for Phylogenetic Reconstruction in Historical Linguistics?
Apr 15, 2018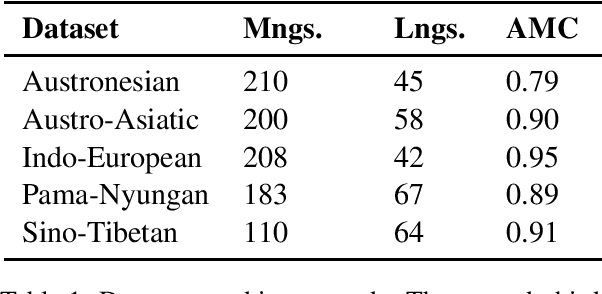
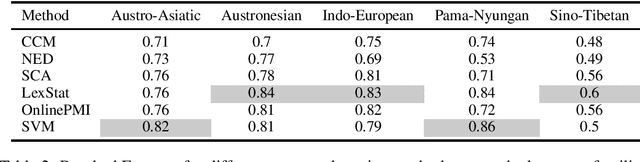
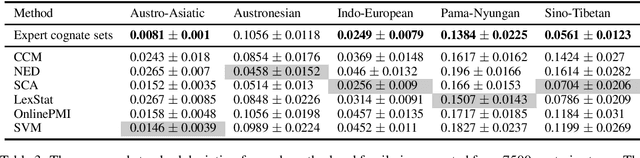
We evaluate the performance of state-of-the-art algorithms for automatic cognate detection by comparing how useful automatically inferred cognates are for the task of phylogenetic inference compared to classical manually annotated cognate sets. Our findings suggest that phylogenies inferred from automated cognate sets come close to phylogenies inferred from expert-annotated ones, although on average, the latter are still superior. We conclude that future work on phylogenetic reconstruction can profit much from automatic cognate detection. Especially where scholars are merely interested in exploring the bigger picture of a language family's phylogeny, algorithms for automatic cognate detection are a useful complement for current research on language phylogenies.
Fast and unsupervised methods for multilingual cognate clustering
Feb 16, 2017
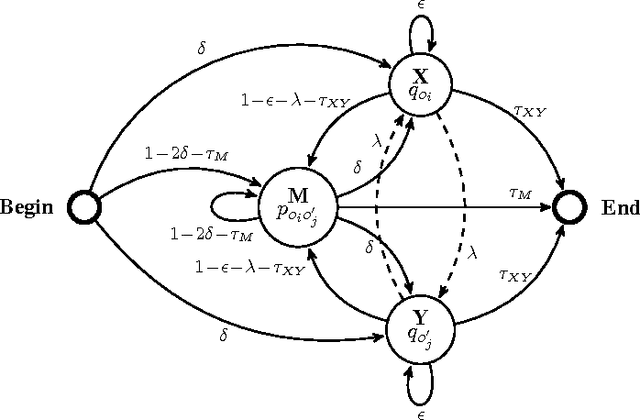
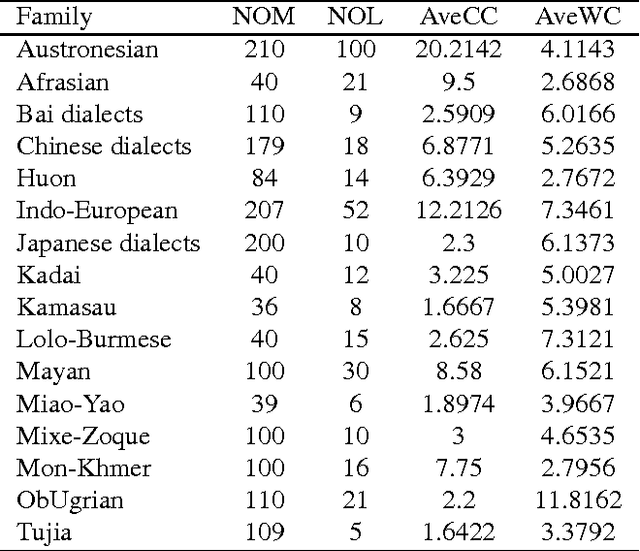
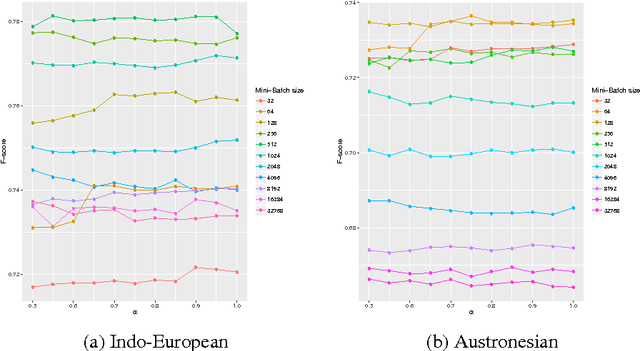
In this paper we explore the use of unsupervised methods for detecting cognates in multilingual word lists. We use online EM to train sound segment similarity weights for computing similarity between two words. We tested our online systems on geographically spread sixteen different language groups of the world and show that the Online PMI system (Pointwise Mutual Information) outperforms a HMM based system and two linguistically motivated systems: LexStat and ALINE. Our results suggest that a PMI system trained in an online fashion can be used by historical linguists for fast and accurate identification of cognates in not so well-studied language families.