 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat makes a word hard to learn? Modeling L1 influence on English vocabulary difficulty
May 12, 2026What makes a word difficult to learn, and how does the difficulty depend on the learner's native language? We computationally model vocabulary difficulty for English learners whose first language is Spanish, German, or Chinese with gradient-boosted models trained on features related to a word's familiarity (e.g., frequency), meaning, surface form, and cross-linguistic transfer. Using Shapley values, we determine the importance of each feature group. Word familiarity is the dominant feature group shared by all three languages. However, predictions for Spanish- and German-speaking learners rely additionally on orthographic transfer. This transfer mechanism is unavailable to Chinese learners, whose difficulty is shaped by a combination of familiarity and surface features alone. Our models provide interpretable, L1-tailored difficulty estimates that can be used to design vocabulary curricula.
Vocabulary shapes cross-lingual variation of word-order learnability in language models
Mar 19, 2026Why do some languages like Czech permit free word order, while others like English do not? We address this question by pretraining transformer language models on a spectrum of synthetic word-order variants of natural languages. We observe that greater word-order irregularity consistently raises model surprisal, indicating reduced learnability. Sentence reversal, however, affects learnability only weakly. A coarse distinction of free- (e.g., Czech and Finnish) and fixed-word-order languages (e.g., English and French) does not explain cross-lingual variation. Instead, the structure of the word and subword vocabulary strongly predicts the model surprisal. Overall, vocabulary structure emerges as a key driver of computational word-order learnability across languages.
Once Upon a Time: Interactive Learning for Storytelling with Small Language Models
Sep 19, 2025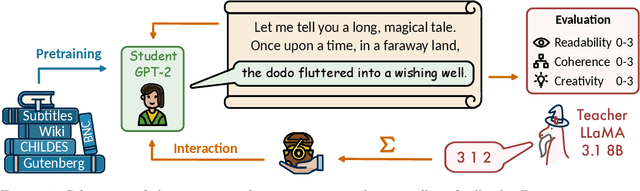
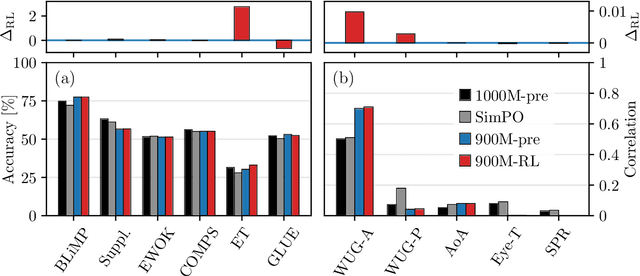
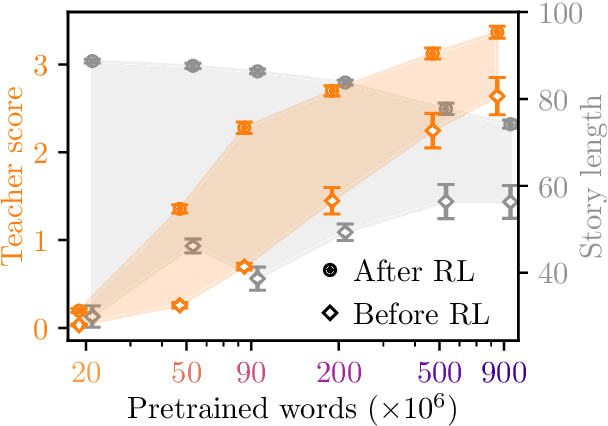
Children efficiently acquire language not just by listening, but by interacting with others in their social environment. Conversely, large language models are typically trained with next-word prediction on massive amounts of text. Motivated by this contrast, we investigate whether language models can be trained with less data by learning not only from next-word prediction but also from high-level, cognitively inspired feedback. We train a student model to generate stories, which a teacher model rates on readability, narrative coherence, and creativity. By varying the amount of pretraining before the feedback loop, we assess the impact of this interactive learning on formal and functional linguistic competence. We find that the high-level feedback is highly data efficient: With just 1 M words of input in interactive learning, storytelling skills can improve as much as with 410 M words of next-word prediction.
