 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplanation Bias is a Product: Revealing the Hidden Lexical and Position Preferences in Post-Hoc Feature Attribution
Dec 11, 2025Good quality explanations strengthen the understanding of language models and data. Feature attribution methods, such as Integrated Gradient, are a type of post-hoc explainer that can provide token-level insights. However, explanations on the same input may vary greatly due to underlying biases of different methods. Users may be aware of this issue and mistrust their utility, while unaware users may trust them inadequately. In this work, we delve beyond the superficial inconsistencies between attribution methods, structuring their biases through a model- and method-agnostic framework of three evaluation metrics. We systematically assess both the lexical and position bias (what and where in the input) for two transformers; first, in a controlled, pseudo-random classification task on artificial data; then, in a semi-controlled causal relation detection task on natural data. We find that lexical and position biases are structurally unbalanced in our model comparison, with models that score high on one type score low on the other. We also find signs that methods producing anomalous explanations are more likely to be biased themselves.
The Role of Syntactic Span Preferences in Post-Hoc Explanation Disagreement
Mar 28, 2024



Post-hoc explanation methods are an important tool for increasing model transparency for users. Unfortunately, the currently used methods for attributing token importance often yield diverging patterns. In this work, we study potential sources of disagreement across methods from a linguistic perspective. We find that different methods systematically select different classes of words and that methods that agree most with other methods and with humans display similar linguistic preferences. Token-level differences between methods are smoothed out if we compare them on the syntactic span level. We also find higher agreement across methods by estimating the most important spans dynamically instead of relying on a fixed subset of size $k$. We systematically investigate the interaction between $k$ and spans and propose an improved configuration for selecting important tokens.
Dynamic Top-k Estimation Consolidates Disagreement between Feature Attribution Methods
Oct 09, 2023Feature attribution scores are used for explaining the prediction of a text classifier to users by highlighting a k number of tokens. In this work, we propose a way to determine the number of optimal k tokens that should be displayed from sequential properties of the attribution scores. Our approach is dynamic across sentences, method-agnostic, and deals with sentence length bias. We compare agreement between multiple methods and humans on an NLI task, using fixed k and dynamic k. We find that perturbation-based methods and Vanilla Gradient exhibit highest agreement on most method--method and method--human agreement metrics with a static k. Their advantage over other methods disappears with dynamic ks which mainly improve Integrated Gradient and GradientXInput. To our knowledge, this is the first evidence that sequential properties of attribution scores are informative for consolidating attribution signals for human interpretation.
Perturbations and Subpopulations for Testing Robustness in Token-Based Argument Unit Recognition
Sep 29, 2022
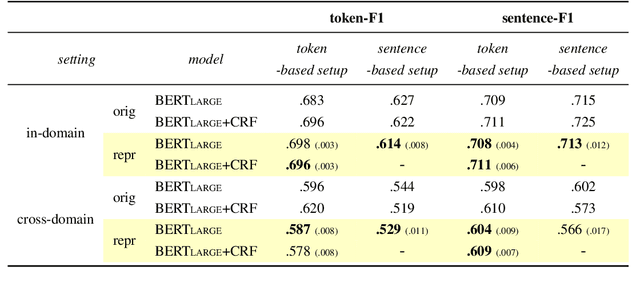

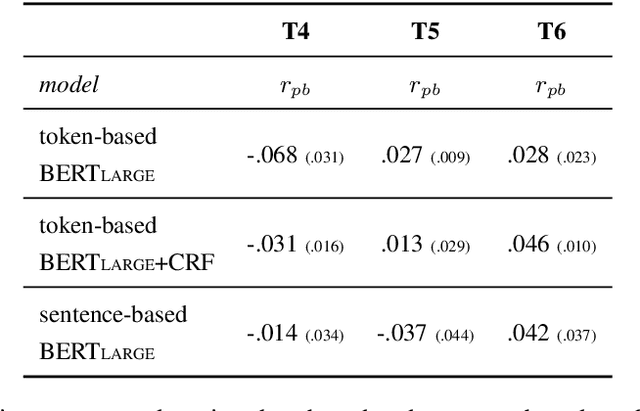
Argument Unit Recognition and Classification aims at identifying argument units from text and classifying them as pro or against. One of the design choices that need to be made when developing systems for this task is what the unit of classification should be: segments of tokens or full sentences. Previous research suggests that fine-tuning language models on the token-level yields more robust results for classifying sentences compared to training on sentences directly. We reproduce the study that originally made this claim and further investigate what exactly token-based systems learned better compared to sentence-based ones. We develop systematic tests for analysing the behavioural differences between the token-based and the sentence-based system. Our results show that token-based models are generally more robust than sentence-based models both on manually perturbed examples and on specific subpopulations of the data.