From Babble to Words: Pre-Training Language Models on Continuous Streams of Phonemes
Oct 30, 2024



Language models are typically trained on large corpora of text in their default orthographic form. However, this is not the only option; representing data as streams of phonemes can offer unique advantages, from deeper insights into phonological language acquisition to improved performance on sound-based tasks. The challenge lies in evaluating the impact of phoneme-based training, as most benchmarks are also orthographic. To address this, we develop a pipeline to convert text datasets into a continuous stream of phonemes. We apply this pipeline to the 100-million-word pre-training dataset from the BabyLM challenge, as well as to standard language and grammatical benchmarks, enabling us to pre-train and evaluate a model using phonemic input representations. Our results show that while phoneme-based training slightly reduces performance on traditional language understanding tasks, it offers valuable analytical and practical benefits.
Mitigating Frequency Bias and Anisotropy in Language Model Pre-Training with Syntactic Smoothing
Oct 15, 2024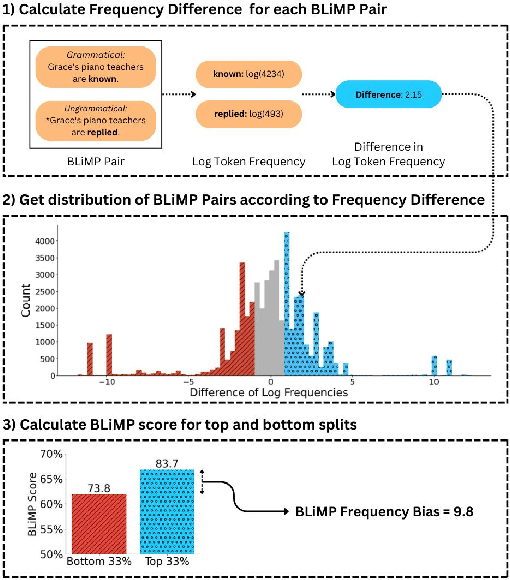



Language models strongly rely on frequency information because they maximize the likelihood of tokens during pre-training. As a consequence, language models tend to not generalize well to tokens that are seldom seen during training. Moreover, maximum likelihood training has been discovered to give rise to anisotropy: representations of tokens in a model tend to cluster tightly in a high-dimensional cone, rather than spreading out over their representational capacity. Our work introduces a method for quantifying the frequency bias of a language model by assessing sentence-level perplexity with respect to token-level frequency. We then present a method for reducing the frequency bias of a language model by inducing a syntactic prior over token representations during pre-training. Our Syntactic Smoothing method adjusts the maximum likelihood objective function to distribute the learning signal to syntactically similar tokens. This approach results in better performance on infrequent English tokens and a decrease in anisotropy. We empirically show that the degree of anisotropy in a model correlates with its frequency bias.
The Role of Syntactic Span Preferences in Post-Hoc Explanation Disagreement
Mar 28, 2024



Post-hoc explanation methods are an important tool for increasing model transparency for users. Unfortunately, the currently used methods for attributing token importance often yield diverging patterns. In this work, we study potential sources of disagreement across methods from a linguistic perspective. We find that different methods systematically select different classes of words and that methods that agree most with other methods and with humans display similar linguistic preferences. Token-level differences between methods are smoothed out if we compare them on the syntactic span level. We also find higher agreement across methods by estimating the most important spans dynamically instead of relying on a fixed subset of size $k$. We systematically investigate the interaction between $k$ and spans and propose an improved configuration for selecting important tokens.
CLIMB: Curriculum Learning for Infant-inspired Model Building
Nov 15, 2023



We describe our team's contribution to the STRICT-SMALL track of the BabyLM Challenge. The challenge requires training a language model from scratch using only a relatively small training dataset of ten million words. We experiment with three variants of cognitively-motivated curriculum learning and analyze their effect on the performance of the model on linguistic evaluation tasks. In the vocabulary curriculum, we analyze methods for constraining the vocabulary in the early stages of training to simulate cognitively more plausible learning curves. In the data curriculum experiments, we vary the order of the training instances based on i) infant-inspired expectations and ii) the learning behavior of the model. In the objective curriculum, we explore different variations of combining the conventional masked language modeling task with a more coarse-grained word class prediction task to reinforce linguistic generalization capabilities. Our results did not yield consistent improvements over our own non-curriculum learning baseline across a range of linguistic benchmarks; however, we do find marginal gains on select tasks. Our analysis highlights key takeaways for specific combinations of tasks and settings which benefit from our proposed curricula. We moreover determine that careful selection of model architecture, and training hyper-parameters yield substantial improvements over the default baselines provided by the BabyLM challenge.
Analyzing Cognitive Plausibility of Subword Tokenization
Oct 20, 2023Subword tokenization has become the de-facto standard for tokenization, although comparative evaluations of subword vocabulary quality across languages are scarce. Existing evaluation studies focus on the effect of a tokenization algorithm on the performance in downstream tasks, or on engineering criteria such as the compression rate. We present a new evaluation paradigm that focuses on the cognitive plausibility of subword tokenization. We analyze the correlation of the tokenizer output with the response time and accuracy of human performance on a lexical decision task. We compare three tokenization algorithms across several languages and vocabulary sizes. Our results indicate that the UnigramLM algorithm yields less cognitively plausible tokenization behavior and a worse coverage of derivational morphemes, in contrast with prior work.
Dynamic Top-k Estimation Consolidates Disagreement between Feature Attribution Methods
Oct 09, 2023Feature attribution scores are used for explaining the prediction of a text classifier to users by highlighting a k number of tokens. In this work, we propose a way to determine the number of optimal k tokens that should be displayed from sequential properties of the attribution scores. Our approach is dynamic across sentences, method-agnostic, and deals with sentence length bias. We compare agreement between multiple methods and humans on an NLI task, using fixed k and dynamic k. We find that perturbation-based methods and Vanilla Gradient exhibit highest agreement on most method--method and method--human agreement metrics with a static k. Their advantage over other methods disappears with dynamic ks which mainly improve Integrated Gradient and GradientXInput. To our knowledge, this is the first evidence that sequential properties of attribution scores are informative for consolidating attribution signals for human interpretation.
Cross-Lingual Transfer of Cognitive Processing Complexity
Feb 27, 2023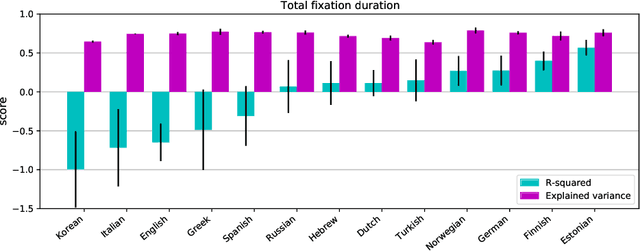
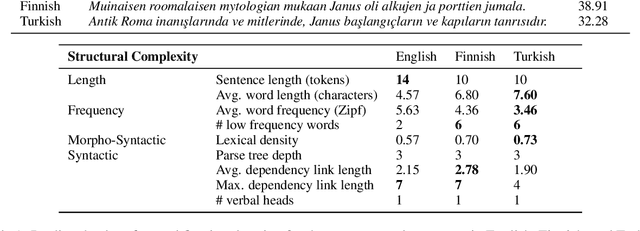
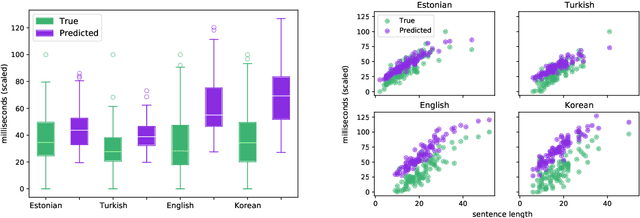
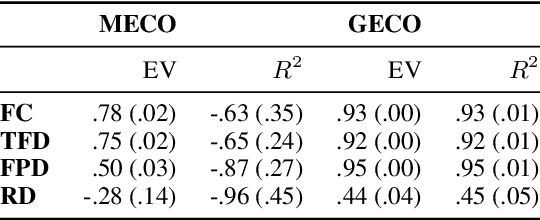
When humans read a text, their eye movements are influenced by the structural complexity of the input sentences. This cognitive phenomenon holds across languages and recent studies indicate that multilingual language models utilize structural similarities between languages to facilitate cross-lingual transfer. We use sentence-level eye-tracking patterns as a cognitive indicator for structural complexity and show that the multilingual model XLM-RoBERTa can successfully predict varied patterns for 13 typologically diverse languages, despite being fine-tuned only on English data. We quantify the sensitivity of the model to structural complexity and distinguish a range of complexity characteristics. Our results indicate that the model develops a meaningful bias towards sentence length but also integrates cross-lingual differences. We conduct a control experiment with randomized word order and find that the model seems to additionally capture more complex structural information.